 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Predictive Modeling of Clinical Notes and ICD Codes in Patient Health Records
May 19, 2024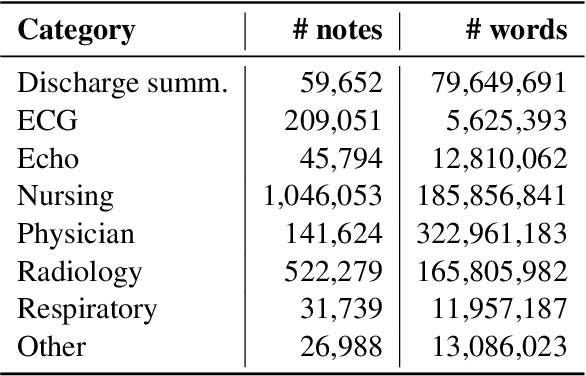
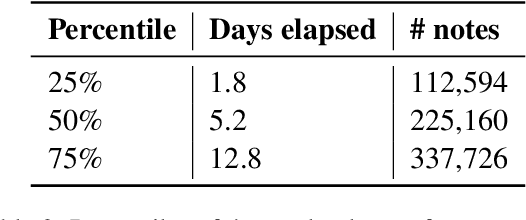
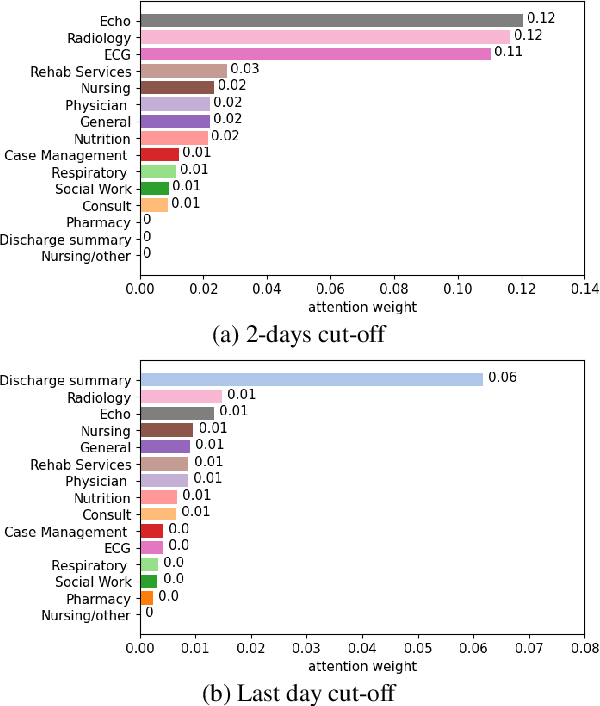
Electronic Health Records (EHR) serve as a valuable source of patient information, offering insights into medical histories, treatments, and outcomes. Previous research has developed systems for detecting applicable ICD codes that should be assigned while writing a given EHR document, mainly focusing on discharge summaries written at the end of a hospital stay. In this work, we investigate the potential of predicting these codes for the whole patient stay at different time points during their stay, even before they are officially assigned by clinicians. The development of methods to predict diagnoses and treatments earlier in advance could open opportunities for predictive medicine, such as identifying disease risks sooner, suggesting treatments, and optimizing resource allocation. Our experiments show that predictions regarding final ICD codes can be made already two days after admission and we propose a custom model that improves performance on this early prediction task.
Low-Cost Generation and Evaluation of Dictionary Example Sentences
Apr 09, 2024Dictionary example sentences play an important role in illustrating word definitions and usage, but manually creating quality sentences is challenging. Prior works have demonstrated that language models can be trained to generate example sentences. However, they relied on costly customized models and word sense datasets for generation and evaluation of their work. Rapid advancements in foundational models present the opportunity to create low-cost, zero-shot methods for the generation and evaluation of dictionary example sentences. We introduce a new automatic evaluation metric called OxfordEval that measures the win-rate of generated sentences against existing Oxford Dictionary sentences. OxfordEval shows high alignment with human judgments, enabling large-scale automated quality evaluation. We experiment with various LLMs and configurations to generate dictionary sentences across word classes. We complement this with a novel approach of using masked language models to identify and select sentences that best exemplify word meaning. The eventual model, FM-MLM, achieves over 85.1% win rate against Oxford baseline sentences according to OxfordEval, compared to 39.8% win rate for prior model-generated sentences.
Modelling Temporal Document Sequences for Clinical ICD Coding
Feb 24, 2023



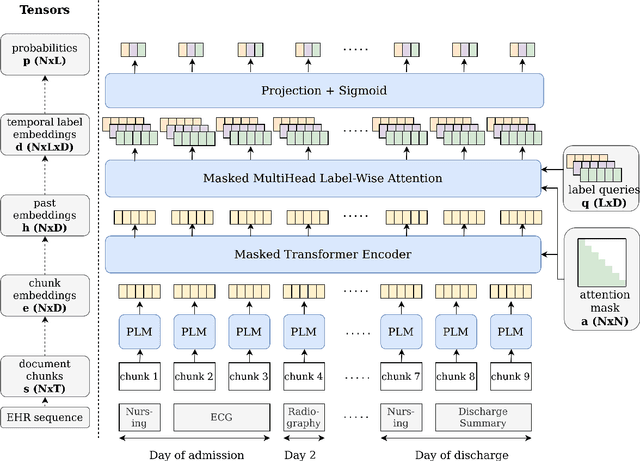
Past studies on the ICD coding problem focus on predicting clinical codes primarily based on the discharge summary. This covers only a small fraction of the notes generated during each hospital stay and leaves potential for improving performance by analysing all the available clinical notes. We propose a hierarchical transformer architecture that uses text across the entire sequence of clinical notes in each hospital stay for ICD coding, and incorporates embeddings for text metadata such as their position, time, and type of note. While using all clinical notes increases the quantity of data substantially, superconvergence can be used to reduce training costs. We evaluate the model on the MIMIC-III dataset. Our model exceeds the prior state-of-the-art when using only discharge summaries as input, and achieves further performance improvements when all clinical notes are used as input.