 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Stupid robot, I want to speak to a human!" User Frustration Detection in Task-Oriented Dialog Systems
Nov 26, 2024



Detecting user frustration in modern-day task-oriented dialog (TOD) systems is imperative for maintaining overall user satisfaction, engagement, and retention. However, most recent research is focused on sentiment and emotion detection in academic settings, thus failing to fully encapsulate implications of real-world user data. To mitigate this gap, in this work, we focus on user frustration in a deployed TOD system, assessing the feasibility of out-of-the-box solutions for user frustration detection. Specifically, we compare the performance of our deployed keyword-based approach, open-source approaches to sentiment analysis, dialog breakdown detection methods, and emerging in-context learning LLM-based detection. Our analysis highlights the limitations of open-source methods for real-world frustration detection, while demonstrating the superior performance of the LLM-based approach, achieving a 16\% relative improvement in F1 score on an internal benchmark. Finally, we analyze advantages and limitations of our methods and provide an insight into user frustration detection task for industry practitioners.
Continuous Predictive Modeling of Clinical Notes and ICD Codes in Patient Health Records
May 19, 2024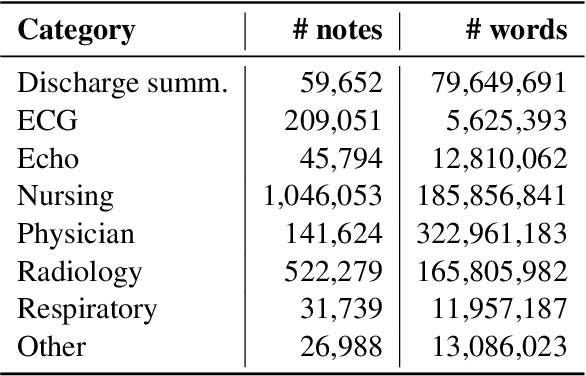
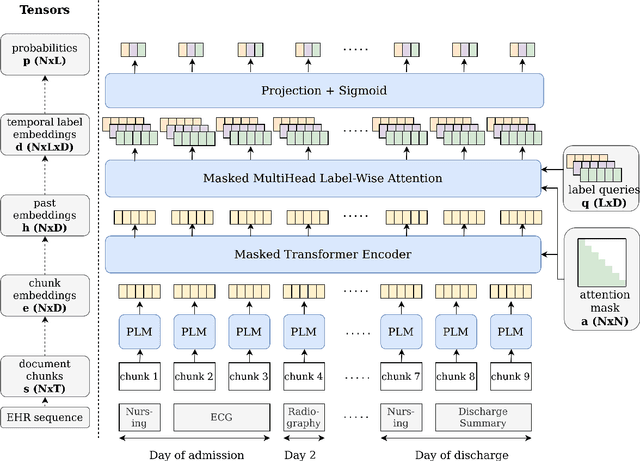
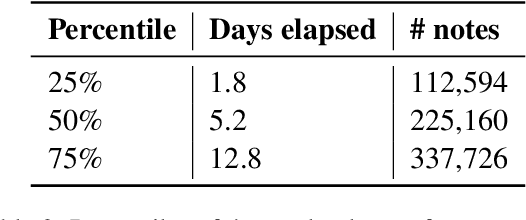
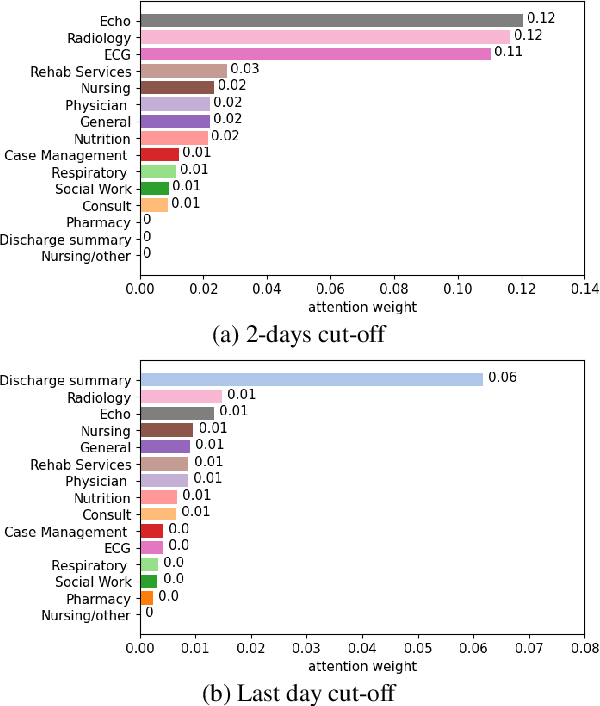
Electronic Health Records (EHR) serve as a valuable source of patient information, offering insights into medical histories, treatments, and outcomes. Previous research has developed systems for detecting applicable ICD codes that should be assigned while writing a given EHR document, mainly focusing on discharge summaries written at the end of a hospital stay. In this work, we investigate the potential of predicting these codes for the whole patient stay at different time points during their stay, even before they are officially assigned by clinicians. The development of methods to predict diagnoses and treatments earlier in advance could open opportunities for predictive medicine, such as identifying disease risks sooner, suggesting treatments, and optimizing resource allocation. Our experiments show that predictions regarding final ICD codes can be made already two days after admission and we propose a custom model that improves performance on this early prediction task.