 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Out-of-Scope Detection in Dialogue Systems via Uncertainty-Driven LLM Routing
Jul 02, 2025Out-of-scope (OOS) intent detection is a critical challenge in task-oriented dialogue systems (TODS), as it ensures robustness to unseen and ambiguous queries. In this work, we propose a novel but simple modular framework that combines uncertainty modeling with fine-tuned large language models (LLMs) for efficient and accurate OOS detection. The first step applies uncertainty estimation to the output of an in-scope intent detection classifier, which is currently deployed in a real-world TODS handling tens of thousands of user interactions daily. The second step then leverages an emerging LLM-based approach, where a fine-tuned LLM is triggered to make a final decision on instances with high uncertainty. Unlike prior approaches, our method effectively balances computational efficiency and performance, combining traditional approaches with LLMs and yielding state-of-the-art results on key OOS detection benchmarks, including real-world OOS data acquired from a deployed TODS.
"Stupid robot, I want to speak to a human!" User Frustration Detection in Task-Oriented Dialog Systems
Nov 26, 2024



Detecting user frustration in modern-day task-oriented dialog (TOD) systems is imperative for maintaining overall user satisfaction, engagement, and retention. However, most recent research is focused on sentiment and emotion detection in academic settings, thus failing to fully encapsulate implications of real-world user data. To mitigate this gap, in this work, we focus on user frustration in a deployed TOD system, assessing the feasibility of out-of-the-box solutions for user frustration detection. Specifically, we compare the performance of our deployed keyword-based approach, open-source approaches to sentiment analysis, dialog breakdown detection methods, and emerging in-context learning LLM-based detection. Our analysis highlights the limitations of open-source methods for real-world frustration detection, while demonstrating the superior performance of the LLM-based approach, achieving a 16\% relative improvement in F1 score on an internal benchmark. Finally, we analyze advantages and limitations of our methods and provide an insight into user frustration detection task for industry practitioners.
The Power of Selecting Key Blocks with Local Pre-ranking for Long Document Information Retrieval
Nov 18, 2021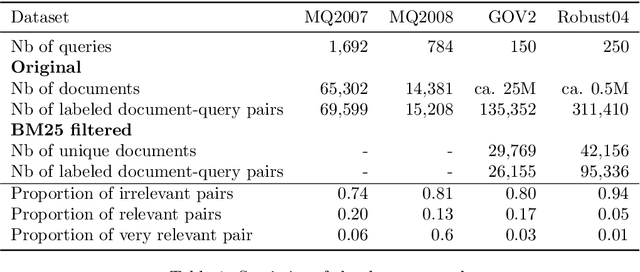
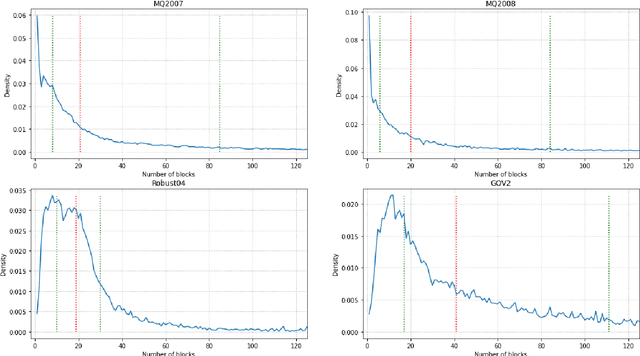
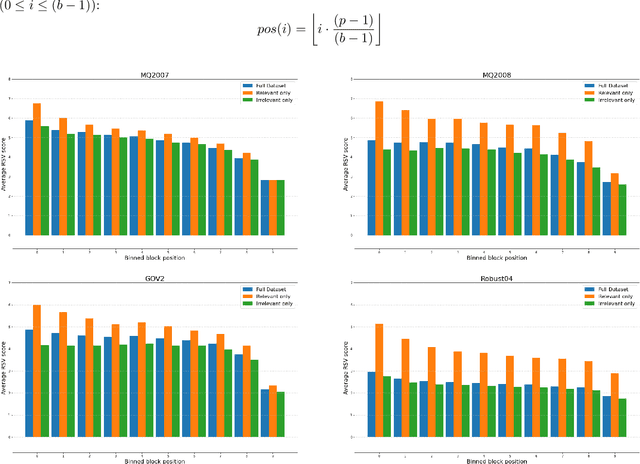
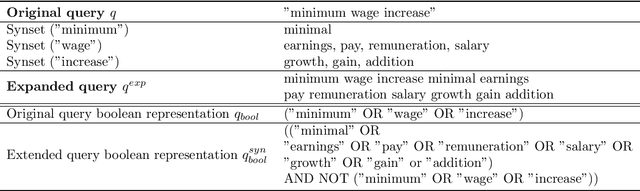
On a wide range of natural language processing and information retrieval tasks, transformer-based models, particularly pre-trained language models like BERT, have demonstrated tremendous effectiveness. Due to the quadratic complexity of the self-attention mechanism, however, such models have difficulties processing long documents. Recent works dealing with this issue include truncating long documents, segmenting them into passages that can be treated by a standard BERT model, or modifying the self-attention mechanism to make it sparser as in sparse-attention models. However, these approaches either lose information or have high computational complexity (and are both time, memory and energy consuming in this later case). We follow here a slightly different approach in which one first selects key blocks of a long document by local query-block pre-ranking, and then few blocks are aggregated to form a short document that can be processed by a model such as BERT. Experiments conducted on standard Information Retrieval datasets demonstrate the effectiveness of the proposed approach.
Bag-of-Vector Embeddings of Dependency Graphs for Semantic Induction
Sep 30, 2017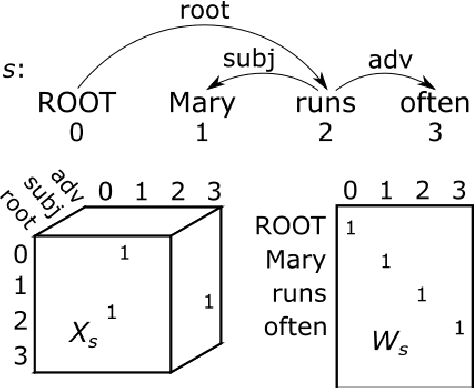
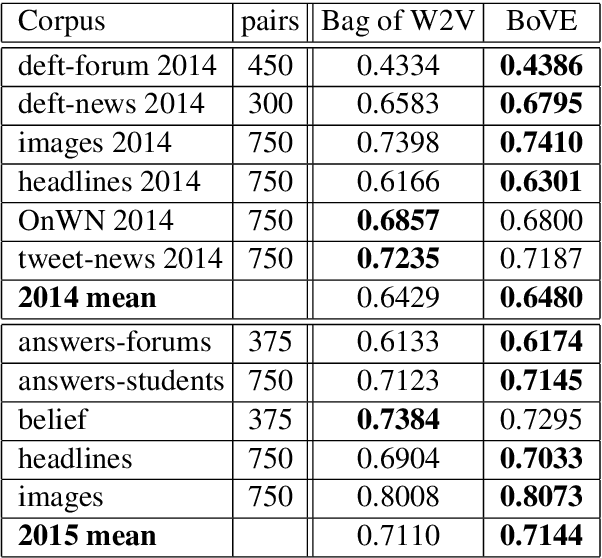
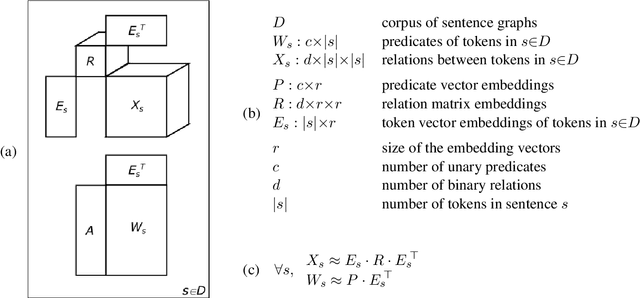
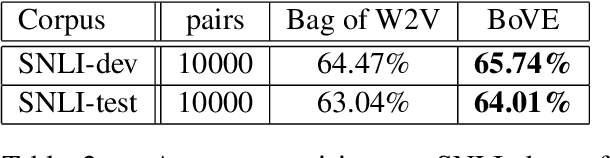
Vector-space models, from word embeddings to neural network parsers, have many advantages for NLP. But how to generalise from fixed-length word vectors to a vector space for arbitrary linguistic structures is still unclear. In this paper we propose bag-of-vector embeddings of arbitrary linguistic graphs. A bag-of-vector space is the minimal nonparametric extension of a vector space, allowing the representation to grow with the size of the graph, but not tying the representation to any specific tree or graph structure. We propose efficient training and inference algorithms based on tensor factorisation for embedding arbitrary graphs in a bag-of-vector space. We demonstrate the usefulness of this representation by training bag-of-vector embeddings of dependency graphs and evaluating them on unsupervised semantic induction for the Semantic Textual Similarity and Natural Language Inference tasks.
A Vector Space for Distributional Semantics for Entailment
Jul 13, 2016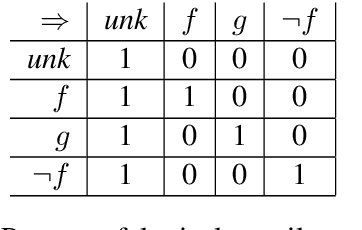
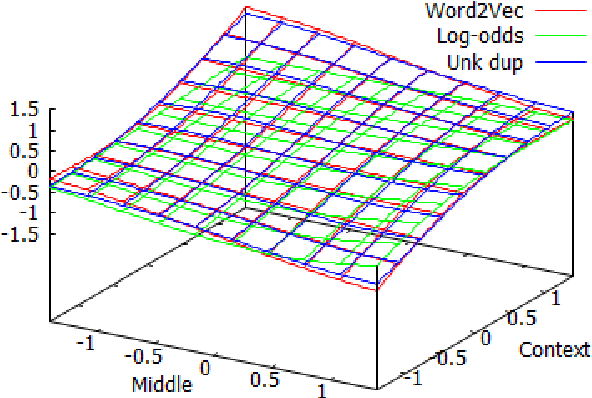
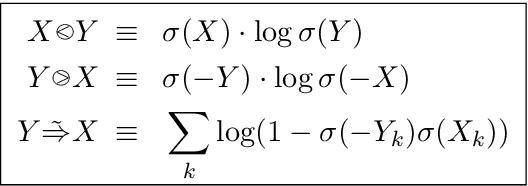
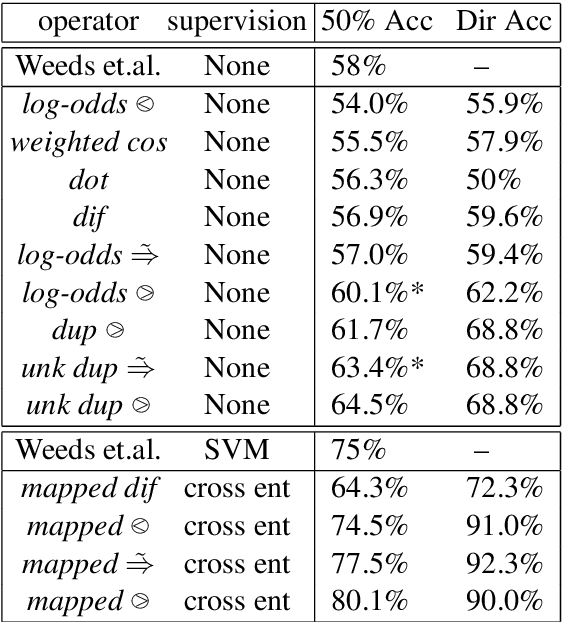
Distributional semantics creates vector-space representations that capture many forms of semantic similarity, but their relation to semantic entailment has been less clear. We propose a vector-space model which provides a formal foundation for a distributional semantics of entailment. Using a mean-field approximation, we develop approximate inference procedures and entailment operators over vectors of probabilities of features being known (versus unknown). We use this framework to reinterpret an existing distributional-semantic model (Word2Vec) as approximating an entailment-based model of the distributions of words in contexts, thereby predicting lexical entailment relations. In both unsupervised and semi-supervised experiments on hyponymy detection, we get substantial improvements over previous results.