 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Methodologies for LLM Evaluations Across Global Languages
Jan 22, 2026As frontier AI models are deployed globally, it is essential that their behaviour remains safe and reliable across diverse linguistic and cultural contexts. To examine how current model safeguards hold up in such settings, participants from the International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the EU, France, Kenya, South Korea and the UK conducted a joint multilingual evaluation exercise. Led by Singapore AISI, two open-weight models were tested across ten languages spanning high and low resourced groups: Cantonese English, Farsi, French, Japanese, Korean, Kiswahili, Malay, Mandarin Chinese and Telugu. Over 6,000 newly translated prompts were evaluated across five harm categories (privacy, non-violent crime, violent crime, intellectual property and jailbreak robustness), using both LLM-as-a-judge and human annotation. The exercise shows how safety behaviours can vary across languages. These include differences in safeguard robustness across languages and harm types and variation in evaluator reliability (LLM-as-judge vs. human review). Further, it also generated methodological insights for improving multilingual safety evaluations, such as the need for culturally contextualised translations, stress-tested evaluator prompts and clearer human annotation guidelines. This work represents an initial step toward a shared framework for multilingual safety testing of advanced AI systems and calls for continued collaboration with the wider research community and industry.
Improving Methodologies for Agentic Evaluations Across Domains: Leakage of Sensitive Information, Fraud and Cybersecurity Threats
Jan 22, 2026The rapid rise of autonomous AI systems and advancements in agent capabilities are introducing new risks due to reduced oversight of real-world interactions. Yet agent testing remains nascent and is still a developing science. As AI agents begin to be deployed globally, it is important that they handle different languages and cultures accurately and securely. To address this, participants from The International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the European Commission, France, Kenya, South Korea, and the United Kingdom have come together to align approaches to agentic evaluations. This is the third exercise, building on insights from two earlier joint testing exercises conducted by the Network in November 2024 and February 2025. The objective is to further refine best practices for testing advanced AI systems. The exercise was split into two strands: (1) common risks, including leakage of sensitive information and fraud, led by Singapore AISI; and (2) cybersecurity, led by UK AISI. A mix of open and closed-weight models were evaluated against tasks from various public agentic benchmarks. Given the nascency of agentic testing, our primary focus was on understanding methodological issues in conducting such tests, rather than examining test results or model capabilities. This collaboration marks an important step forward as participants work together to advance the science of agentic evaluations.
Fast Quantum Convolutional Neural Networks for Low-Complexity Object Detection in Autonomous Driving Applications
Dec 28, 2023



Spurred by consistent advances and innovation in deep learning, object detection applications have become prevalent, particularly in autonomous driving that leverages various visual data. As convolutional neural networks (CNNs) are being optimized, the performances and computation speeds of object detection in autonomous driving have been significantly improved. However, due to the exponentially rapid growth in the complexity and scale of data used in object detection, there are limitations in terms of computation speeds while conducting object detection solely with classical computing. Motivated by this, quantum convolution-based object detection (QCOD) is proposed to adopt quantum computing to perform object detection at high speed. The QCOD utilizes our proposed fast quantum convolution that uploads input channel information and re-constructs output channels for achieving reduced computational complexity and thus improving performances. Lastly, the extensive experiments with KITTI autonomous driving object detection dataset verify that the proposed fast quantum convolution and QCOD are successfully operated in real object detection applications.
Quantum Federated Learning with Entanglement Controlled Circuits and Superposition Coding
Dec 04, 2022While witnessing the noisy intermediate-scale quantum (NISQ) era and beyond, quantum federated learning (QFL) has recently become an emerging field of study. In QFL, each quantum computer or device locally trains its quantum neural network (QNN) with trainable gates, and communicates only these gate parameters over classical channels, without costly quantum communications. Towards enabling QFL under various channel conditions, in this article we develop a depth-controllable architecture of entangled slimmable quantum neural networks (eSQNNs), and propose an entangled slimmable QFL (eSQFL) that communicates the superposition-coded parameters of eS-QNNs. Compared to the existing depth-fixed QNNs, training the depth-controllable eSQNN architecture is more challenging due to high entanglement entropy and inter-depth interference, which are mitigated by introducing entanglement controlled universal (CU) gates and an inplace fidelity distillation (IPFD) regularizer penalizing inter-depth quantum state differences, respectively. Furthermore, we optimize the superposition coding power allocation by deriving and minimizing the convergence bound of eSQFL. In an image classification task, extensive simulations corroborate the effectiveness of eSQFL in terms of prediction accuracy, fidelity, and entropy compared to Vanilla QFL as well as under different channel conditions and various data distributions.
Projection Valued Measure-based Quantum Machine Learning for Multi-Class Classification
Nov 14, 2022
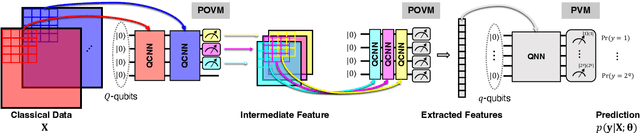


In recent years, quantum machine learning (QML) has been actively used for various tasks, e.g., classification, reinforcement learning, and adversarial learning. However, these QML studies are unable to carry out complex tasks due to scalability issues on input and output which is currently the biggest hurdle in QML. Therefore, the purpose of this paper is to overcome the problem of scalability. Motivated by this challenge, we focus on projection-valued measurements (PVM) which utilize the nature of probability amplitude in quantum statistical mechanics. By leveraging PVM, the output dimension is expanded from $q$, which is the number of qubits, to $2^q$. We propose a novel QML framework that utilizes PVM for multi-class classification. Our framework is proven to outperform the state-of-the-art (SOTA) methodologies with various datasets, assuming no more than 6 qubits are used. Furthermore, our PVM-based QML shows about $42.2\%$ better performance than the SOTA framework.
Quantum Split Neural Network Learning using Cross-Channel Pooling
Nov 12, 2022In recent years, quantum has been attracted by various fields such as quantum machine learning, quantum communication, and quantum computers. Among them, quantum federated learning (QFL) has recently received increasing attention, where quantum neural networks (QNNs) are integrated into federated learning (FL). In contrast to the existing QFL methods, we propose quantum split learning (QSL), which is the extension version of split learning. In classical computing, split learning has shown many advantages in faster convergence, communication cost, and even privacy. To fully utilize QSL, we propose crosschannel pooling which leverages the unique nature of quantum state tomography that is made by QNN. In numerical results, we corroborate that QSL achieves not only 1.64% higher top-1 accuracy than QFL but shows privacy-preserving in the MNIST classification task.
Neural Architectural Nonlinear Pre-Processing for mmWave Radar-based Human Gesture Perception
Nov 07, 2022



In modern on-driving computing environments, many sensors are used for context-aware applications. This paper utilizes two deep learning models, U-Net and EfficientNet, which consist of a convolutional neural network (CNN), to detect hand gestures and remove noise in the Range Doppler Map image that was measured through a millimeter-wave (mmWave) radar. To improve the performance of classification, accurate pre-processing algorithms are essential. Therefore, a novel pre-processing approach to denoise images before entering the first deep learning model stage increases the accuracy of classification. Thus, this paper proposes a deep neural network based high-performance nonlinear pre-processing method.
3D Scalable Quantum Convolutional Neural Networks for Point Cloud Data Processing in Classification Applications
Oct 18, 2022
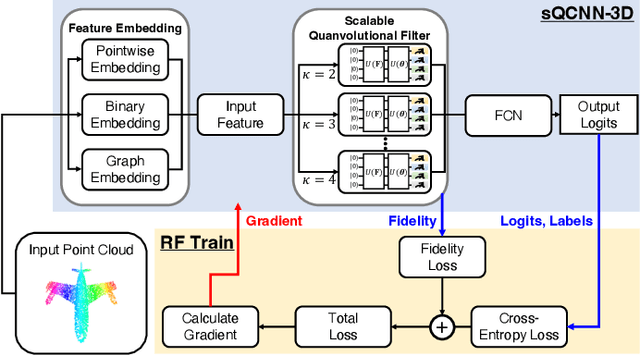

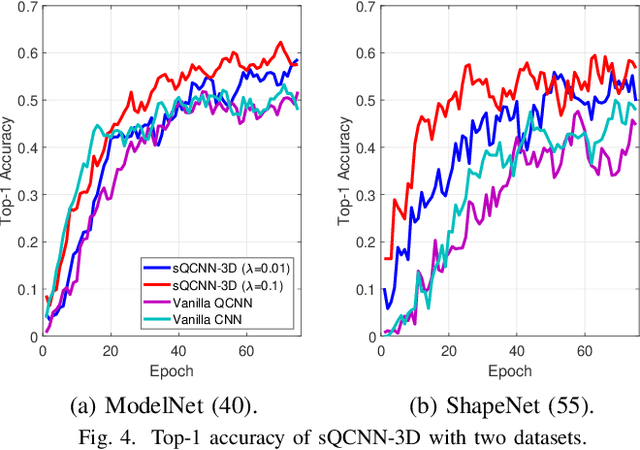
With the beginning of the noisy intermediate-scale quantum (NISQ) era, a quantum neural network (QNN) has recently emerged as a solution for several specific problems that classical neural networks cannot solve. Moreover, a quantum convolutional neural network (QCNN) is the quantum-version of CNN because it can process high-dimensional vector inputs in contrast to QNN. However, due to the nature of quantum computing, it is difficult to scale up the QCNN to extract a sufficient number of features due to barren plateaus. Motivated by this, a novel 3D scalable QCNN (sQCNN-3D) is proposed for point cloud data processing in classification applications. Furthermore, reverse fidelity training (RF-Train) is additionally considered on top of sQCNN-3D for diversifying features with a limited number of qubits using the fidelity of quantum computing. Our data-intensive performance evaluation verifies that the proposed algorithm achieves desired performance.
Scalable Quantum Convolutional Neural Networks
Sep 26, 2022
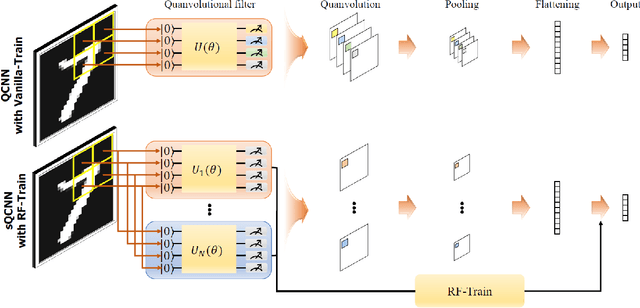
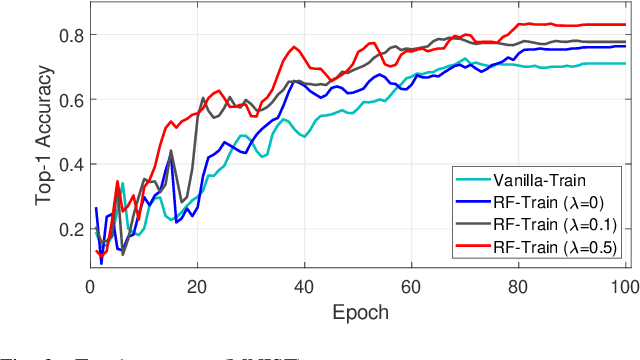
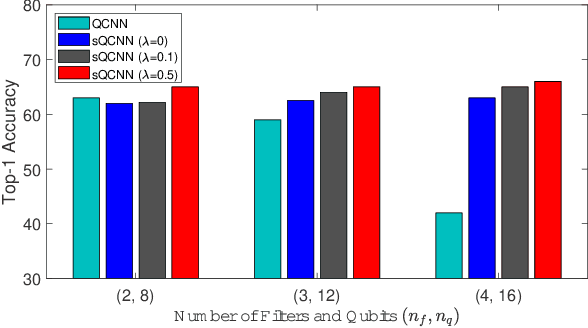
With the beginning of the noisy intermediate-scale quantum (NISQ) era, quantum neural network (QNN) has recently emerged as a solution for the problems that classical neural networks cannot solve. Moreover, QCNN is attracting attention as the next generation of QNN because it can process high-dimensional vector input. However, due to the nature of quantum computing, it is difficult for the classical QCNN to extract a sufficient number of features. Motivated by this, we propose a new version of QCNN, named scalable quantum convolutional neural network (sQCNN). In addition, using the fidelity of QC, we propose an sQCNN training algorithm named reverse fidelity training (RF-Train) that maximizes the performance of sQCNN.
SlimFL: Federated Learning with Superposition Coding over Slimmable Neural Networks
Mar 26, 2022
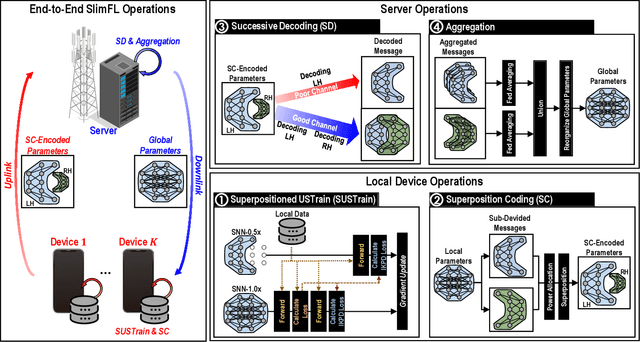
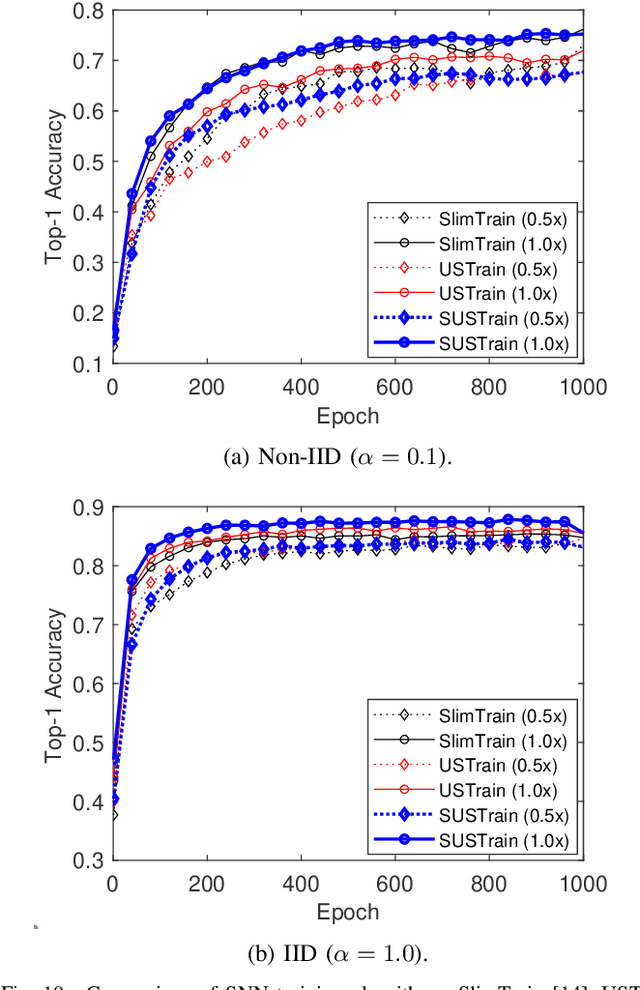
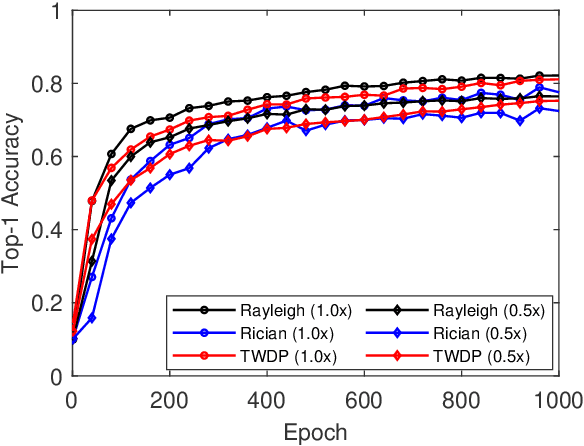
Federated learning (FL) is a key enabler for efficient communication and computing leveraging devices' distributed computing capabilities. However, applying FL in practice is challenging due to the local devices' heterogeneous energy, wireless channel conditions, and non-independently and identically distributed (non-IID) data distributions. To cope with these issues, this paper proposes a novel learning framework by integrating FL and width-adjustable slimmable neural networks (SNN). Integrating FL with SNNs is challenging due to time-varing channel conditions and data distributions. In addition, existing multi-width SNN training algorithms are sensitive to the data distributions across devices, which makes SNN ill-suited for FL. Motivated by this, we propose a communication and energy-efficient SNN-based FL (named SlimFL) that jointly utilizes superposition coding (SC) for global model aggregation and superposition training (ST) for updating local models. By applying SC, SlimFL exchanges the superposition of multiple width configurations decoded as many times as possible for a given communication throughput. Leveraging ST, SlimFL aligns the forward propagation of different width configurations while avoiding inter-width interference during backpropagation. We formally prove the convergence of SlimFL. The result reveals that SlimFL is not only communication-efficient but also deals with the non-IID data distributions and poor channel conditions, which is also corroborated by data-intensive simulations.