 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental Limits of Hierarchical Secure Aggregation with Cyclic User Association
Mar 07, 2025Secure aggregation is motivated by federated learning (FL) where a cloud server aims to compute an averaged model (i.e., weights of deep neural networks) of the locally-trained models of numerous clients, while adhering to data security requirements. Hierarchical secure aggregation (HSA) extends this concept to a three-layer network, where clustered users communicate with the server through an intermediate layer of relays. In HSA, beyond conventional server security, relay security is also enforced to ensure that the relays remain oblivious to the users' inputs (an abstraction of the local models in FL). Existing study on HSA assumes that each user is associated with only one relay, limiting opportunities for coding across inter-cluster users to achieve efficient communication and key generation. In this paper, we consider HSA with a cyclic association pattern where each user is connected to $B$ consecutive relays in a wrap-around manner. We propose an efficient aggregation scheme which includes a message design for the inputs inspired by gradient coding-a well-known technique for efficient communication in distributed computing-along with a highly nontrivial security key design. We also derive novel converse bounds on the minimum achievable communication and key rates using information-theoretic arguments.
Cloud-Based Federation Framework and Prototype for Open, Scalable, and Shared Access to NextG and IoT Testbeds
Aug 26, 2024



In this work, we present a new federation framework for UnionLabs, an innovative cloud-based resource-sharing infrastructure designed for next-generation (NextG) and Internet of Things (IoT) over-the-air (OTA) experiments. The framework aims to reduce the federation complexity for testbeds developers by automating tedious backend operations, thereby providing scalable federation and remote access to various wireless testbeds. We first describe the key components of the new federation framework, including the Systems Manager Integration Engine (SMIE), the Automated Script Generator (ASG), and the Database Context Manager (DCM). We then prototype and deploy the new Federation Plane on the Amazon Web Services (AWS) public cloud, demonstrating its effectiveness by federating two wireless testbeds: i) UB NeXT, a 5G-and-beyond (5G+) testbed at the University at Buffalo, and ii) UT IoT, an IoT testbed at the University of Utah. Through this work we aim to initiate a grassroots campaign to democratize access to wireless research testbeds with heterogeneous hardware resources and network environment, and accelerate the establishment of a mature, open experimental ecosystem for the wireless community. The API of the new Federation Plane will be released to the community after internal testing is completed.
A New Theoretical Perspective on Data Heterogeneity in Federated Optimization
Jul 22, 2024



In federated learning (FL), data heterogeneity is the main reason that existing theoretical analyses are pessimistic about the convergence rate. In particular, for many FL algorithms, the convergence rate grows dramatically when the number of local updates becomes large, especially when the product of the gradient divergence and local Lipschitz constant is large. However, empirical studies can show that more local updates can improve the convergence rate even when these two parameters are large, which is inconsistent with the theoretical findings. This paper aims to bridge this gap between theoretical understanding and practical performance by providing a theoretical analysis from a new perspective on data heterogeneity. In particular, we propose a new and weaker assumption compared to the local Lipschitz gradient assumption, named the heterogeneity-driven pseudo-Lipschitz assumption. We show that this and the gradient divergence assumptions can jointly characterize the effect of data heterogeneity. By deriving a convergence upper bound for FedAvg and its extensions, we show that, compared to the existing works, local Lipschitz constant is replaced by the much smaller heterogeneity-driven pseudo-Lipschitz constant and the corresponding convergence upper bound can be significantly reduced for the same number of local updates, although its order stays the same. In addition, when the local objective function is quadratic, more insights on the impact of data heterogeneity can be obtained using the heterogeneity-driven pseudo-Lipschitz constant. For example, we can identify a region where FedAvg can outperform mini-batch SGD even when the gradient divergence can be arbitrarily large. Our findings are validated using experiments.
HawkRover: An Autonomous mmWave Vehicular Communication Testbed with Multi-sensor Fusion and Deep Learning
Jan 04, 2024Connected and automated vehicles (CAVs) have become a transformative technology that can change our daily life. Currently, millimeter-wave (mmWave) bands are identified as the promising CAV connectivity solution. While it can provide high data rate, their realization faces many challenges such as high attenuation during mmWave signal propagation and mobility management. Existing solution has to initiate pilot signal to measure channel information, then apply signal processing to calculate the best narrow beam towards the receiver end to guarantee sufficient signal power. This process takes significant overhead and time, hence not suitable for vehicles. In this study, we propose an autonomous and low-cost testbed to collect extensive co-located mmWave signal and other sensors data such as LiDAR (Light Detection and Ranging), cameras, ultrasonic, etc, traditionally for ``automated'', to facilitate mmWave vehicular communications. Intuitively, these sensors can build a 3D map around the vehicle and signal propagation path can be estimated, eliminating iterative the process via pilot signals. This multimodal data fusion, together with AI, is expected to bring significant advances in ``connected'' research.
Physics-informed Generalizable Wireless Channel Modeling with Segmentation and Deep Learning: Fundamentals, Methodologies, and Challenges
Jan 02, 2024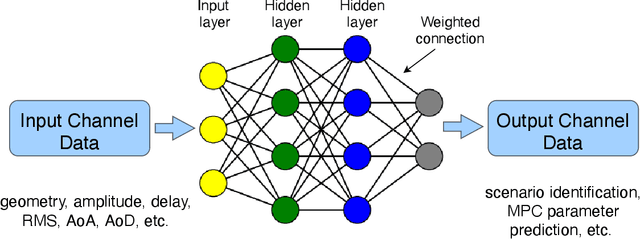



Channel modeling is fundamental in advancing wireless systems and has thus attracted considerable research focus. Recent trends have seen a growing reliance on data-driven techniques to facilitate the modeling process and yield accurate channel predictions. In this work, we first provide a concise overview of data-driven channel modeling methods, highlighting their limitations. Subsequently, we introduce the concept and advantages of physics-informed neural network (PINN)-based modeling and a summary of recent contributions in this area. Our findings demonstrate that PINN-based approaches in channel modeling exhibit promising attributes such as generalizability, interpretability, and robustness. We offer a comprehensive architecture for PINN methodology, designed to inform and inspire future model development. A case-study of our recent work on precise indoor channel prediction with semantic segmentation and deep learning is presented. The study concludes by addressing the challenges faced and suggesting potential research directions in this field.
A Lightweight Method for Tackling Unknown Participation Probabilities in Federated Averaging
Jun 06, 2023



In federated learning (FL), clients usually have diverse participation probabilities that are unknown a priori, which can significantly harm the performance of FL if not handled properly. Existing works aiming at addressing this problem are usually based on global variance reduction, which requires a substantial amount of additional memory in a multiplicative factor equal to the total number of clients. An important open problem is to find a lightweight method for FL in the presence of clients with unknown participation rates. In this paper, we address this problem by adapting the aggregation weights in federated averaging (FedAvg) based on the participation history of each client. We first show that, with heterogeneous participation probabilities, FedAvg with non-optimal aggregation weights can diverge from the optimal solution of the original FL objective, indicating the need of finding optimal aggregation weights. However, it is difficult to compute the optimal weights when the participation probabilities are unknown. To address this problem, we present a new algorithm called FedAU, which improves FedAvg by adaptively weighting the client updates based on online estimates of the optimal weights without knowing the probabilities of client participation. We provide a theoretical convergence analysis of FedAU using a novel methodology to connect the estimation error and convergence. Our theoretical results reveal important and interesting insights, while showing that FedAU converges to an optimal solution of the original objective and has desirable properties such as linear speedup. Our experimental results also verify the advantage of FedAU over baseline methods.
Federated Learning with Flexible Control
Dec 16, 2022Federated learning (FL) enables distributed model training from local data collected by users. In distributed systems with constrained resources and potentially high dynamics, e.g., mobile edge networks, the efficiency of FL is an important problem. Existing works have separately considered different configurations to make FL more efficient, such as infrequent transmission of model updates, client subsampling, and compression of update vectors. However, an important open problem is how to jointly apply and tune these control knobs in a single FL algorithm, to achieve the best performance by allowing a high degree of freedom in control decisions. In this paper, we address this problem and propose FlexFL - an FL algorithm with multiple options that can be adjusted flexibly. Our FlexFL algorithm allows both arbitrary rates of local computation at clients and arbitrary amounts of communication between clients and the server, making both the computation and communication resource consumption adjustable. We prove a convergence upper bound of this algorithm. Based on this result, we further propose a stochastic optimization formulation and algorithm to determine the control decisions that (approximately) minimize the convergence bound, while conforming to constraints related to resource consumption. The advantage of our approach is also verified using experiments.
A Unified Analysis of Federated Learning with Arbitrary Client Participation
Jun 01, 2022


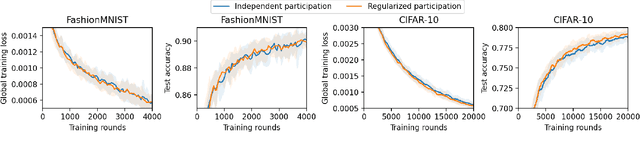
Federated learning (FL) faces challenges of intermittent client availability and computation/communication efficiency. As a result, only a small subset of clients can participate in FL at a given time. It is important to understand how partial client participation affects convergence, but most existing works have either considered idealized participation patterns or obtained results with non-zero optimality error for generic patterns. In this paper, we provide a unified convergence analysis for FL with arbitrary client participation. We first introduce a generalized version of federated averaging (FedAvg) that amplifies parameter updates at an interval of multiple FL rounds. Then, we present a novel analysis that captures the effect of client participation in a single term. By analyzing this term, we obtain convergence upper bounds for a wide range of participation patterns, including both non-stochastic and stochastic cases, which match either the lower bound of stochastic gradient descent (SGD) or the state-of-the-art results in specific settings. We also discuss various insights, recommendations, and experimental results.
SlimFL: Federated Learning with Superposition Coding over Slimmable Neural Networks
Mar 26, 2022
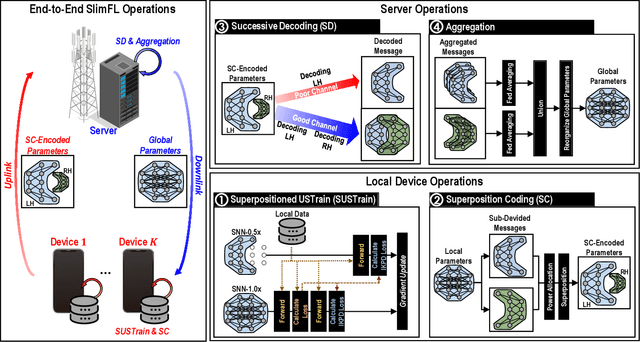
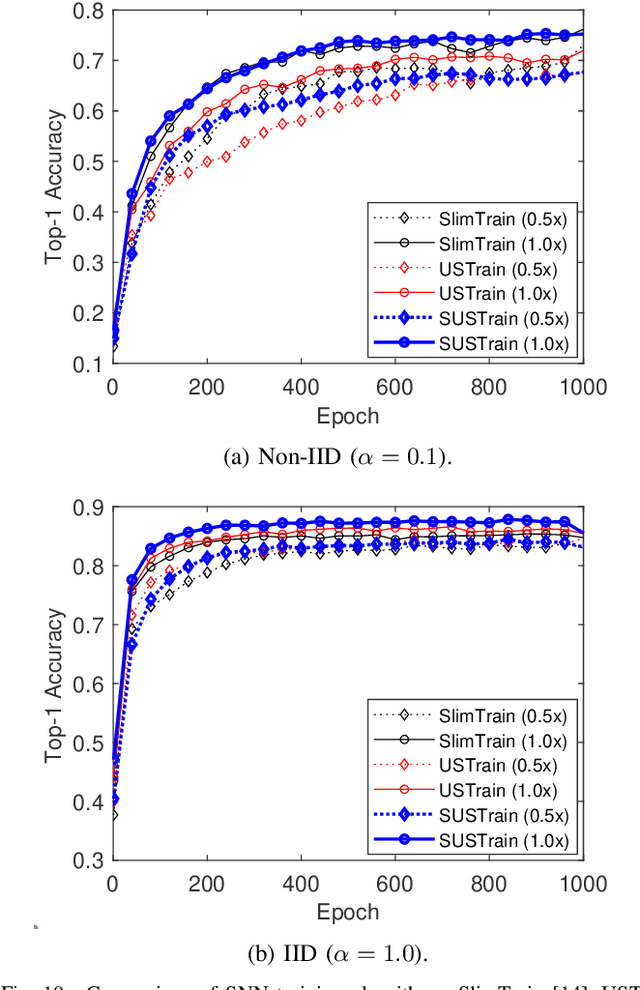
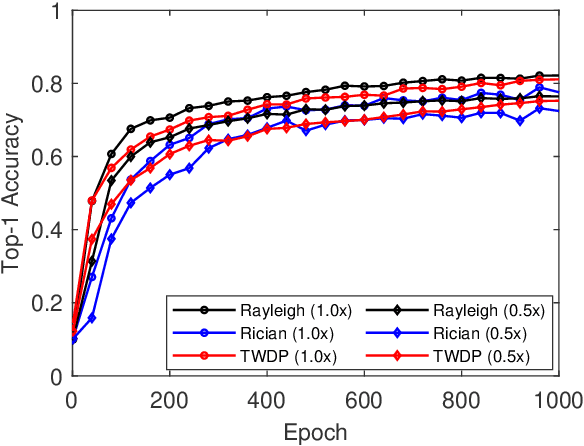
Federated learning (FL) is a key enabler for efficient communication and computing leveraging devices' distributed computing capabilities. However, applying FL in practice is challenging due to the local devices' heterogeneous energy, wireless channel conditions, and non-independently and identically distributed (non-IID) data distributions. To cope with these issues, this paper proposes a novel learning framework by integrating FL and width-adjustable slimmable neural networks (SNN). Integrating FL with SNNs is challenging due to time-varing channel conditions and data distributions. In addition, existing multi-width SNN training algorithms are sensitive to the data distributions across devices, which makes SNN ill-suited for FL. Motivated by this, we propose a communication and energy-efficient SNN-based FL (named SlimFL) that jointly utilizes superposition coding (SC) for global model aggregation and superposition training (ST) for updating local models. By applying SC, SlimFL exchanges the superposition of multiple width configurations decoded as many times as possible for a given communication throughput. Leveraging ST, SlimFL aligns the forward propagation of different width configurations while avoiding inter-width interference during backpropagation. We formally prove the convergence of SlimFL. The result reveals that SlimFL is not only communication-efficient but also deals with the non-IID data distributions and poor channel conditions, which is also corroborated by data-intensive simulations.
Communication-Efficient Device Scheduling for Federated Learning Using Stochastic Optimization
Jan 19, 2022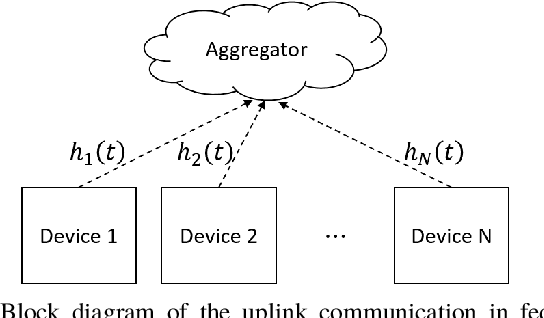
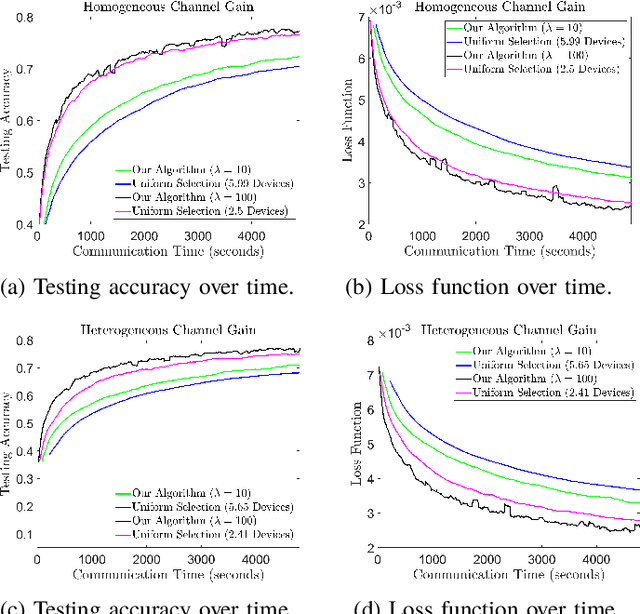
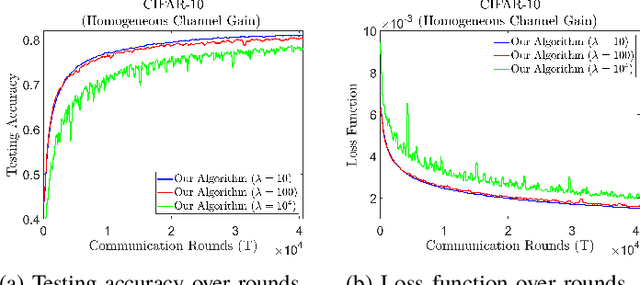
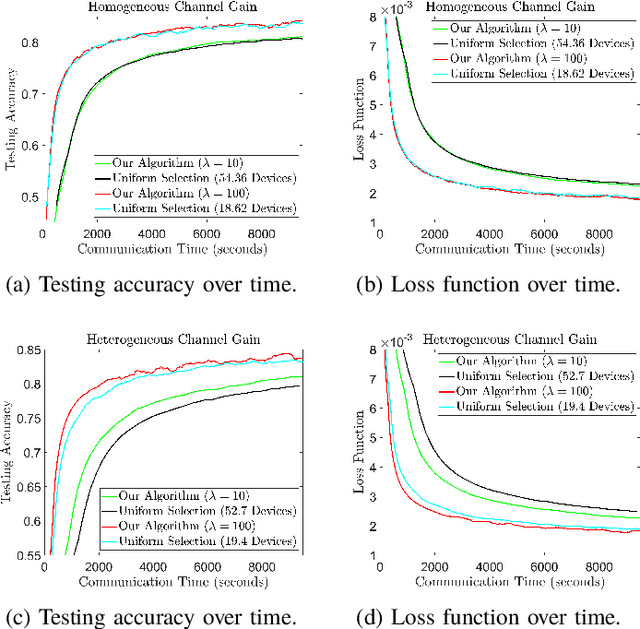
Federated learning (FL) is a useful tool in distributed machine learning that utilizes users' local datasets in a privacy-preserving manner. When deploying FL in a constrained wireless environment; however, training models in a time-efficient manner can be a challenging task due to intermittent connectivity of devices, heterogeneous connection quality, and non-i.i.d. data. In this paper, we provide a novel convergence analysis of non-convex loss functions using FL on both i.i.d. and non-i.i.d. datasets with arbitrary device selection probabilities for each round. Then, using the derived convergence bound, we use stochastic optimization to develop a new client selection and power allocation algorithm that minimizes a function of the convergence bound and the average communication time under a transmit power constraint. We find an analytical solution to the minimization problem. One key feature of the algorithm is that knowledge of the channel statistics is not required and only the instantaneous channel state information needs to be known. Using the FEMNIST and CIFAR-10 datasets, we show through simulations that the communication time can be significantly decreased using our algorithm, compared to uniformly random participation.