 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiuser OTFS Channel Parameter Estimation Toward Grid-Independent Regime
May 06, 2026We study channel parameter estimation for multiuser orthogonal time frequency space (OTFS) systems in the delay-Doppler (DD) domain. To enable structured parametric estimation, we adopt a multi-user pilot cyclic prefix (MU-PCP) design, which multiplexes users along the Doppler dimension while preserving a separable exponential structure. This structure facilitates high-resolution estimation of fractional delay and Doppler parameters in the multiuser setting. Building on this framework, we extend weighted MUSIC (W-MUSIC) to multiuser OTFS, providing a computationally efficient approach with mild grid dependency, and develop a matrix pencil (MP)-based method that achieves fully grid-independent delay-Doppler parameter estimation. Numerical results demonstrate the effectiveness of the proposed methods and reveal a robustness-complexity tradeoff: W-MUSIC performs better at low SNR, while MP achieves higher estimation accuracy at moderate-to-high SNR with significantly lower computational complexity.
Windowed Dictionary Design for Delay-Aware OMP Channel Estimation under Fractional Doppler
Dec 02, 2024Delay-Doppler (DD) signal processing has emerged as a powerful tool for analyzing multipath and time-varying channel effects. Due to the inherent sparsity of the wireless channel in the DD domain, compressed sensing (CS) based techniques, such as orthogonal matching pursuit (OMP), are commonly used for channel estimation. However, many of these methods assume integer Doppler shifts, which can lead to performance degradation in the presence of fractional Doppler. In this paper, we propose a windowed dictionary design technique while we develop a delay-aware orthogonal matching pursuit (DA-OMP) algorithm that mitigates the impact of fractional Doppler shifts on DD domain channel estimation. First, we apply receiver windowing to reduce the correlation between the columns of our proposed dictionary matrix. Second, we introduce a delay-aware interference block to quantify the interference caused by fractional Doppler. This approach removes the need for a pre-determined stopping criterion, which is typically based on the number of propagation paths, in conventional OMP algorithm. Our simulation results confirm the effective performance of our proposed DA-OMP algorithm using the proposed windowed dictionary in terms of normalized mean square error (NMSE) of the channel estimate. In particular, our proposed DA-OMP algorithm demonstrates substantial gains compared to standard OMP algorithm in terms of channel estimation NMSE with and without windowed dictionary.
A New Theoretical Perspective on Data Heterogeneity in Federated Optimization
Jul 22, 2024



In federated learning (FL), data heterogeneity is the main reason that existing theoretical analyses are pessimistic about the convergence rate. In particular, for many FL algorithms, the convergence rate grows dramatically when the number of local updates becomes large, especially when the product of the gradient divergence and local Lipschitz constant is large. However, empirical studies can show that more local updates can improve the convergence rate even when these two parameters are large, which is inconsistent with the theoretical findings. This paper aims to bridge this gap between theoretical understanding and practical performance by providing a theoretical analysis from a new perspective on data heterogeneity. In particular, we propose a new and weaker assumption compared to the local Lipschitz gradient assumption, named the heterogeneity-driven pseudo-Lipschitz assumption. We show that this and the gradient divergence assumptions can jointly characterize the effect of data heterogeneity. By deriving a convergence upper bound for FedAvg and its extensions, we show that, compared to the existing works, local Lipschitz constant is replaced by the much smaller heterogeneity-driven pseudo-Lipschitz constant and the corresponding convergence upper bound can be significantly reduced for the same number of local updates, although its order stays the same. In addition, when the local objective function is quadratic, more insights on the impact of data heterogeneity can be obtained using the heterogeneity-driven pseudo-Lipschitz constant. For example, we can identify a region where FedAvg can outperform mini-batch SGD even when the gradient divergence can be arbitrarily large. Our findings are validated using experiments.
Local Averaging Helps: Hierarchical Federated Learning and Convergence Analysis
Oct 24, 2020
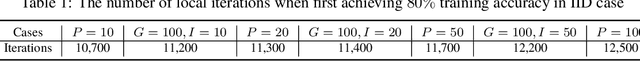

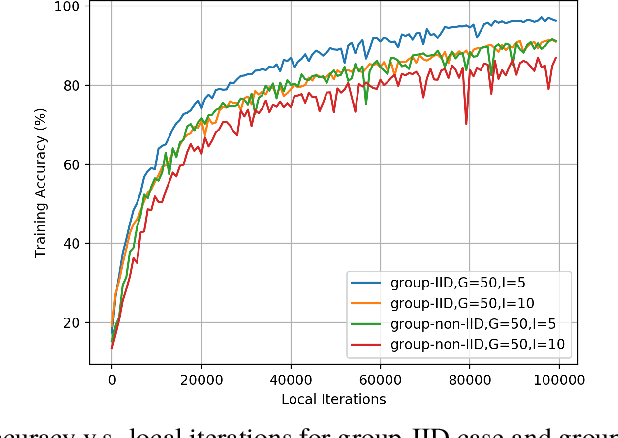
Federated learning is an effective approach to realize collaborative learning among edge devices without exchanging raw data. In practice, these devices may connect to local hubs which are then connected to the global server (aggregator). Due to the (possibly limited) computation capability of these local hubs, it is reasonable to assume that they can perform simple averaging operations. A natural question is whether such local averaging is beneficial under different system parameters and how much gain can be obtained compared to the case without such averaging. In this paper, we study hierarchical federated learning with stochastic gradient descent (HF-SGD) and conduct a thorough theoretical analysis to analyze its convergence behavior. The analysis demonstrates the impact of local averaging precisely as a function of system parameters. Due to the higher communication cost of global averaging, a strategy of decreasing the global averaging frequency and increasing the local averaging frequency is proposed. Experiments validate the proposed theoretical analysis and the advantages of hierarchical federated learning.