 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Capacity of Information-Theoretic Secure Aggregation in Federated Learning
Jun 05, 2026Secure aggregation allows a server to aggregate users' local updates while preserving update privacy. Existing information-theoretic problems typically assume that correlated random keys are provided by a trusted third party (TTP) or generated via prescribed groupwise structures, while the communication cost for establishing such correlated keys is often ignored. Consequently, the fundamental limits under general key-distribution mechanisms remain unknown. In this paper, we study the $T$-colluding information-theoretic secure aggregation problem with $N$ users under a general two-phase framework consisting of a key distribution phase and an update aggregation phase. Unlike prior work, we model key distribution through user-to-user communication and allow arbitrary user-generated key-distribution mechanisms, eliminating TTP or prescribed structures. This enables a joint characterization of three resources: randomness for security, key-distribution communication, and aggregation communication. We completely characterize the capacity region among these three resources by constructing a novel secure aggregation scheme together with a matching information-theoretic converse. In particular, we develop an explicit deterministic capacity-achieving construction over any finite field of size at least $N$, whereas most existing schemes either rely on TTP or employ randomized or existential constructions over sufficiently large finite fields. We further show that the optimal performance can be achieved using only pairwise shared keys, enabling implementation via Diffie--Hellman key exchange. Compared with Google's seminal secure aggregation scheme, the proposed scheme requires fewer random masking keys while preserving the same aggregation communication overhead.
Hybrid Iterative Detection for OTFS: Interplay between Local L-MMSE and Global Message Passing
Dec 16, 2025
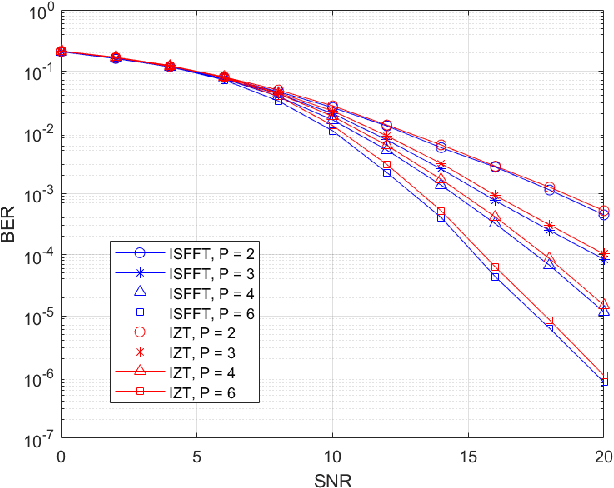
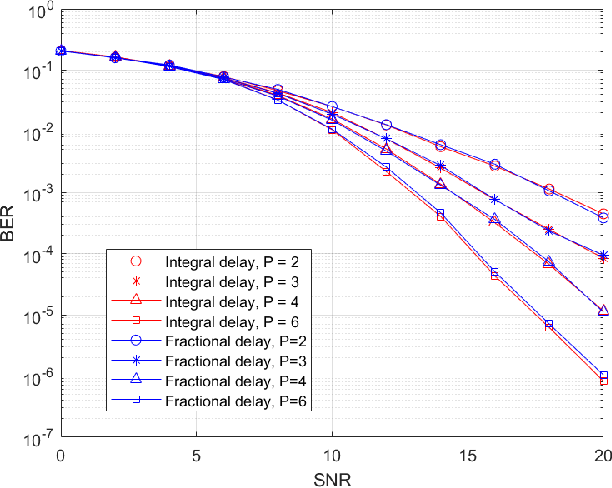
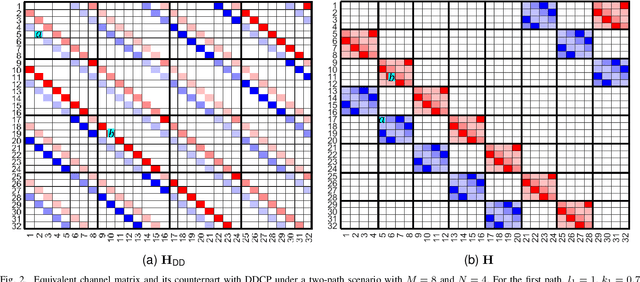
Orthogonal time frequency space (OTFS) modulation has emerged as a robust solution for high-mobility wireless communications. However, conventional detection algorithms, such as linear equalizers and message passing (MP) methods, either suffer from noise enhancement or fail under complex doubly-selective channels, especially in the presence of fractional delay and Doppler shifts. In this paper, we propose a hybrid low-complexity iterative detection framework that combines linear minimum mean square error (L-MMSE) estimation with MP-based probabilistic inference. The key idea is to apply a new delay-Doppler (DD) commutation precoder (DDCP) to the DD domain signal vector, such that the resulting effective channel matrix exhibits a structured form with several locally dense blocks that are sparsely inter-connected. This precoding structure enables a hybrid iterative detection strategy, where a low-dimensional L-MMSE estimation is applied to the dense blocks, while MP is utilized to exploit the sparse inter-block connections. Furthermore, we provide a detailed complexity analysis, which shows that the proposed scheme incurs lower computational cost compared to the full-size L-MMSE detection. The simulation results of convergence performance confirm that the proposed hybrid MP detection achieves fast and reliable convergence with controlled complexity. In terms of error performance, simulation results demonstrate that our scheme achieves significantly better bit error rate (BER) under various channel conditions. Particularly in multipath scenarios, the BER performance of the proposed method closely approaches the matched filter bound (MFB), indicating its near-optimal error performance.
Information-Theoretic Decentralized Secure Aggregation with Collusion Resilience
Aug 01, 2025In decentralized federated learning (FL), multiple clients collaboratively learn a shared machine learning (ML) model by leveraging their privately held datasets distributed across the network, through interactive exchange of the intermediate model updates. To ensure data security, cryptographic techniques are commonly employed to protect model updates during aggregation. Despite growing interest in secure aggregation, existing works predominantly focus on protocol design and computational guarantees, with limited understanding of the fundamental information-theoretic limits of such systems. Moreover, optimal bounds on communication and key usage remain unknown in decentralized settings, where no central aggregator is available. Motivated by these gaps, we study the problem of decentralized secure aggregation (DSA) from an information-theoretic perspective. Specifically, we consider a network of $K$ fully-connected users, each holding a private input -- an abstraction of local training data -- who aim to securely compute the sum of all inputs. The security constraint requires that no user learns anything beyond the input sum, even when colluding with up to $T$ other users. We characterize the optimal rate region, which specifies the minimum achievable communication and secret key rates for DSA. In particular, we show that to securely compute one symbol of the desired input sum, each user must (i) transmit at least one symbol to others, (ii) hold at least one symbol of secret key, and (iii) all users must collectively hold no fewer than $K - 1$ independent key symbols. Our results establish the fundamental performance limits of DSA, providing insights for the design of provably secure and communication-efficient protocols in distributed learning systems.
Fundamental Limits of Hierarchical Secure Aggregation with Cyclic User Association
Mar 07, 2025Secure aggregation is motivated by federated learning (FL) where a cloud server aims to compute an averaged model (i.e., weights of deep neural networks) of the locally-trained models of numerous clients, while adhering to data security requirements. Hierarchical secure aggregation (HSA) extends this concept to a three-layer network, where clustered users communicate with the server through an intermediate layer of relays. In HSA, beyond conventional server security, relay security is also enforced to ensure that the relays remain oblivious to the users' inputs (an abstraction of the local models in FL). Existing study on HSA assumes that each user is associated with only one relay, limiting opportunities for coding across inter-cluster users to achieve efficient communication and key generation. In this paper, we consider HSA with a cyclic association pattern where each user is connected to $B$ consecutive relays in a wrap-around manner. We propose an efficient aggregation scheme which includes a message design for the inputs inspired by gradient coding-a well-known technique for efficient communication in distributed computing-along with a highly nontrivial security key design. We also derive novel converse bounds on the minimum achievable communication and key rates using information-theoretic arguments.
Group Sparsity Methods for Compressive Space-Frequency Channel Estimation and Spatial Equalization in Fluid Antenna System
Mar 03, 2025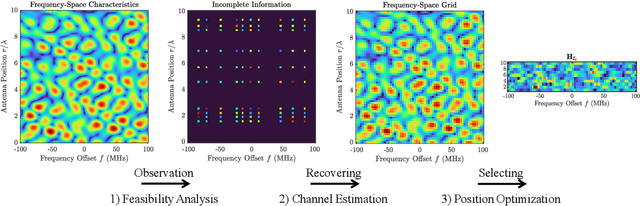



Fluid Antenna System (FAS) unlocks unprecedented flexibility in wireless channel optimization through spatial reconfigurability. However, its practical deployment is hindered by the coupled challenges posed by high-dimensional channel estimation and real-time position optimization. This paper bridges wireless propagation physics with compressed sensing theory to address these challenges through three aspects. First, we establish a group-sparse recovery framework for space-frequency characteristics (SFC) in FAS, formally characterizing leakage-induced sparsity degradation from limited aperture and bandwidth as a structured group-sparsity problem. By deriving dictionary-adapted group restricted isometry property (D-GRIP), we prove tight recovery bounds for a convex $\ell_1/\ell_2$-mixed norm optimization formulation that preserves leakage-aware sparsity patterns. Second, we develop a Descending Correlation Group Orthogonal Matching Pursuit (DC-GOMP) algorithm that systematically relaxes leakage constraints to reduce subcoherence. This approach enables robust FSC recovery with accelerated convergence and superior performance compared to conventional compressive sensing methods like OMP or GOMP. Third, we formulate spatial equalization (SE) as a mixed-integer linear programming (MILP) problem, ensuring optimality through the branch-and-bound method. To achieve real-time implementability while maintaining near-optimal performance, we complement this with a greedy algorithm. Simulation results demonstrate the proposed channel estimation algorithm effectively resolves energy misallocation and enables recovery of weak details, achieving superior recovery accuracy and convergence rate. The SE framework suppresses deep fading phenomena and reduces hardware deployment overhead while maintaining equivalent link reliability.
Flexible Coded Distributed Convolution Computing for Enhanced Fault Tolerance and Numerical Stability in Distributed CNNs
Nov 03, 2024



Deploying Convolutional Neural Networks (CNNs) on resource-constrained devices necessitates efficient management of computational resources, often via distributed systems susceptible to latency from straggler nodes. This paper introduces the Flexible Coded Distributed Convolution Computing (FCDCC) framework to enhance fault tolerance and numerical stability in distributed CNNs. We extend Coded Distributed Computing (CDC) with Circulant and Rotation Matrix Embedding (CRME) which was originally proposed for matrix multiplication to high-dimensional tensor convolution. For the proposed scheme, referred to as Numerically Stable Coded Tensor Convolution (NSCTC) scheme, we also propose two new coded partitioning schemes: Adaptive-Padding Coded Partitioning (APCP) for input tensor and Kernel-Channel Coded Partitioning (KCCP) for filter tensor. These strategies enable linear decomposition of tensor convolutions and encoding them into CDC sub-tasks, combining model parallelism with coded redundancy for robust and efficient execution. Theoretical analysis identifies an optimal trade-off between communication and storage costs. Empirical results validate the framework's effectiveness in computational efficiency, fault tolerance, and scalability across various CNN architectures.
Optimal Beamforming of RIS-Aided Wireless Communications: An Alternating Inner Product Maximization Approach
May 10, 2024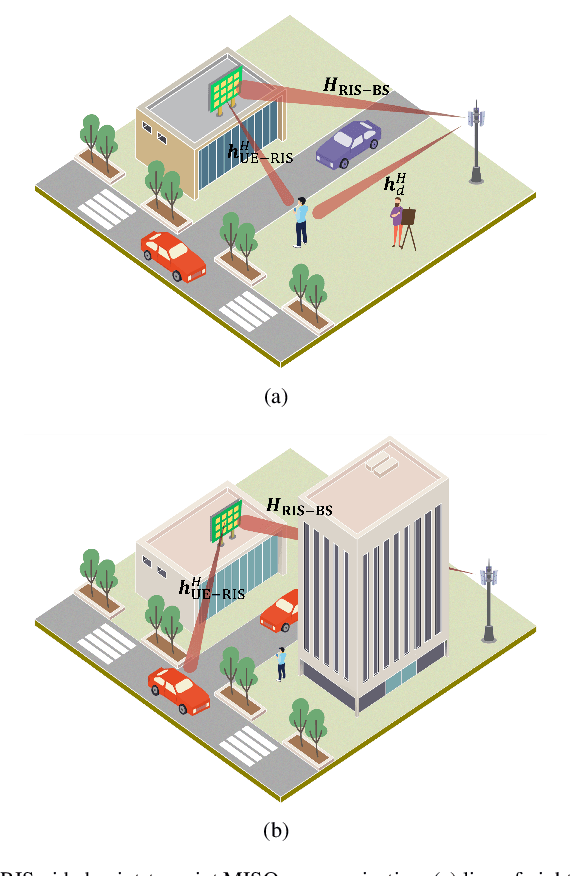
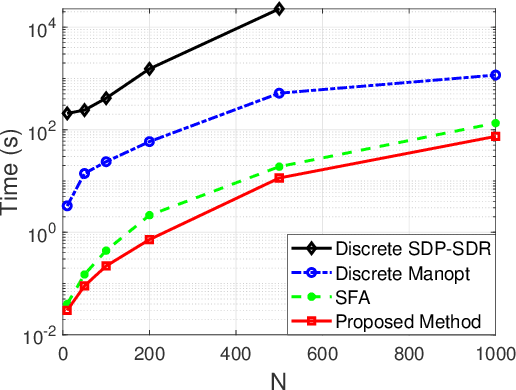


This paper investigates a general discrete $\ell_p$-norm maximization problem, with the power enhancement at steering directions through reconfigurable intelligent surfaces (RISs) as an instance. We propose a mathematically concise iterative framework composed of alternating inner product maximizations, well-suited for addressing $\ell_1$- and $\ell_2$-norm maximizations with either discrete or continuous uni-modular variable constraints. The iteration is proven to be monotonically non-decreasing. Moreover, this framework exhibits a distinctive capability to mitigate performance degradation due to discrete quantization, establishing it as the first post-rounding lifting approach applicable to any algorithm intended for the continuous solution. Additionally, as an integral component of the alternating iterations framework, we present a divide-and-sort (DaS) method to tackle the discrete inner product maximization problem. In the realm of $\ell_\infty$-norm maximization with discrete uni-modular constraints, the DaS ensures the identification of the global optimum with polynomial search complexity. We validate the effectiveness of the alternating inner product maximization framework in beamforming through RISs using both numerical experiments and field trials on prototypes. The results demonstrate that the proposed approach achieves higher power enhancement and outperforms other competitors. Finally, we show that discrete phase configurations with moderate quantization bits (e.g., 4-bit) exhibit comparable performance to continuous configurations in terms of power gains.
Multi-user ISAC through Stacked Intelligent Metasurfaces: New Algorithms and Experiments
May 02, 2024



This paper investigates a Stacked Intelligent Metasurfaces (SIM)-assisted Integrated Sensing and Communications (ISAC) system. An extended target model is considered, where the BS aims to estimate the complete target response matrix relative to the SIM. Under the constraints of minimum Signal-to-Interference-plus-Noise Ratio (SINR) for the communication users (CUs) and maximum transmit power, we jointly optimize the transmit beamforming at the base station (BS) and the end-to-end transmission matrix of the SIM, to minimize the Cram\'er-Rao Bound (CRB) for target estimation. Effective algorithms such as the alternating optimization (AO) and semidefinite relaxation (SDR) are employed to solve the non-convex SINR-constrained CRB minimization problem. Finally, we design and build an experimental platform for SIM, and evaluate the performance of the proposed algorithms for communication and sensing tasks.
Deterministic-Random Tradeoff of Integrated Sensing and Communications in Gaussian Channels: A Rate-Distortion Perspective
Jan 04, 2023


Integrated sensing and communications (ISAC) is recognized as a key enabling technology for future wireless networks. To shed light on the fundamental performance limits of ISAC systems, this paper studies the deterministic-random tradeoff between sensing and communications (S&C) from a rate-distortion perspective under vector Gaussian channels. We model the ISAC signal as a random matrix that carries information, whose realization is perfectly known to the sensing receiver, but is unknown to the communication receiver. We characterize the sensing mutual information conditioned on the random ISAC signal, and show that it provides a universal lower bound for distortion metrics of sensing. Furthermore, we prove that the distortion lower bound is minimized if the sample covariance matrix of the ISAC signal is deterministic. We then offer our understanding of the main results by interpreting wireless sensing as non-cooperative source-channel coding, and reveal the deterministic-random tradeoff of S&C for ISAC systems. Finally, we provide sufficient conditions for the achievability of the distortion bound by analyzing a specific example of target response matrix estimation.
A New Design of Cache-aided Multiuser Private Information Retrieval with Uncoded Prefetching
Feb 03, 2021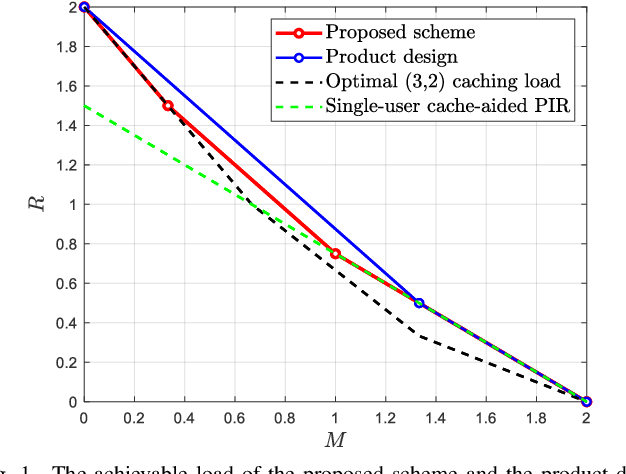
In the problem of cache-aided multiuser private information retrieval (MuPIR), a set of $K_{\rm u}$ cache-equipped users wish to privately download a set of messages from $N$ distributed databases each holding a library of $K$ messages. The system works in two phases: {\it cache placement (prefetching) phase} in which the users fill up their cache memory, and {\it private delivery phase} in which the users' demands are revealed and they download an answer from each database so that the their desired messages can be recovered while each individual database learns nothing about the identities of the requested messages. The goal is to design the placement and the private delivery phases such that the \emph{load}, which is defined as the total number of downloaded bits normalized by the message size, is minimized given any user memory size. This paper considers the MuPIR problem with two messages, arbitrary number of users and databases where uncoded prefetching is assumed, i.e., the users directly copy some bits from the library as their cached contents. We propose a novel MuPIR scheme inspired by the Maddah-Ali and Niesen (MAN) coded caching scheme. The proposed scheme achieves lower load than any existing schemes, especially the product design (PD), and is shown to be optimal within a factor of $8$ in general and exactly optimal at very high or low memory regime.