 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPO-VAE: Modeling Explainable Gene Perturbation Responses utilizing GRN-Aligned Parameter Optimization
Jan 31, 2025Motivation: Predicting cellular responses to genetic perturbations is essential for understanding biological systems and developing targeted therapeutic strategies. While variational autoencoders (VAEs) have shown promise in modeling perturbation responses, their limited explainability poses a significant challenge, as the learned features often lack clear biological meaning. Nevertheless, model explainability is one of the most important aspects in the realm of biological AI. One of the most effective ways to achieve explainability is incorporating the concept of gene regulatory networks (GRNs) in designing deep learning models such as VAEs. GRNs elicit the underlying causal relationships between genes and are capable of explaining the transcriptional responses caused by genetic perturbation treatments. Results: We propose GPO-VAE, an explainable VAE enhanced by GRN-aligned Parameter Optimization that explicitly models gene regulatory networks in the latent space. Our key approach is to optimize the learnable parameters related to latent perturbation effects towards GRN-aligned explainability. Experimental results on perturbation prediction show our model achieves state-of-the-art performance in predicting transcriptional responses across multiple benchmark datasets. Furthermore, additional results on evaluating the GRN inference task reveal our model's ability to generate meaningful GRNs compared to other methods. According to qualitative analysis, GPO-VAE posseses the ability to construct biologically explainable GRNs that align with experimentally validated regulatory pathways. GPO-VAE is available at https://github.com/dmis-lab/GPO-VAE
Culinary Class Wars: Evaluating LLMs using ASH in Cuisine Transfer Task
Nov 04, 2024
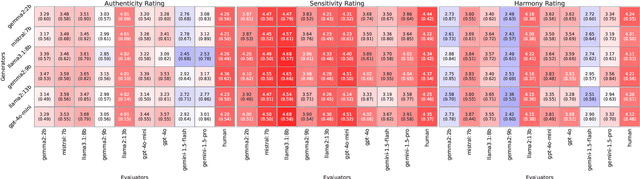
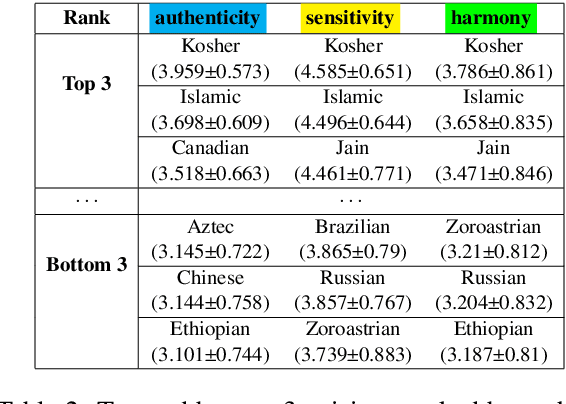
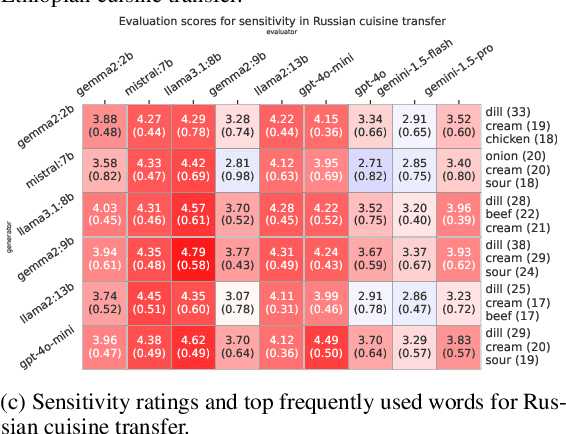
The advent of Large Language Models (LLMs) have shown promise in various creative domains, including culinary arts. However, many LLMs still struggle to deliver the desired level of culinary creativity, especially when tasked with adapting recipes to meet specific cultural requirements. This study focuses on cuisine transfer-applying elements of one cuisine to another-to assess LLMs' culinary creativity. We employ a diverse set of LLMs to generate and evaluate culturally adapted recipes, comparing their evaluations against LLM and human judgments. We introduce the ASH (authenticity, sensitivity, harmony) benchmark to evaluate LLMs' recipe generation abilities in the cuisine transfer task, assessing their cultural accuracy and creativity in the culinary domain. Our findings reveal crucial insights into both generative and evaluative capabilities of LLMs in the culinary domain, highlighting strengths and limitations in understanding and applying cultural nuances in recipe creation. The code and dataset used in this project will be openly available in \url{http://github.com/dmis-lab/CulinaryASH}.
CRADLE-VAE: Enhancing Single-Cell Gene Perturbation Modeling with Counterfactual Reasoning-based Artifact Disentanglement
Sep 10, 2024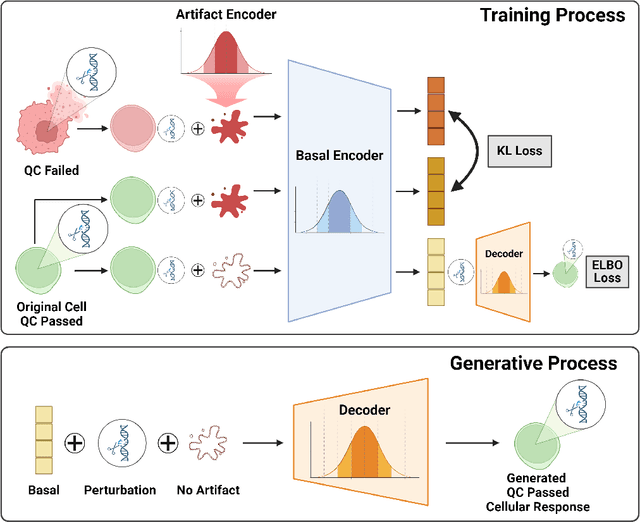
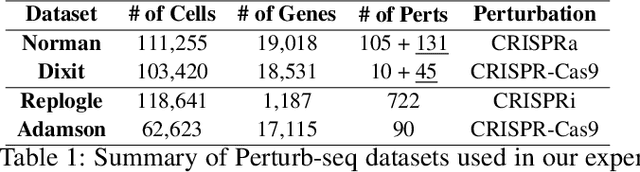
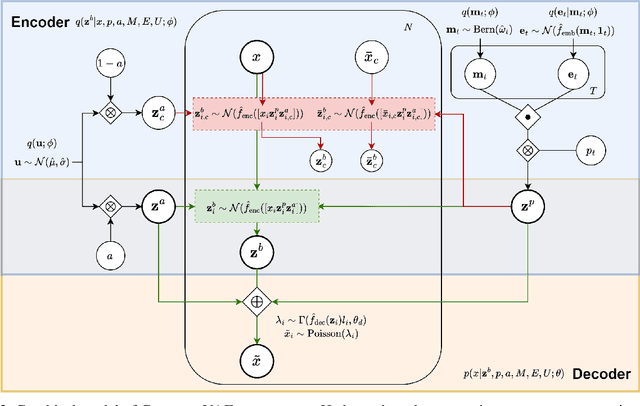
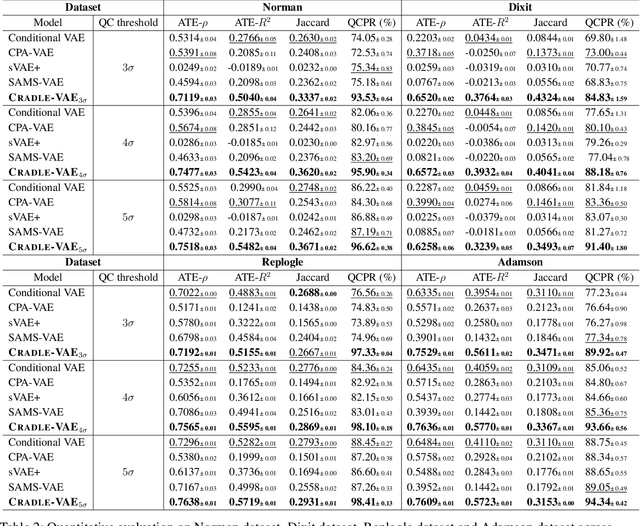
Predicting cellular responses to various perturbations is a critical focus in drug discovery and personalized therapeutics, with deep learning models playing a significant role in this endeavor. Single-cell datasets contain technical artifacts that may hinder the predictability of such models, which poses quality control issues highly regarded in this area. To address this, we propose CRADLE-VAE, a causal generative framework tailored for single-cell gene perturbation modeling, enhanced with counterfactual reasoning-based artifact disentanglement. Throughout training, CRADLE-VAE models the underlying latent distribution of technical artifacts and perturbation effects present in single-cell datasets. It employs counterfactual reasoning to effectively disentangle such artifacts by modulating the latent basal spaces and learns robust features for generating cellular response data with improved quality. Experimental results demonstrate that this approach improves not only treatment effect estimation performance but also generative quality as well. The CRADLE-VAE codebase is publicly available at https://github.com/dmis-lab/CRADLE-VAE.
LAPIS: Language Model-Augmented Police Investigation System
Jul 31, 2024Crime situations are race against time. An AI-assisted criminal investigation system, providing prompt but precise legal counsel is in need for police officers. We introduce LAPIS (Language Model Augmented Police Investigation System), an automated system that assists police officers to perform rational and legal investigative actions. We constructed a finetuning dataset and retrieval knowledgebase specialized in crime investigation legal reasoning task. We extended the dataset's quality by incorporating manual curation efforts done by a group of domain experts. We then finetuned the pretrained weights of a smaller Korean language model to the newly constructed dataset and integrated it with the crime investigation knowledgebase retrieval approach. Experimental results show LAPIS' potential in providing reliable legal guidance for police officers, even better than the proprietary GPT-4 model. Qualitative analysis on the rationales generated by LAPIS demonstrate the model's reasoning ability to leverage the premises and derive legally correct conclusions.
DeepClair: Utilizing Market Forecasts for Effective Portfolio Selection
Jul 18, 2024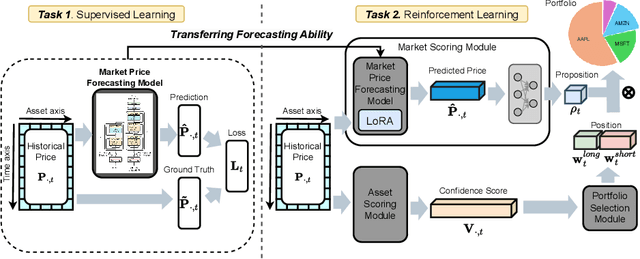

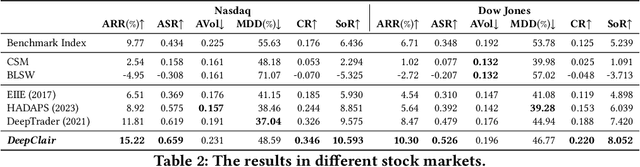
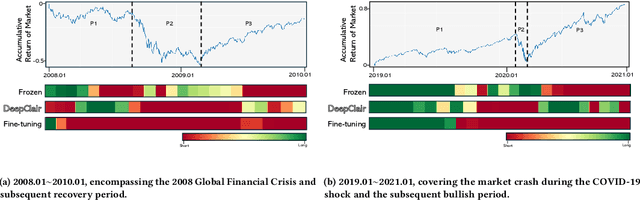
Utilizing market forecasts is pivotal in optimizing portfolio selection strategies. We introduce DeepClair, a novel framework for portfolio selection. DeepClair leverages a transformer-based time-series forecasting model to predict market trends, facilitating more informed and adaptable portfolio decisions. To integrate the forecasting model into a deep reinforcement learning-driven portfolio selection framework, we introduced a two-step strategy: first, pre-training the time-series model on market data, followed by fine-tuning the portfolio selection architecture using this model. Additionally, we investigated the optimization technique, Low-Rank Adaptation (LoRA), to enhance the pre-trained forecasting model for fine-tuning in investment scenarios. This work bridges market forecasting and portfolio selection, facilitating the advancement of investment strategies.
CookingSense: A Culinary Knowledgebase with Multidisciplinary Assertions
May 01, 2024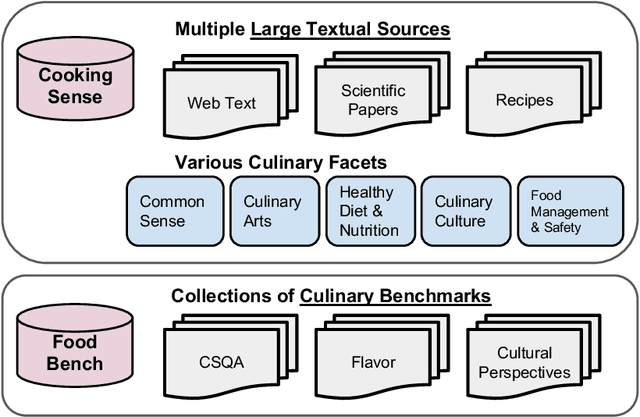

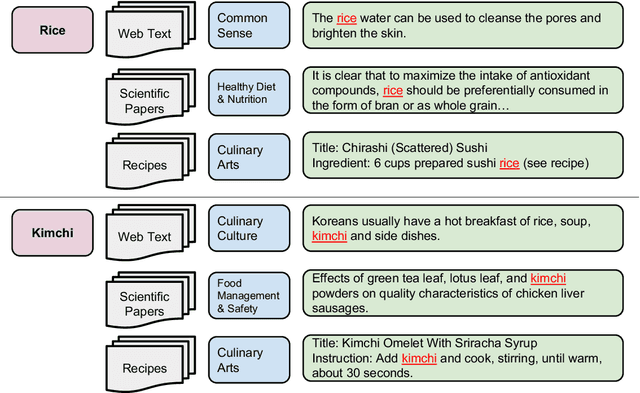
This paper introduces CookingSense, a descriptive collection of knowledge assertions in the culinary domain extracted from various sources, including web data, scientific papers, and recipes, from which knowledge covering a broad range of aspects is acquired. CookingSense is constructed through a series of dictionary-based filtering and language model-based semantic filtering techniques, which results in a rich knowledgebase of multidisciplinary food-related assertions. Additionally, we present FoodBench, a novel benchmark to evaluate culinary decision support systems. From evaluations with FoodBench, we empirically prove that CookingSense improves the performance of retrieval augmented language models. We also validate the quality and variety of assertions in CookingSense through qualitative analysis.
MolPLA: A Molecular Pretraining Framework for Learning Cores, R-Groups and their Linker Joints
Jan 30, 2024Molecular core structures and R-groups are essential concepts in drug development. Integration of these concepts with conventional graph pre-training approaches can promote deeper understanding in molecules. We propose MolPLA, a novel pre-training framework that employs masked graph contrastive learning in understanding the underlying decomposable parts inmolecules that implicate their core structure and peripheral R-groups. Furthermore, we formulate an additional framework that grants MolPLA the ability to help chemists find replaceable R-groups in lead optimization scenarios. Experimental results on molecular property prediction show that MolPLA exhibits predictability comparable to current state-of-the-art models. Qualitative analysis implicate that MolPLA is capable of distinguishing core and R-group sub-structures, identifying decomposable regions in molecules and contributing to lead optimization scenarios by rationally suggesting R-group replacements given various query core templates. The code implementation for MolPLA and its pre-trained model checkpoint is available at https://github.com/dmis-lab/MolPLA
KitchenScale: Learning to predict ingredient quantities from recipe contexts
Apr 21, 2023Determining proper quantities for ingredients is an essential part of cooking practice from the perspective of enriching tastiness and promoting healthiness. We introduce KitchenScale, a fine-tuned Pre-trained Language Model (PLM) that predicts a target ingredient's quantity and measurement unit given its recipe context. To effectively train our KitchenScale model, we formulate an ingredient quantity prediction task that consists of three sub-tasks which are ingredient measurement type classification, unit classification, and quantity regression task. Furthermore, we utilized transfer learning of cooking knowledge from recipe texts to PLMs. We adopted the Discrete Latent Exponent (DExp) method to cope with high variance of numerical scales in recipe corpora. Experiments with our newly constructed dataset and recommendation examples demonstrate KitchenScale's understanding of various recipe contexts and generalizability in predicting ingredient quantities. We implemented a web application for KitchenScale to demonstrate its functionality in recommending ingredient quantities expressed in numerals (e.g., 2) with units (e.g., ounce).
* Expert Systems with Applications 2023, Demo: http://kitchenscale.korea.ac.kr/
RecipeMind: Guiding Ingredient Choices from Food Pairing to Recipe Completion using Cascaded Set Transformer
Oct 14, 2022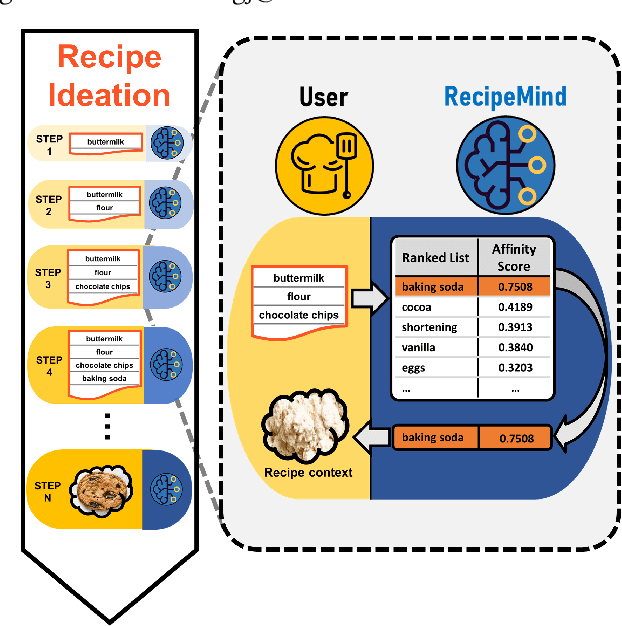
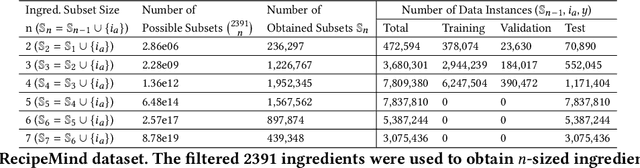
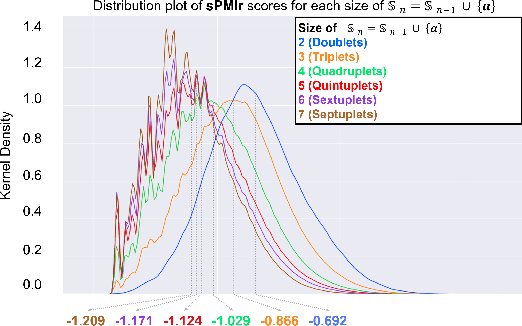
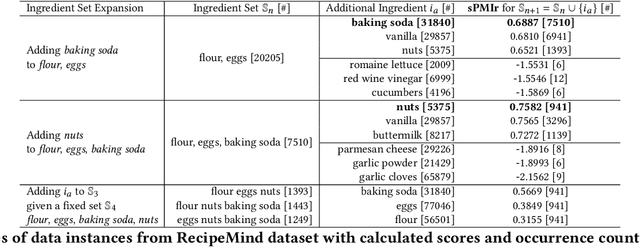
We propose a computational approach for recipe ideation, a downstream task that helps users select and gather ingredients for creating dishes. To perform this task, we developed RecipeMind, a food affinity score prediction model that quantifies the suitability of adding an ingredient to set of other ingredients. We constructed a large-scale dataset containing ingredient co-occurrence based scores to train and evaluate RecipeMind on food affinity score prediction. Deployed in recipe ideation, RecipeMind helps the user expand an initial set of ingredients by suggesting additional ingredients. Experiments and qualitative analysis show RecipeMind's potential in fulfilling its assistive role in cuisine domain.