 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Tokenization: Fundamental Trade-offs in Graph Tokenization for Transformers
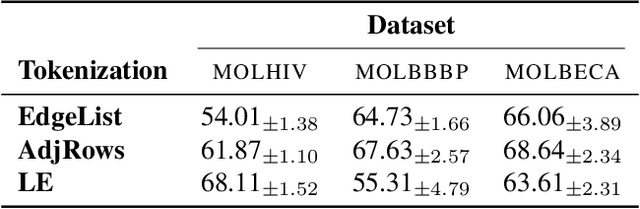
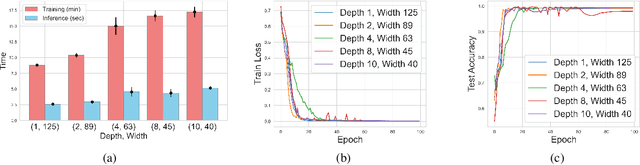
May 21, 2026Transformers have become a central architecture for graph learning, but their application to graphs requires first choosing a tokenization: a graph-to-token map that determines which structural information is exposed at the input. In this work, we show that this choice is a fundamental component of transformer expressivity. We examine three tokenizations that serve as building blocks for many existing graph tokenizations: spectral, random-walk, and adjacency tokenizations. We prove that different tokenizations induce distinct depth regimes: the same graph computation may be realizable by a shallow transformer under one tokenization, while requiring substantially larger depth under another. For example, we prove that random-walk tokenization is lossy for any walk length, making it impossible in general to recover the graph from it, and that while spectral tokenization is lossless, it is ill-conditioned for local tasks. We further show that although both random-walk and spectral tokenizations are derived from adjacency information, it is impossible for a limited-depth transformer to convert between tokenization families in general. In particular, we establish lower bounds and impossibility results showing that unfavorable tokenizations may preclude the efficient recovery of more suitable structural representations. Finally, we complement our theory with controlled experiments on synthetic and real-world tasks, validating the predicted separations and showing that different tasks favor different structural views, and combining complementary tokenizations allows the transformer to leverage distinct signals from each representation.
Next-Token Prediction and Regret Minimization
Mar 30, 2026We consider the question of how to employ next-token prediction algorithms in adversarial online decision-making environments. Specifically, if we train a next-token prediction model on a distribution $\mathcal{D}$ over sequences of opponent actions, when is it the case that the induced online decision-making algorithm (by approximately best responding to the model's predictions) has low adversarial regret (i.e., when is $\mathcal{D}$ a \emph{low-regret distribution})? For unbounded context windows (where the prediction made by the model can depend on all the actions taken by the adversary thus far), we show that although not every distribution $\mathcal{D}$ is a low-regret distribution, every distribution $\mathcal{D}$ is exponentially close (in TV distance) to one low-regret distribution, and hence sublinear regret can always be achieved at negligible cost to the accuracy of the original next-token prediction model. In contrast to this, for bounded context windows (where the prediction made by the model can depend only on the past $w$ actions taken by the adversary, as may be the case in modern transformer architectures), we show that there are some distributions $\mathcal{D}$ of opponent play that are $Θ(1)$-far from any low-regret distribution $\mathcal{D'}$ (even when $w = Ω(T)$ and such distributions exist). Finally, we complement these results by showing that the unbounded context robustification procedure can be implemented by layers of a standard transformer architecture, and provide empirical evidence that transformer models can be efficiently trained to represent these new low-regret distributions.
Fast attention mechanisms: a tale of parallelism
Sep 10, 2025Transformers have the representational capacity to simulate Massively Parallel Computation (MPC) algorithms, but they suffer from quadratic time complexity, which severely limits their scalability. We introduce an efficient attention mechanism called Approximate Nearest Neighbor Attention (ANNA) with sub-quadratic time complexity. We prove that ANNA-transformers (1) retain the expressive power previously established for standard attention in terms of matching the capabilities of MPC algorithms, and (2) can solve key reasoning tasks such as Match2 and $k$-hop with near-optimal depth. Using the MPC framework, we further prove that constant-depth ANNA-transformers can simulate constant-depth low-rank transformers, thereby providing a unified way to reason about a broad class of efficient attention approximations.
When Do Transformers Outperform Feedforward and Recurrent Networks? A Statistical Perspective
Mar 14, 2025Theoretical efforts to prove advantages of Transformers in comparison with classical architectures such as feedforward and recurrent neural networks have mostly focused on representational power. In this work, we take an alternative perspective and prove that even with infinite compute, feedforward and recurrent networks may suffer from larger sample complexity compared to Transformers, as the latter can adapt to a form of dynamic sparsity. Specifically, we consider a sequence-to-sequence data generating model on sequences of length $N$, in which the output at each position depends only on $q$ relevant tokens with $q \ll N$, and the positions of these tokens are described in the input prompt. We prove that a single-layer Transformer can learn this model if and only if its number of attention heads is at least $q$, in which case it achieves a sample complexity almost independent of $N$, while recurrent networks require $N^{\Omega(1)}$ samples on the same problem. If we simplify this model, recurrent networks may achieve a complexity almost independent of $N$, while feedforward networks still require $N$ samples. Consequently, our proposed sparse retrieval model illustrates a natural hierarchy in sample complexity across these architectures.
Depth-Width tradeoffs in Algorithmic Reasoning of Graph Tasks with Transformers
Mar 03, 2025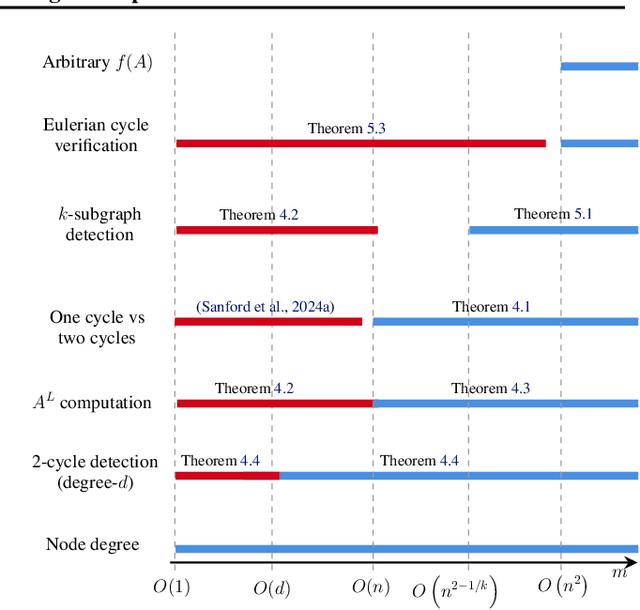

Transformers have revolutionized the field of machine learning. In particular, they can be used to solve complex algorithmic problems, including graph-based tasks. In such algorithmic tasks a key question is what is the minimal size of a transformer that can implement a task. Recent work has begun to explore this problem for graph-based tasks, showing that for sub-linear embedding dimension (i.e., model width) logarithmic depth suffices. However, an open question, which we address here, is what happens if width is allowed to grow linearly. Here we analyze this setting, and provide the surprising result that with linear width, constant depth suffices for solving a host of graph-based problems. This suggests that a moderate increase in width can allow much shallower models, which are advantageous in terms of inference time. For other problems, we show that quadratic width is required. Our results demonstrate the complex and intriguing landscape of transformer implementations of graph-based algorithms. We support our theoretical results with empirical evaluations.
Best of Both Worlds: Advantages of Hybrid Graph Sequence Models
Nov 23, 2024Modern sequence models (e.g., Transformers, linear RNNs, etc.) emerged as dominant backbones of recent deep learning frameworks, mainly due to their efficiency, representational power, and/or ability to capture long-range dependencies. Adopting these sequence models for graph-structured data has recently gained popularity as the alternative to Message Passing Neural Networks (MPNNs). There is, however, a lack of a common foundation about what constitutes a good graph sequence model, and a mathematical description of the benefits and deficiencies in adopting different sequence models for learning on graphs. To this end, we first present Graph Sequence Model (GSM), a unifying framework for adopting sequence models for graphs, consisting of three main steps: (1) Tokenization, which translates the graph into a set of sequences; (2) Local Encoding, which encodes local neighborhoods around each node; and (3) Global Encoding, which employs a scalable sequence model to capture long-range dependencies within the sequences. This framework allows us to understand, evaluate, and compare the power of different sequence model backbones in graph tasks. Our theoretical evaluations of the representation power of Transformers and modern recurrent models through the lens of global and local graph tasks show that there are both negative and positive sides for both types of models. Building on this observation, we present GSM++, a fast hybrid model that uses the Hierarchical Affinity Clustering (HAC) algorithm to tokenize the graph into hierarchical sequences, and then employs a hybrid architecture of Transformer to encode these sequences. Our theoretical and experimental results support the design of GSM++, showing that GSM++ outperforms baselines in most benchmark evaluations.
One-layer transformers fail to solve the induction heads task
Aug 26, 2024A simple communication complexity argument proves that no one-layer transformer can solve the induction heads task unless its size is exponentially larger than the size sufficient for a two-layer transformer.
Understanding Transformer Reasoning Capabilities via Graph Algorithms
May 28, 2024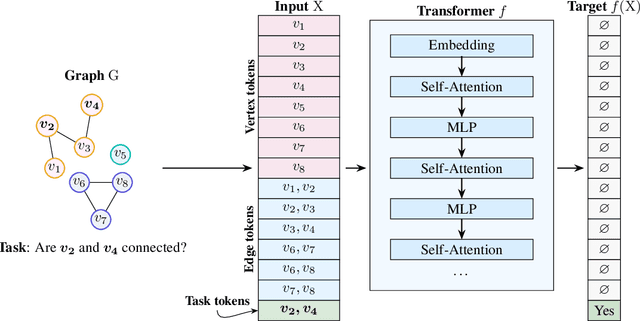

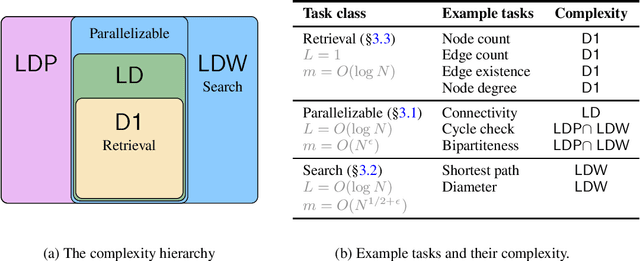
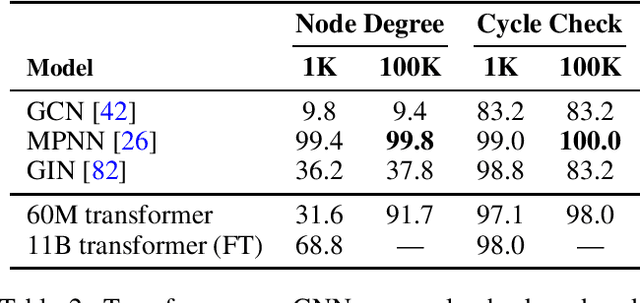
Which transformer scaling regimes are able to perfectly solve different classes of algorithmic problems? While tremendous empirical advances have been attained by transformer-based neural networks, a theoretical understanding of their algorithmic reasoning capabilities in realistic parameter regimes is lacking. We investigate this question in terms of the network's depth, width, and number of extra tokens for algorithm execution. Our novel representational hierarchy separates 9 algorithmic reasoning problems into classes solvable by transformers in different realistic parameter scaling regimes. We prove that logarithmic depth is necessary and sufficient for tasks like graph connectivity, while single-layer transformers with small embedding dimensions can solve contextual retrieval tasks. We also support our theoretical analysis with ample empirical evidence using the GraphQA benchmark. These results show that transformers excel at many graph reasoning tasks, even outperforming specialized graph neural networks.
Transformers, parallel computation, and logarithmic depth
Feb 14, 2024We show that a constant number of self-attention layers can efficiently simulate, and be simulated by, a constant number of communication rounds of Massively Parallel Computation. As a consequence, we show that logarithmic depth is sufficient for transformers to solve basic computational tasks that cannot be efficiently solved by several other neural sequence models and sub-quadratic transformer approximations. We thus establish parallelism as a key distinguishing property of transformers.
Representational Strengths and Limitations of Transformers
Jun 05, 2023



Attention layers, as commonly used in transformers, form the backbone of modern deep learning, yet there is no mathematical description of their benefits and deficiencies as compared with other architectures. In this work we establish both positive and negative results on the representation power of attention layers, with a focus on intrinsic complexity parameters such as width, depth, and embedding dimension. On the positive side, we present a sparse averaging task, where recurrent networks and feedforward networks all have complexity scaling polynomially in the input size, whereas transformers scale merely logarithmically in the input size; furthermore, we use the same construction to show the necessity and role of a large embedding dimension in a transformer. On the negative side, we present a triple detection task, where attention layers in turn have complexity scaling linearly in the input size; as this scenario seems rare in practice, we also present natural variants that can be efficiently solved by attention layers. The proof techniques emphasize the value of communication complexity in the analysis of transformers and related models, and the role of sparse averaging as a prototypical attention task, which even finds use in the analysis of triple detection.