 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNested Learning: The Illusion of Deep Learning Architectures
Dec 31, 2025Despite the recent progresses, particularly in developing Language Models, there are fundamental challenges and unanswered questions about how such models can continually learn/memorize, self-improve, and find effective solutions. In this paper, we present a new learning paradigm, called Nested Learning (NL), that coherently represents a machine learning model with a set of nested, multi-level, and/or parallel optimization problems, each of which with its own context flow. Through the lenses of NL, existing deep learning methods learns from data through compressing their own context flow, and in-context learning naturally emerges in large models. NL suggests a philosophy to design more expressive learning algorithms with more levels, resulting in higher-order in-context learning and potentially unlocking effective continual learning capabilities. We advocate for NL by presenting three core contributions: (1) Expressive Optimizers: We show that known gradient-based optimizers, such as Adam, SGD with Momentum, etc., are in fact associative memory modules that aim to compress the gradients' information (by gradient descent). Building on this insight, we present other more expressive optimizers with deep memory and/or more powerful learning rules; (2) Self-Modifying Learning Module: Taking advantage of NL's insights on learning algorithms, we present a sequence model that learns how to modify itself by learning its own update algorithm; and (3) Continuum Memory System: We present a new formulation for memory system that generalizes the traditional viewpoint of long/short-term memory. Combining our self-modifying sequence model with the continuum memory system, we present a continual learning module, called Hope, showing promising results in language modeling, knowledge incorporation, and few-shot generalization tasks, continual learning, and long-context reasoning tasks.
Trellis: Learning to Compress Key-Value Memory in Attention Models
Dec 29, 2025Transformers, while powerful, suffer from quadratic computational complexity and the ever-growing Key-Value (KV) cache of the attention mechanism. This paper introduces Trellis, a novel Transformer architecture with bounded memory that learns how to compress its key-value memory dynamically at test time. Trellis replaces the standard KV cache with a fixed-size memory and train a two-pass recurrent compression mechanism to store new keys and values into memory. To achieve this, it leverages an online gradient descent procedure with a forget gate, enabling the compressed memory to be updated recursively while learning to retain important contextual information from incoming tokens at test time. Extensive experiments on language modeling, common-sense reasoning, recall-intensive tasks, and time series show that the proposed architecture outperforms strong baselines. Notably, its performance gains increase as the sequence length grows, highlighting its potential for long-context applications.
MS-SSM: A Multi-Scale State Space Model for Efficient Sequence Modeling
Dec 29, 2025State-space models (SSMs) have recently attention as an efficient alternative to computationally expensive attention-based models for sequence modeling. They rely on linear recurrences to integrate information over time, enabling fast inference, parallelizable training, and control over recurrence stability. However, traditional SSMs often suffer from limited effective memory, requiring larger state sizes for improved recall. Moreover, existing SSMs struggle to capture multi-scale dependencies, which are essential for modeling complex structures in time series, images, and natural language. This paper introduces a multi-scale SSM framework that addresses these limitations by representing sequence dynamics across multiple resolution and processing each resolution with specialized state-space dynamics. By capturing both fine-grained, high-frequency patterns and coarse, global trends, MS-SSM enhances memory efficiency and long-range modeling. We further introduce an input-dependent scale-mixer, enabling dynamic information fusion across resolutions. The proposed approach significantly improves sequence modeling, particularly in long-range and hierarchical tasks, while maintaining computational efficiency. Extensive experiments on benchmarks, including Long Range Arena, hierarchical reasoning, time series classification, and image recognition, demonstrate that MS-SSM consistently outperforms prior SSM-based models, highlighting the benefits of multi-resolution processing in state-space architectures.
TNT: Improving Chunkwise Training for Test-Time Memorization
Nov 10, 2025Recurrent neural networks (RNNs) with deep test-time memorization modules, such as Titans and TTT, represent a promising, linearly-scaling paradigm distinct from Transformers. While these expressive models do not yet match the peak performance of state-of-the-art Transformers, their potential has been largely untapped due to prohibitively slow training and low hardware utilization. Existing parallelization methods force a fundamental conflict governed by the chunksize hyperparameter: large chunks boost speed but degrade performance, necessitating a fixed, suboptimal compromise. To solve this challenge, we introduce TNT, a novel training paradigm that decouples training efficiency from inference performance through a two-stage process. Stage one is an efficiency-focused pre-training phase utilizing a hierarchical memory. A global module processes large, hardware-friendly chunks for long-range context, while multiple parallel local modules handle fine-grained details. Crucially, by periodically resetting local memory states, we break sequential dependencies to enable massive context parallelization. Stage two is a brief fine-tuning phase where only the local memory modules are adapted to a smaller, high-resolution chunksize, maximizing accuracy with minimal overhead. Evaluated on Titans and TTT models, TNT achieves a substantial acceleration in training speed-up to 17 times faster than the most accurate baseline configuration - while simultaneously improving model accuracy. This improvement removes a critical scalability barrier, establishing a practical foundation for developing expressive RNNs and facilitating future work to close the performance gap with Transformers.
ATLAS: Learning to Optimally Memorize the Context at Test Time
May 29, 2025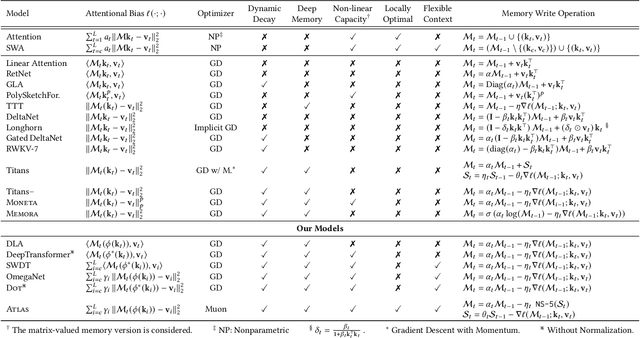
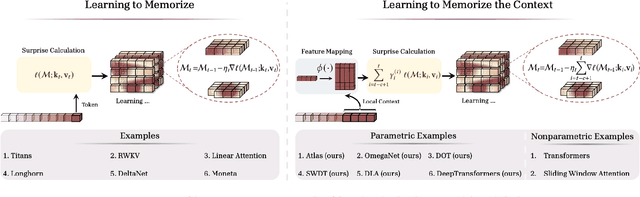
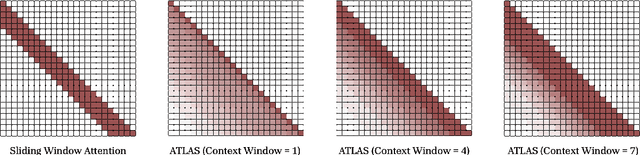
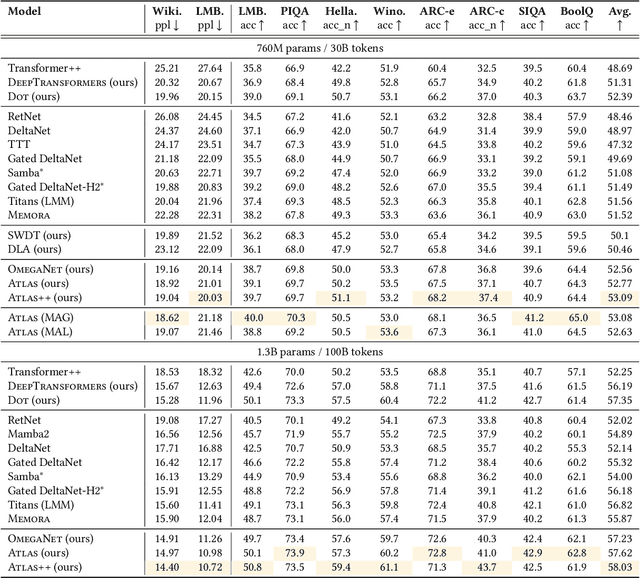
Transformers have been established as the most popular backbones in sequence modeling, mainly due to their effectiveness in in-context retrieval tasks and the ability to learn at scale. Their quadratic memory and time complexity, however, bound their applicability in longer sequences and so has motivated researchers to explore effective alternative architectures such as modern recurrent neural networks (a.k.a long-term recurrent memory module). Despite their recent success in diverse downstream tasks, they struggle in tasks that requires long context understanding and extrapolation to longer sequences. We observe that these shortcomings come from three disjoint aspects in their design: (1) limited memory capacity that is bounded by the architecture of memory and feature mapping of the input; (2) online nature of update, i.e., optimizing the memory only with respect to the last input; and (3) less expressive management of their fixed-size memory. To enhance all these three aspects, we present ATLAS, a long-term memory module with high capacity that learns to memorize the context by optimizing the memory based on the current and past tokens, overcoming the online nature of long-term memory models. Building on this insight, we present a new family of Transformer-like architectures, called DeepTransformers, that are strict generalizations of the original Transformer architecture. Our experimental results on language modeling, common-sense reasoning, recall-intensive, and long-context understanding tasks show that ATLAS surpasses the performance of Transformers and recent linear recurrent models. ATLAS further improves the long context performance of Titans, achieving +80\% accuracy in 10M context length of BABILong benchmark.
It's All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization
Apr 17, 2025Designing efficient and effective architectural backbones has been in the core of research efforts to enhance the capability of foundation models. Inspired by the human cognitive phenomenon of attentional bias-the natural tendency to prioritize certain events or stimuli-we reconceptualize neural architectures, including Transformers, Titans, and modern linear recurrent neural networks as associative memory modules that learn a mapping of keys and values using an internal objective, referred to as attentional bias. Surprisingly, we observed that most existing sequence models leverage either (1) dot-product similarity, or (2) L2 regression objectives as their attentional bias. Going beyond these objectives, we present a set of alternative attentional bias configurations along with their effective approximations to stabilize their training procedure. We then reinterpret forgetting mechanisms in modern deep learning architectures as a form of retention regularization, providing a novel set of forget gates for sequence models. Building upon these insights, we present Miras, a general framework to design deep learning architectures based on four choices of: (i) associative memory architecture, (ii) attentional bias objective, (iii) retention gate, and (iv) memory learning algorithm. We present three novel sequence models-Moneta, Yaad, and Memora-that go beyond the power of existing linear RNNs while maintaining a fast parallelizable training process. Our experiments show different design choices in Miras yield models with varying strengths. For example, certain instances of Miras achieve exceptional performance in special tasks such as language modeling, commonsense reasoning, and recall intensive tasks, even outperforming Transformers and other modern linear recurrent models.
Titans: Learning to Memorize at Test Time
Dec 31, 2024Over more than a decade there has been an extensive research effort on how to effectively utilize recurrent models and attention. While recurrent models aim to compress the data into a fixed-size memory (called hidden state), attention allows attending to the entire context window, capturing the direct dependencies of all tokens. This more accurate modeling of dependencies, however, comes with a quadratic cost, limiting the model to a fixed-length context. We present a new neural long-term memory module that learns to memorize historical context and helps attention to attend to the current context while utilizing long past information. We show that this neural memory has the advantage of fast parallelizable training while maintaining a fast inference. From a memory perspective, we argue that attention due to its limited context but accurate dependency modeling performs as a short-term memory, while neural memory due to its ability to memorize the data, acts as a long-term, more persistent, memory. Based on these two modules, we introduce a new family of architectures, called Titans, and present three variants to address how one can effectively incorporate memory into this architecture. Our experimental results on language modeling, common-sense reasoning, genomics, and time series tasks show that Titans are more effective than Transformers and recent modern linear recurrent models. They further can effectively scale to larger than 2M context window size with higher accuracy in needle-in-haystack tasks compared to baselines.
Best of Both Worlds: Advantages of Hybrid Graph Sequence Models
Nov 23, 2024Modern sequence models (e.g., Transformers, linear RNNs, etc.) emerged as dominant backbones of recent deep learning frameworks, mainly due to their efficiency, representational power, and/or ability to capture long-range dependencies. Adopting these sequence models for graph-structured data has recently gained popularity as the alternative to Message Passing Neural Networks (MPNNs). There is, however, a lack of a common foundation about what constitutes a good graph sequence model, and a mathematical description of the benefits and deficiencies in adopting different sequence models for learning on graphs. To this end, we first present Graph Sequence Model (GSM), a unifying framework for adopting sequence models for graphs, consisting of three main steps: (1) Tokenization, which translates the graph into a set of sequences; (2) Local Encoding, which encodes local neighborhoods around each node; and (3) Global Encoding, which employs a scalable sequence model to capture long-range dependencies within the sequences. This framework allows us to understand, evaluate, and compare the power of different sequence model backbones in graph tasks. Our theoretical evaluations of the representation power of Transformers and modern recurrent models through the lens of global and local graph tasks show that there are both negative and positive sides for both types of models. Building on this observation, we present GSM++, a fast hybrid model that uses the Hierarchical Affinity Clustering (HAC) algorithm to tokenize the graph into hierarchical sequences, and then employs a hybrid architecture of Transformer to encode these sequences. Our theoretical and experimental results support the design of GSM++, showing that GSM++ outperforms baselines in most benchmark evaluations.
Chimera: Effectively Modeling Multivariate Time Series with 2-Dimensional State Space Models
Jun 06, 2024



Modeling multivariate time series is a well-established problem with a wide range of applications from healthcare to financial markets. Traditional State Space Models (SSMs) are classical approaches for univariate time series modeling due to their simplicity and expressive power to represent linear dependencies. They, however, have fundamentally limited expressive power to capture non-linear dependencies, are slow in practice, and fail to model the inter-variate information flow. Despite recent attempts to improve the expressive power of SSMs by using deep structured SSMs, the existing methods are either limited to univariate time series, fail to model complex patterns (e.g., seasonal patterns), fail to dynamically model the dependencies of variate and time dimensions, and/or are input-independent. We present Chimera that uses two input-dependent 2-D SSM heads with different discretization processes to learn long-term progression and seasonal patterns. To improve the efficiency of complex 2D recurrence, we present a fast training using a new 2-dimensional parallel selective scan. We further present and discuss 2-dimensional Mamba and Mamba-2 as the spacial cases of our 2D SSM. Our experimental evaluation shows the superior performance of Chimera on extensive and diverse benchmarks, including ECG and speech time series classification, long-term and short-term time series forecasting, and time series anomaly detection.
MambaMixer: Efficient Selective State Space Models with Dual Token and Channel Selection
Mar 29, 2024Recent advances in deep learning have mainly relied on Transformers due to their data dependency and ability to learn at scale. The attention module in these architectures, however, exhibits quadratic time and space in input size, limiting their scalability for long-sequence modeling. Despite recent attempts to design efficient and effective architecture backbone for multi-dimensional data, such as images and multivariate time series, existing models are either data independent, or fail to allow inter- and intra-dimension communication. Recently, State Space Models (SSMs), and more specifically Selective State Space Models, with efficient hardware-aware implementation, have shown promising potential for long sequence modeling. Motivated by the success of SSMs, we present MambaMixer, a new architecture with data-dependent weights that uses a dual selection mechanism across tokens and channels, called Selective Token and Channel Mixer. MambaMixer connects selective mixers using a weighted averaging mechanism, allowing layers to have direct access to early features. As a proof of concept, we design Vision MambaMixer (ViM2) and Time Series MambaMixer (TSM2) architectures based on the MambaMixer block and explore their performance in various vision and time series forecasting tasks. Our results underline the importance of selective mixing across both tokens and channels. In ImageNet classification, object detection, and semantic segmentation tasks, ViM2 achieves competitive performance with well-established vision models and outperforms SSM-based vision models. In time series forecasting, TSM2 achieves outstanding performance compared to state-of-the-art methods while demonstrating significantly improved computational cost. These results show that while Transformers, cross-channel attention, and MLPs are sufficient for good performance in time series forecasting, neither is necessary.