 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal $Φ$-Regret Learning in Extensive-Form Games
Paper and Code
Aug 20, 2022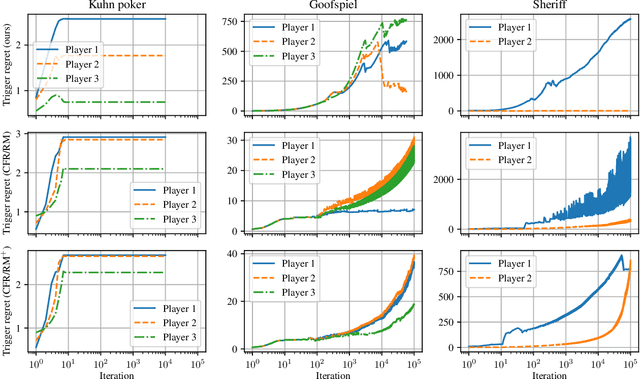

In this paper, we establish efficient and uncoupled learning dynamics so that, when employed by all players in multiplayer perfect-recall imperfect-information extensive-form games, the \emph{trigger regret} of each player grows as $O(\log T)$ after $T$ repetitions of play. This improves exponentially over the prior best known trigger-regret bound of $O(T^{1/4})$, and settles a recent open question by Bai et al. (2022). As an immediate consequence, we guarantee convergence to the set of \emph{extensive-form correlated equilibria} and \emph{coarse correlated equilibria} at a near-optimal rate of $\frac{\log T}{T}$. Building on prior work, at the heart of our construction lies a more general result regarding fixed points deriving from rational functions with \emph{polynomial degree}, a property that we establish for the fixed points of \emph{(coarse) trigger deviation functions}. Moreover, our construction leverages a refined \textit{regret circuit} for the convex hull, which -- unlike prior guarantees -- preserves the \emph{RVU property} introduced by Syrgkanis et al. (NIPS, 2015); this observation has an independent interest in establishing near-optimal regret under learning dynamics based on a CFR-type decomposition of the regret.