 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
mSTEB: Massively Multilingual Evaluation of LLMs on Speech and Text Tasks
Jun 10, 2025Large Language models (LLMs) have demonstrated impressive performance on a wide range of tasks, including in multimodal settings such as speech. However, their evaluation is often limited to English and a few high-resource languages. For low-resource languages, there is no standardized evaluation benchmark. In this paper, we address this gap by introducing mSTEB, a new benchmark to evaluate the performance of LLMs on a wide range of tasks covering language identification, text classification, question answering, and translation tasks on both speech and text modalities. We evaluated the performance of leading LLMs such as Gemini 2.0 Flash and GPT-4o (Audio) and state-of-the-art open models such as Qwen 2 Audio and Gemma 3 27B. Our evaluation shows a wide gap in performance between high-resource and low-resource languages, especially for languages spoken in Africa and Americas/Oceania. Our findings show that more investment is needed to address their under-representation in LLMs coverage.
Measuring General Intelligence with Generated Games
May 12, 2025We present gg-bench, a collection of game environments designed to evaluate general reasoning capabilities in language models. Unlike most static benchmarks, gg-bench is a data generating process where new evaluation instances can be generated at will. In particular, gg-bench is synthetically generated by (1) using a large language model (LLM) to generate natural language descriptions of novel games, (2) using the LLM to implement each game in code as a Gym environment, and (3) training reinforcement learning (RL) agents via self-play on the generated games. We evaluate language models by their winrate against these RL agents by prompting models with the game description, current board state, and a list of valid moves, after which models output the moves they wish to take. gg-bench is challenging: state-of-the-art LLMs such as GPT-4o and Claude 3.7 Sonnet achieve winrates of 7-9% on gg-bench using in-context learning, while reasoning models such as o1, o3-mini and DeepSeek-R1 achieve average winrates of 31-36%. We release the generated games, data generation process, and evaluation code in order to support future modeling work and expansion of our benchmark.
Ghostbuster: Detecting Text Ghostwritten by Large Language Models
May 24, 2023


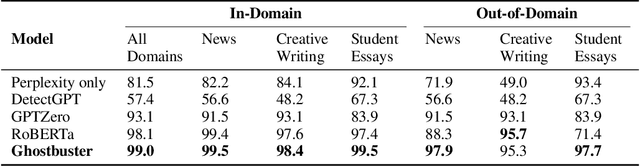
We introduce Ghostbuster, a state-of-the-art system for detecting AI-generated text. Our method works by passing documents through a series of weaker language models and running a structured search over possible combinations of their features, then training a classifier on the selected features to determine if the target document was AI-generated. Crucially, Ghostbuster does not require access to token probabilities from the target model, making it useful for detecting text generated by black-box models or unknown model versions. In conjunction with our model, we release three new datasets of human and AI-generated text as detection benchmarks that cover multiple domains (student essays, creative fiction, and news) and task setups: document-level detection, author identification, and a challenge task of paragraph-level detection. Ghostbuster averages 99.1 F1 across all three datasets on document-level detection, outperforming previous approaches such as GPTZero and DetectGPT by up to 32.7 F1.
Revisiting Entropy Rate Constancy in Text
May 20, 2023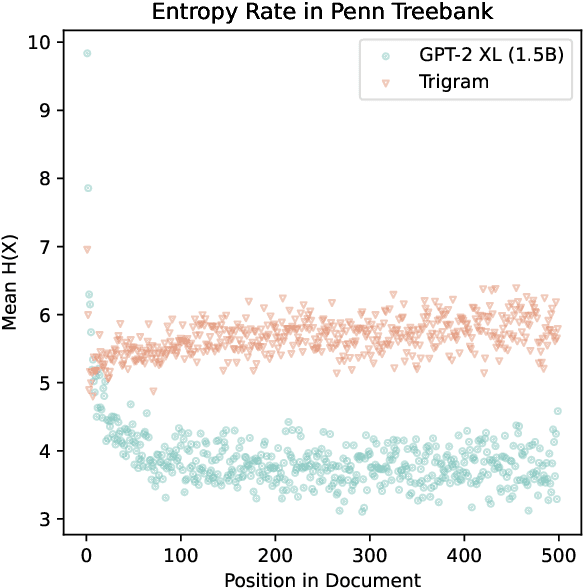



The uniform information density (UID) hypothesis states that humans tend to distribute information roughly evenly across an utterance or discourse. Early evidence in support of the UID hypothesis came from Genzel & Charniak (2002), which proposed an entropy rate constancy principle based on the probability of English text under n-gram language models. We re-evaluate the claims of Genzel & Charniak (2002) with neural language models, failing to find clear evidence in support of entropy rate constancy. We conduct a range of experiments across datasets, model sizes, and languages and discuss implications for the uniform information density hypothesis and linguistic theories of efficient communication more broadly.