 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalk&Retrieve: Simple Yet Effective Zero-shot Retrieval-Augmented Generation via Knowledge Graph Walks
May 22, 2025Large Language Models (LLMs) have showcased impressive reasoning abilities, but often suffer from hallucinations or outdated knowledge. Knowledge Graph (KG)-based Retrieval-Augmented Generation (RAG) remedies these shortcomings by grounding LLM responses in structured external information from a knowledge base. However, many KG-based RAG approaches struggle with (i) aligning KG and textual representations, (ii) balancing retrieval accuracy and efficiency, and (iii) adapting to dynamically updated KGs. In this work, we introduce Walk&Retrieve, a simple yet effective KG-based framework that leverages walk-based graph traversal and knowledge verbalization for corpus generation for zero-shot RAG. Built around efficient KG walks, our method does not require fine-tuning on domain-specific data, enabling seamless adaptation to KG updates, reducing computational overhead, and allowing integration with any off-the-shelf backbone LLM. Despite its simplicity, Walk&Retrieve performs competitively, often outperforming existing RAG systems in response accuracy and hallucination reduction. Moreover, it demonstrates lower query latency and robust scalability to large KGs, highlighting the potential of lightweight retrieval strategies as strong baselines for future RAG research.
Peeling Back the Layers: An In-Depth Evaluation of Encoder Architectures in Neural News Recommenders
Oct 02, 2024
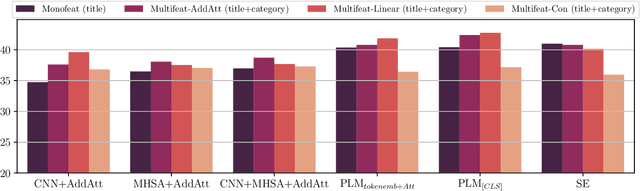
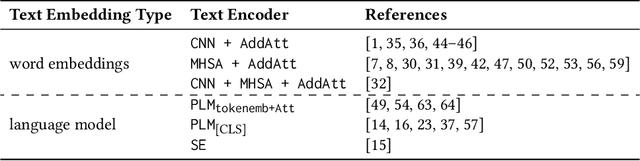
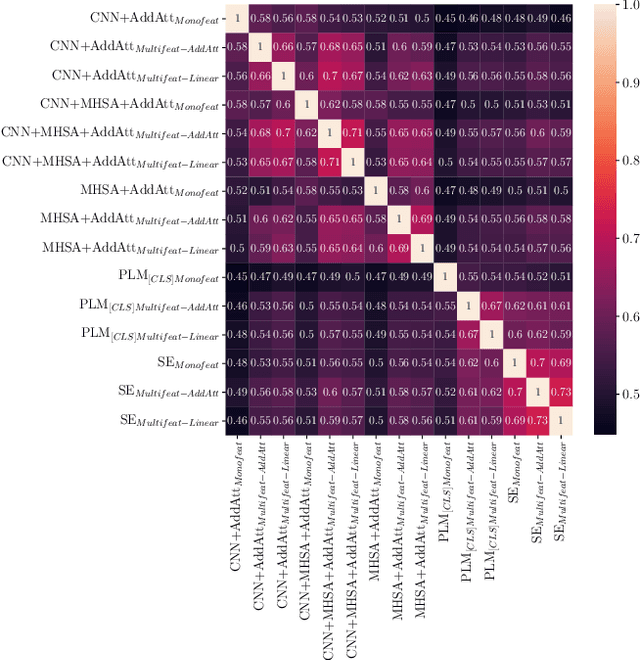
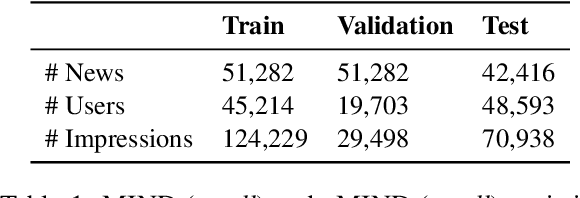
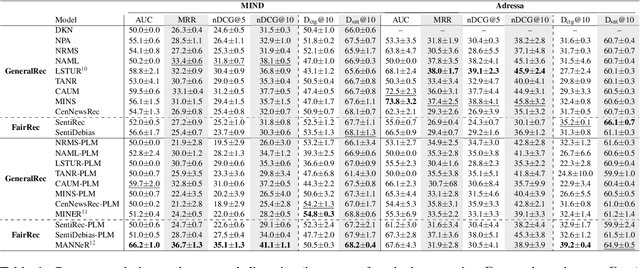
Encoder architectures play a pivotal role in neural news recommenders by embedding the semantic and contextual information of news and users. Thus, research has heavily focused on enhancing the representational capabilities of news and user encoders to improve recommender performance. Despite the significant impact of encoder architectures on the quality of news and user representations, existing analyses of encoder designs focus only on the overall downstream recommendation performance. This offers a one-sided assessment of the encoders' similarity, ignoring more nuanced differences in their behavior, and potentially resulting in sub-optimal model selection. In this work, we perform a comprehensive analysis of encoder architectures in neural news recommender systems. We systematically evaluate the most prominent news and user encoder architectures, focusing on their (i) representational similarity, measured with the Central Kernel Alignment, (ii) overlap of generated recommendation lists, quantified with the Jaccard similarity, and (iii) the overall recommendation performance. Our analysis reveals that the complexity of certain encoding techniques is often empirically unjustified, highlighting the potential for simpler, more efficient architectures. By isolating the effects of individual components, we provide valuable insights for researchers and practitioners to make better informed decisions about encoder selection and avoid unnecessary complexity in the design of news recommenders.
News Without Borders: Domain Adaptation of Multilingual Sentence Embeddings for Cross-lingual News Recommendation
Jun 18, 2024
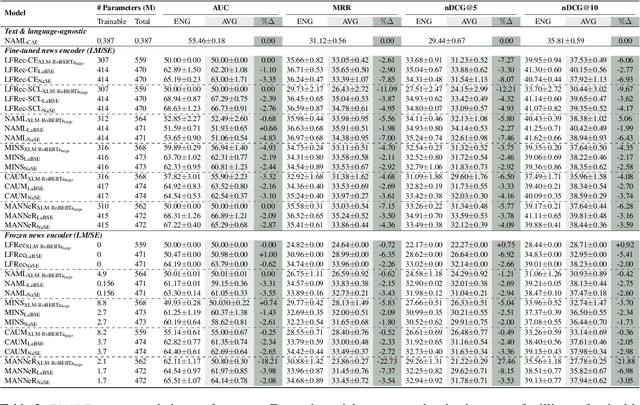
Rapidly growing numbers of multilingual news consumers pose an increasing challenge to news recommender systems in terms of providing customized recommendations. First, existing neural news recommenders, even when powered by multilingual language models (LMs), suffer substantial performance losses in zero-shot cross-lingual transfer (ZS-XLT). Second, the current paradigm of fine-tuning the backbone LM of a neural recommender on task-specific data is computationally expensive and infeasible in few-shot recommendation and cold-start setups, where data is scarce or completely unavailable. In this work, we propose a news-adapted sentence encoder (NaSE), domain-specialized from a pretrained massively multilingual sentence encoder (SE). To this end, we construct and leverage PolyNews and PolyNewsParallel, two multilingual news-specific corpora. With the news-adapted multilingual SE in place, we test the effectiveness of (i.e., question the need for) supervised fine-tuning for news recommendation, and propose a simple and strong baseline based on (i) frozen NaSE embeddings and (ii) late click-behavior fusion. We show that NaSE achieves state-of-the-art performance in ZS-XLT in true cold-start and few-shot news recommendation.
MIND Your Language: A Multilingual Dataset for Cross-lingual News Recommendation
Mar 26, 2024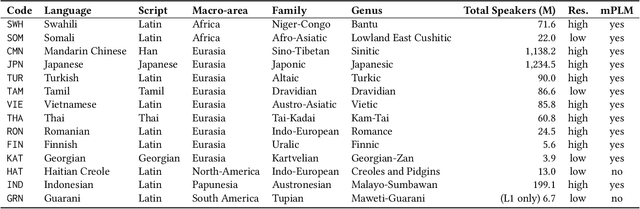
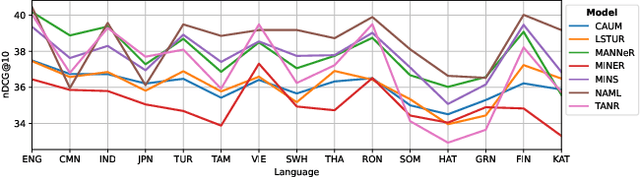
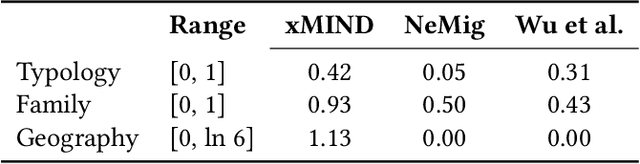
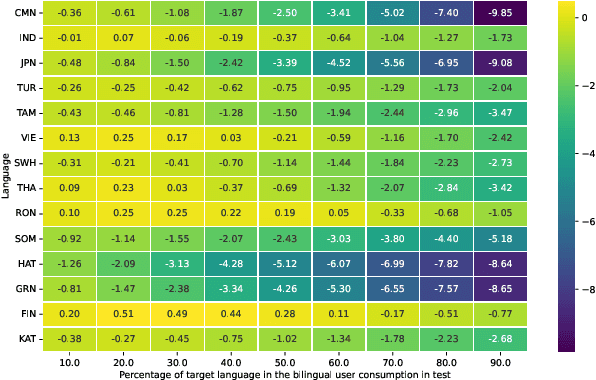
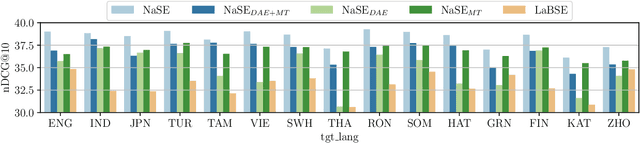
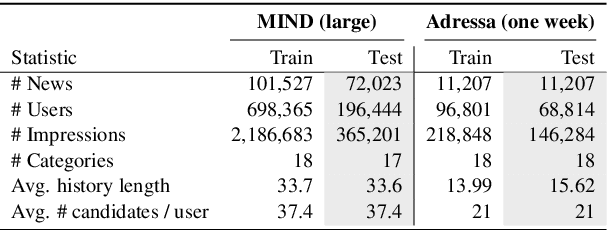
Digital news platforms use news recommenders as the main instrument to cater to the individual information needs of readers. Despite an increasingly language-diverse online community, in which many Internet users consume news in multiple languages, the majority of news recommendation focuses on major, resource-rich languages, and English in particular. Moreover, nearly all news recommendation efforts assume monolingual news consumption, whereas more and more users tend to consume information in at least two languages. Accordingly, the existing body of work on news recommendation suffers from a lack of publicly available multilingual benchmarks that would catalyze development of news recommenders effective in multilingual settings and for low-resource languages. Aiming to fill this gap, we introduce xMIND, an open, multilingual news recommendation dataset derived from the English MIND dataset using machine translation, covering a set of 14 linguistically and geographically diverse languages, with digital footprints of varying sizes. Using xMIND, we systematically benchmark several state-of-the-art content-based neural news recommenders (NNRs) in both zero-shot (ZS-XLT) and few-shot (FS-XLT) cross-lingual transfer scenarios, considering both monolingual and bilingual news consumption patterns. Our findings reveal that (i) current NNRs, even when based on a multilingual language model, suffer from substantial performance losses under ZS-XLT and that (ii) inclusion of target-language data in FS-XLT training has limited benefits, particularly when combined with a bilingual news consumption. Our findings thus warrant a broader research effort in multilingual and cross-lingual news recommendation. The xMIND dataset is available at https://github.com/andreeaiana/xMIND.
NewsRecLib: A PyTorch-Lightning Library for Neural News Recommendation
Oct 02, 2023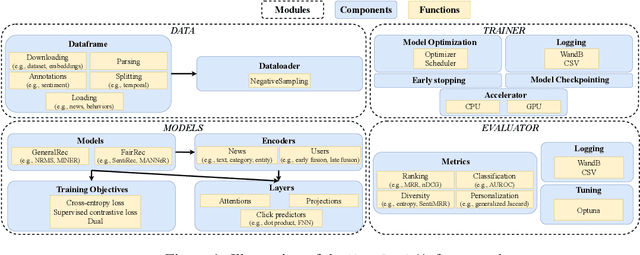
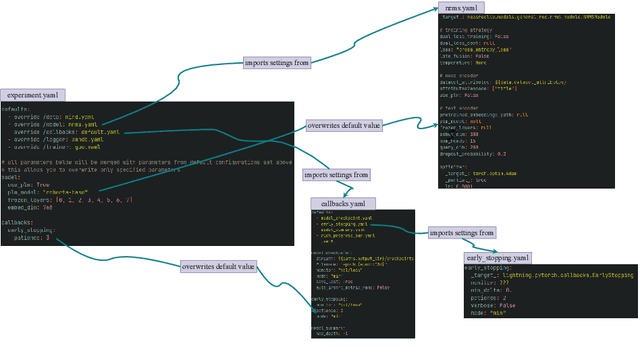
NewsRecLib is an open-source library based on Pytorch-Lightning and Hydra developed for training and evaluating neural news recommendation models. The foremost goals of NewsRecLib are to promote reproducible research and rigorous experimental evaluation by (i) providing a unified and highly configurable framework for exhaustive experimental studies and (ii) enabling a thorough analysis of the performance contribution of different model architecture components and training regimes. NewsRecLib is highly modular, allows specifying experiments in a single configuration file, and includes extensive logging facilities. Moreover, NewsRecLib provides out-of-the-box implementations of several prominent neural models, training methods, standard evaluation benchmarks, and evaluation metrics for news recommendation.
NeMig -- A Bilingual News Collection and Knowledge Graph about Migration
Sep 01, 2023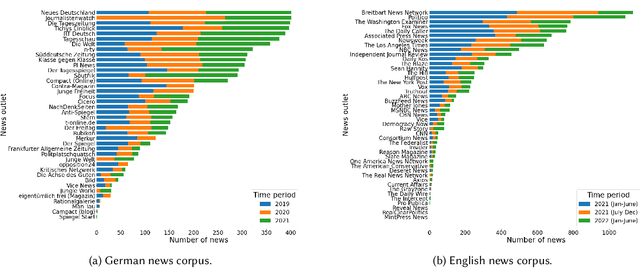

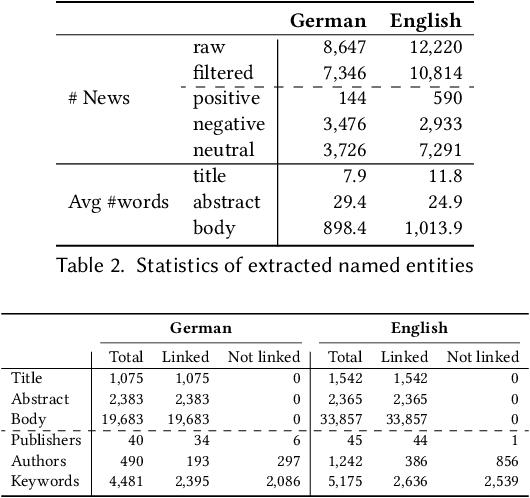
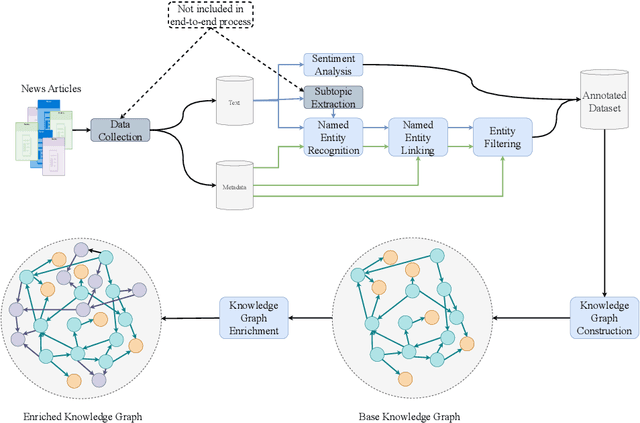
News recommendation plays a critical role in shaping the public's worldviews through the way in which it filters and disseminates information about different topics. Given the crucial impact that media plays in opinion formation, especially for sensitive topics, understanding the effects of personalized recommendation beyond accuracy has become essential in today's digital society. In this work, we present NeMig, a bilingual news collection on the topic of migration, and corresponding rich user data. In comparison to existing news recommendation datasets, which comprise a large variety of monolingual news, NeMig covers articles on a single controversial topic, published in both Germany and the US. We annotate the sentiment polarization of the articles and the political leanings of the media outlets, in addition to extracting subtopics and named entities disambiguated through Wikidata. These features can be used to analyze the effects of algorithmic news curation beyond accuracy-based performance, such as recommender biases and the creation of filter bubbles. We construct domain-specific knowledge graphs from the news text and metadata, thus encoding knowledge-level connections between articles. Importantly, while existing datasets include only click behavior, we collect user socio-demographic and political information in addition to explicit click feedback. We demonstrate the utility of NeMig through experiments on the tasks of news recommenders benchmarking, analysis of biases in recommenders, and news trends analysis. NeMig aims to provide a useful resource for the news recommendation community and to foster interdisciplinary research into the multidimensional effects of algorithmic news curation.
Train Once, Use Flexibly: A Modular Framework for Multi-Aspect Neural News Recommendation
Jul 29, 2023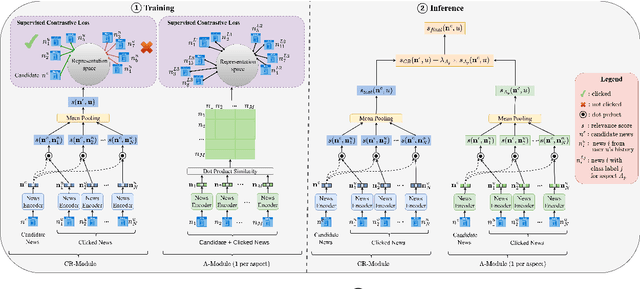
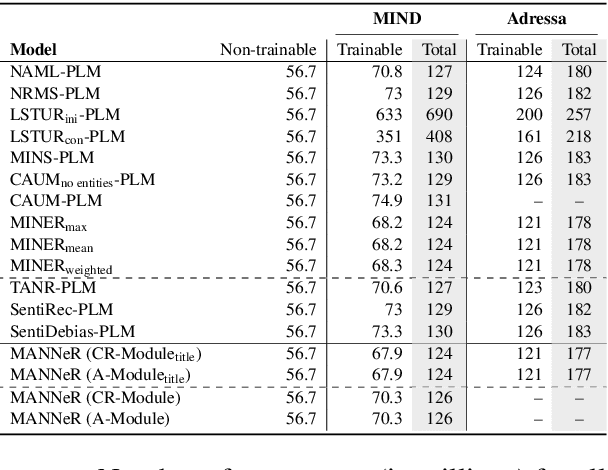
Recent neural news recommenders (NNR) extend content-based recommendation by (1) aligning additional aspects such as topic or sentiment between the candidate news and user history or (2) diversifying recommendations w.r.t. these aspects. This customization is achieved by ``hardcoding'' additional constraints into NNR's architecture and/or training objectives: any change in the desired recommendation behavior thus requires the model to be retrained with a modified objective, impeding wide adoption of multi-aspect news recommenders. In this work, we introduce MANNeR, a modular framework for flexible multi-aspect (neural) news recommendation that supports ad-hoc customization over individual aspects at inference time. With metric-based learning at its core, MANNeR obtains aspect-specialized news encoders and then flexibly combines aspect-specific similarity scores for final ranking. Evaluation on two standard news recommendation benchmarks (one in English, one in Norwegian) shows that MANNeR consistently outperforms state-of-the-art NNRs on both standard content-based recommendation and single- and multi-aspect customization. Moreover, with MANNeR we can trivially scale the importance and find the optimal trade-off between content-based recommendation performance and aspect-based diversity of recommendations. Finally, we show that both MANNeR's content-based recommendation and aspect customization are robust to domain- and language transfer.
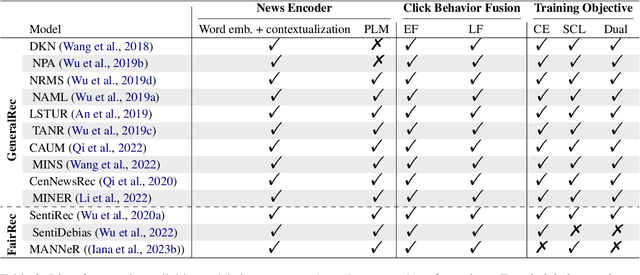
Simplifying Content-Based Neural News Recommendation: On User Modeling and Training Objectives
Apr 06, 2023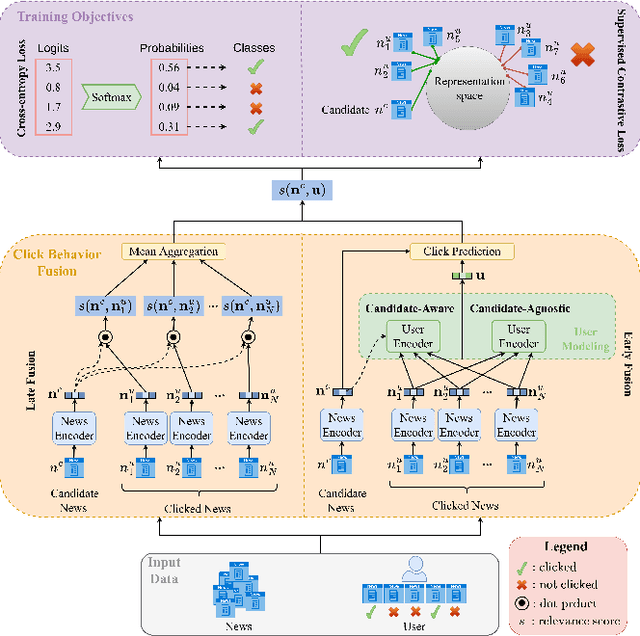
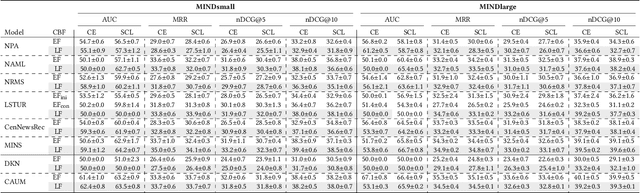
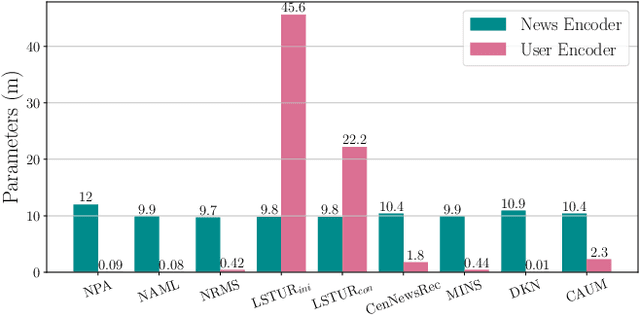
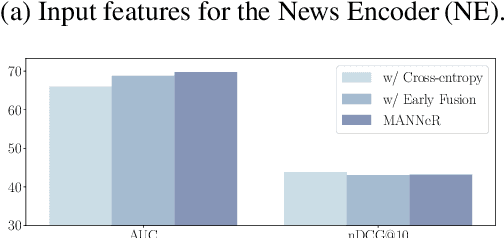
The advent of personalized news recommendation has given rise to increasingly complex recommender architectures. Most neural news recommenders rely on user click behavior and typically introduce dedicated user encoders that aggregate the content of clicked news into user embeddings (early fusion). These models are predominantly trained with standard point-wise classification objectives. The existing body of work exhibits two main shortcomings: (1) despite general design homogeneity, direct comparisons between models are hindered by varying evaluation datasets and protocols; (2) it leaves alternative model designs and training objectives vastly unexplored. In this work, we present a unified framework for news recommendation, allowing for a systematic and fair comparison of news recommenders across several crucial design dimensions: (i) candidate-awareness in user modeling, (ii) click behavior fusion, and (iii) training objectives. Our findings challenge the status quo in neural news recommendation. We show that replacing sizable user encoders with parameter-efficient dot products between candidate and clicked news embeddings (late fusion) often yields substantial performance gains. Moreover, our results render contrastive training a viable alternative to point-wise classification objectives.
Towards Analyzing the Bias of News Recommender Systems Using Sentiment and Stance Detection
Mar 11, 2022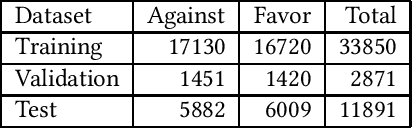

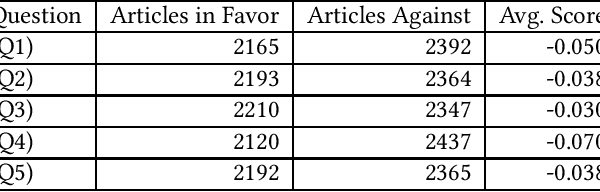
News recommender systems are used by online news providers to alleviate information overload and to provide personalized content to users. However, algorithmic news curation has been hypothesized to create filter bubbles and to intensify users' selective exposure, potentially increasing their vulnerability to polarized opinions and fake news. In this paper, we show how information on news items' stance and sentiment can be utilized to analyze and quantify the extent to which recommender systems suffer from biases. To that end, we have annotated a German news corpus on the topic of migration using stance detection and sentiment analysis. In an experimental evaluation with four different recommender systems, our results show a slight tendency of all four models for recommending articles with negative sentiments and stances against the topic of refugees and migration. Moreover, we observed a positive correlation between the sentiment and stance bias of the text-based recommenders and the preexisting user bias, which indicates that these systems amplify users' opinions and decrease the diversity of recommended news. The knowledge-aware model appears to be the least prone to such biases, at the cost of predictive accuracy.
GraphConfRec: A Graph Neural Network-Based Conference Recommender System
Jun 23, 2021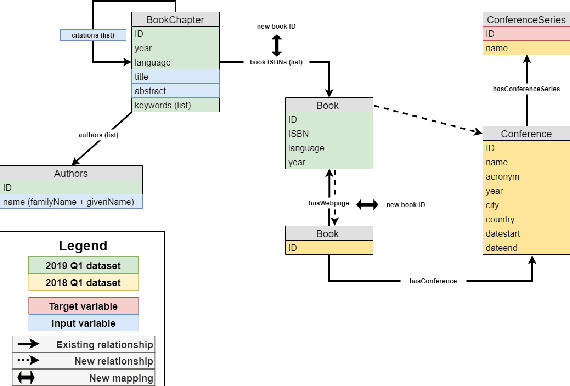
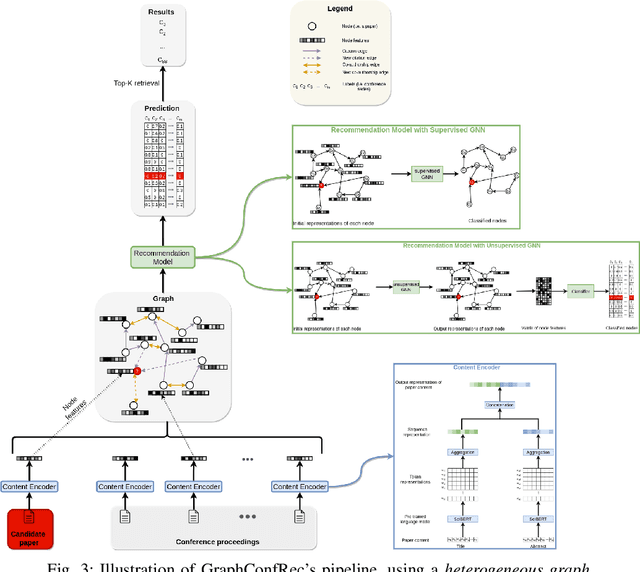
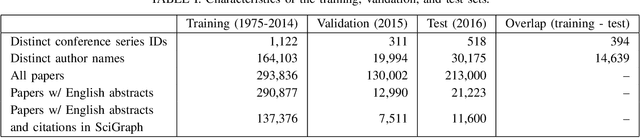
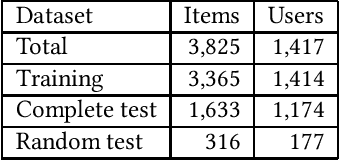
In today's academic publishing model, especially in Computer Science, conferences commonly constitute the main platforms for releasing the latest peer-reviewed advancements in their respective fields. However, choosing a suitable academic venue for publishing one's research can represent a challenging task considering the plethora of available conferences, particularly for those at the start of their academic careers, or for those seeking to publish outside of their usual domain. In this paper, we propose GraphConfRec, a conference recommender system which combines SciGraph and graph neural networks, to infer suggestions based not only on title and abstract, but also on co-authorship and citation relationships. GraphConfRec achieves a recall@10 of up to 0.580 and a MAP of up to 0.336 with a graph attention network-based recommendation model. A user study with 25 subjects supports the positive results.