 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIND Your Language: A Multilingual Dataset for Cross-lingual News Recommendation
Paper and Code
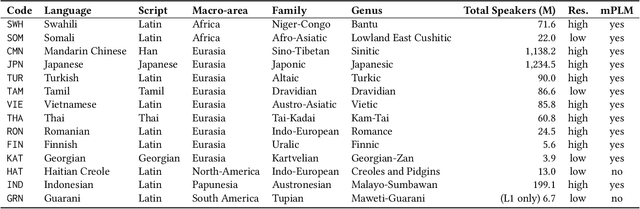
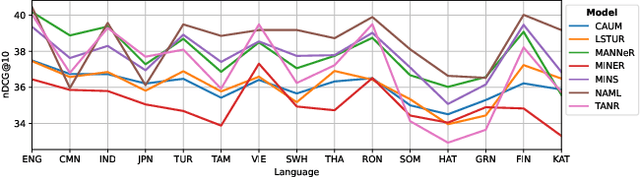
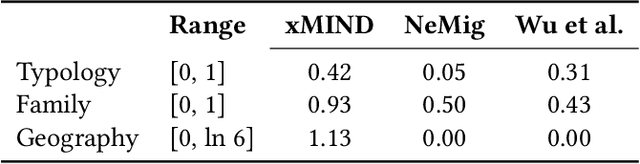
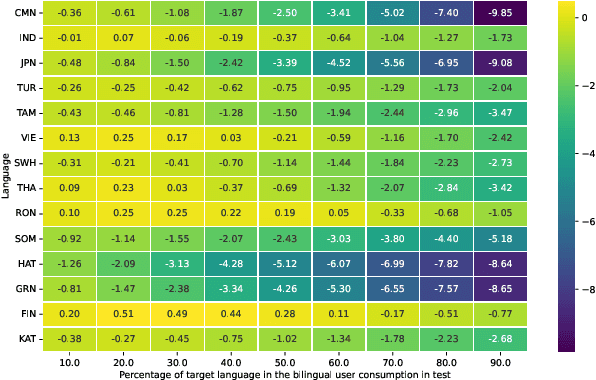
Digital news platforms use news recommenders as the main instrument to cater to the individual information needs of readers. Despite an increasingly language-diverse online community, in which many Internet users consume news in multiple languages, the majority of news recommendation focuses on major, resource-rich languages, and English in particular. Moreover, nearly all news recommendation efforts assume monolingual news consumption, whereas more and more users tend to consume information in at least two languages. Accordingly, the existing body of work on news recommendation suffers from a lack of publicly available multilingual benchmarks that would catalyze development of news recommenders effective in multilingual settings and for low-resource languages. Aiming to fill this gap, we introduce xMIND, an open, multilingual news recommendation dataset derived from the English MIND dataset using machine translation, covering a set of 14 linguistically and geographically diverse languages, with digital footprints of varying sizes. Using xMIND, we systematically benchmark several state-of-the-art content-based neural news recommenders (NNRs) in both zero-shot (ZS-XLT) and few-shot (FS-XLT) cross-lingual transfer scenarios, considering both monolingual and bilingual news consumption patterns. Our findings reveal that (i) current NNRs, even when based on a multilingual language model, suffer from substantial performance losses under ZS-XLT and that (ii) inclusion of target-language data in FS-XLT training has limited benefits, particularly when combined with a bilingual news consumption. Our findings thus warrant a broader research effort in multilingual and cross-lingual news recommendation. The xMIND dataset is available at https://github.com/andreeaiana/xMIND.