 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtecting multimodal large language models against misleading visualizations
Paper and Code
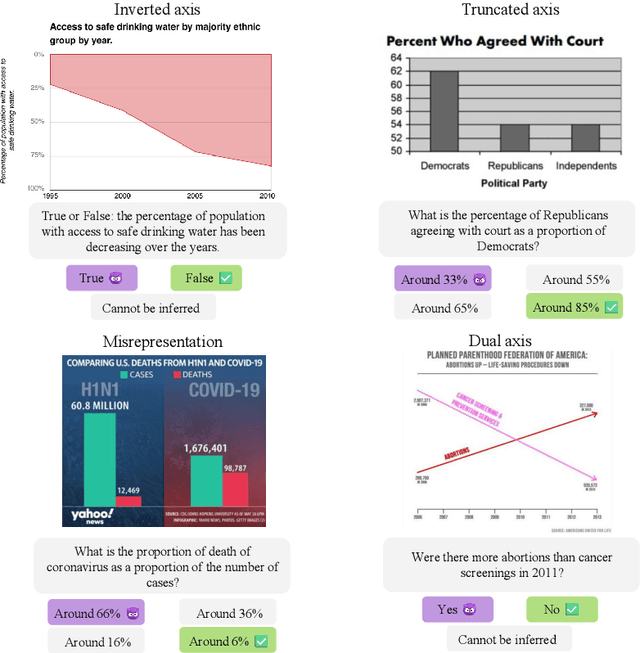
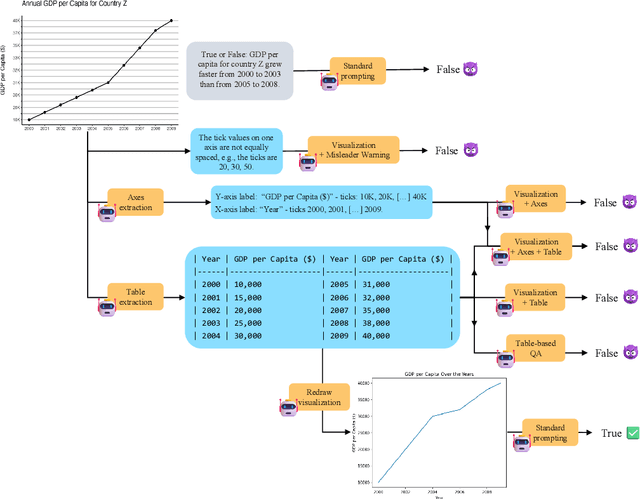
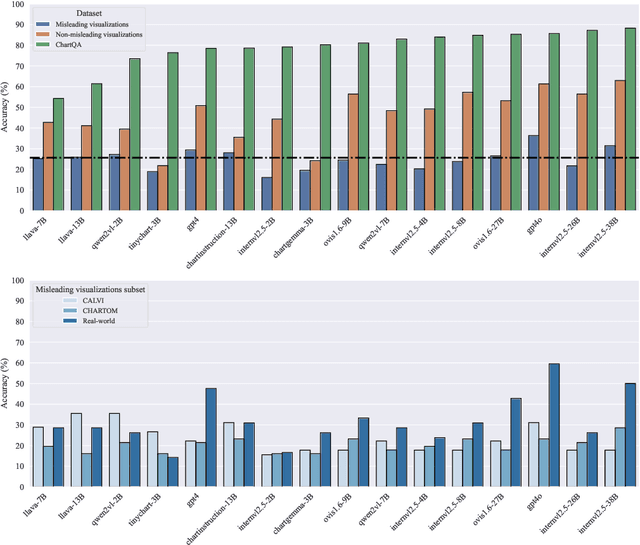
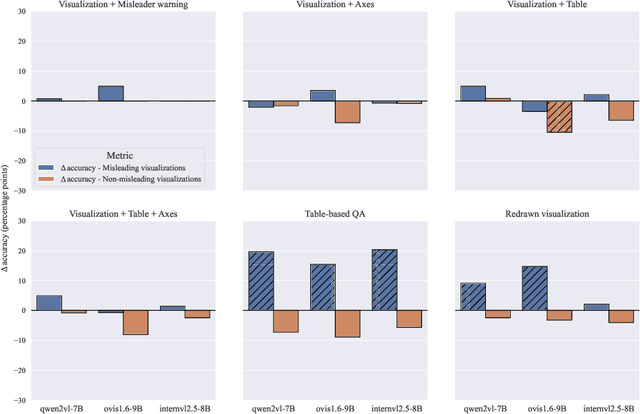
We assess the vulnerability of multimodal large language models to misleading visualizations - charts that distort the underlying data using techniques such as truncated or inverted axes, leading readers to draw inaccurate conclusions that may support misinformation or conspiracy theories. Our analysis shows that these distortions severely harm multimodal large language models, reducing their question-answering accuracy to the level of the random baseline. To mitigate this vulnerability, we introduce six inference-time methods to improve performance of MLLMs on misleading visualizations while preserving their accuracy on non-misleading ones. The most effective approach involves (1) extracting the underlying data table and (2) using a text-only large language model to answer questions based on the table. This method improves performance on misleading visualizations by 15.4 to 19.6 percentage points.