 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Online Convex Optimization with Unknown Feedback Delays
Jan 12, 2026Decentralized online convex optimization (D-OCO), where multiple agents within a network collaboratively learn optimal decisions in real-time, arises naturally in applications such as federated learning, sensor networks, and multi-agent control. In this paper, we study D-OCO under unknown, time-and agent-varying feedback delays. While recent work has addressed this problem (Nguyen et al., 2024), existing algorithms assume prior knowledge of the total delay over agents and still suffer from suboptimal dependence on both the delay and network parameters. To overcome these limitations, we propose a novel algorithm that achieves an improved regret bound of O N $\sqrt$ d tot + N $\sqrt$ T (1-$σ$2) 1/4 , where T is the total horizon, d tot denotes the average total delay across agents, N is the number of agents, and 1 -$σ$ 2 is the spectral gap of the network. Our approach builds upon recent advances in D-OCO (Wan et al., 2024a), but crucially incorporates an adaptive learning rate mechanism via a decentralized communication protocol. This enables each agent to estimate delays locally using a gossip-based strategy without the prior knowledge of the total delay. We further extend our framework to the strongly convex setting and derive a sharper regret bound of O N $δ$max ln T $α$ , where $α$ is the strong convexity parameter and $δ$ max is the maximum number of missing observations averaged over agents. We also show that our upper bounds for both settings are tight up to logarithmic factors. Experimental results validate the effectiveness of our approach, showing improvements over existing benchmark algorithms.
Distributed Multi-Agent Bandits Over Erdős-Rényi Random Networks
Oct 26, 2025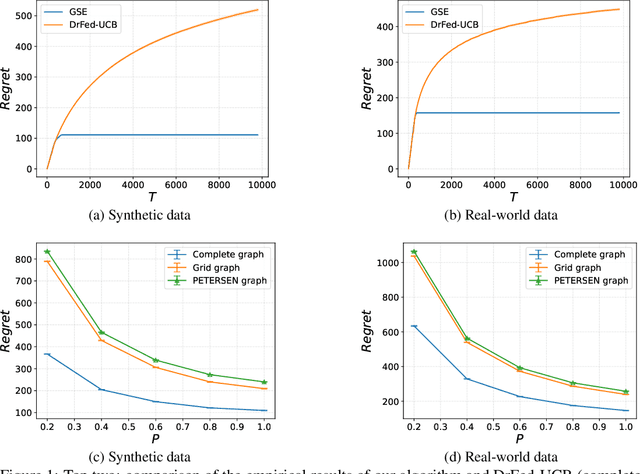

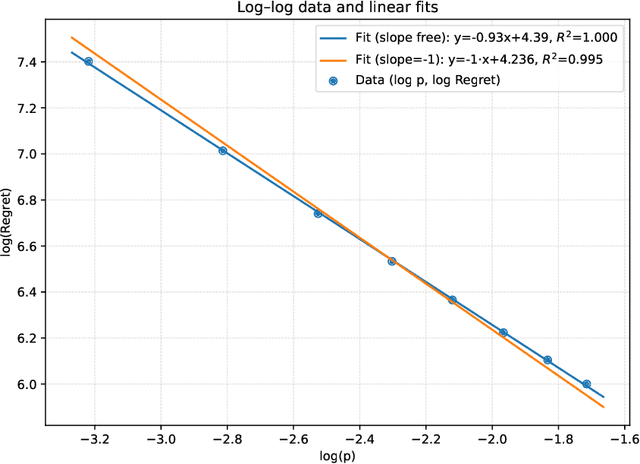
We study the distributed multi-agent multi-armed bandit problem with heterogeneous rewards over random communication graphs. Uniquely, at each time step $t$ agents communicate over a time-varying random graph $G_t$ generated by applying the Erd\H{o}s-R\'enyi model to a fixed connected base graph $G$ (for classical Erd\H{o}s-R\'enyi graphs, $G$ is a complete graph), where each potential edge in $G$ is randomly and independently present with the link probability $p$. Notably, the resulting random graph is not necessarily connected at each time step. Each agent's arm rewards follow time-invariant distributions, and the reward distribution for the same arm may differ across agents. The goal is to minimize the cumulative expected regret relative to the global mean reward of each arm, defined as the average of that arm's mean rewards across all agents. To this end, we propose a fully distributed algorithm that integrates the arm elimination strategy with the random gossip algorithm. We theoretically show that the regret upper bound is of order $\log T$ and is highly interpretable, where $T$ is the time horizon. It includes the optimal centralized regret $O\left(\sum_{k: \Delta_k>0} \frac{\log T}{\Delta_k}\right)$ and an additional term $O\left(\frac{N^2 \log T}{p \lambda_{N-1}(Lap(G))} + \frac{KN^2 \log T}{p}\right)$ where $N$ and $K$ denote the total number of agents and arms, respectively. This term reflects the impact of $G$'s algebraic connectivity $\lambda_{N-1}(Lap(G))$ and the link probability $p$, and thus highlights a fundamental trade-off between communication efficiency and regret. As a by-product, we show a nearly optimal regret lower bound. Finally, our numerical experiments not only show the superiority of our algorithm over existing benchmarks, but also validate the theoretical regret scaling with problem complexity.
Exploiting Curvature in Online Convex Optimization with Delayed Feedback
Jun 09, 2025In this work, we study the online convex optimization problem with curved losses and delayed feedback. When losses are strongly convex, existing approaches obtain regret bounds of order $d_{\max} \ln T$, where $d_{\max}$ is the maximum delay and $T$ is the time horizon. However, in many cases, this guarantee can be much worse than $\sqrt{d_{\mathrm{tot}}}$ as obtained by a delayed version of online gradient descent, where $d_{\mathrm{tot}}$ is the total delay. We bridge this gap by proposing a variant of follow-the-regularized-leader that obtains regret of order $\min\{\sigma_{\max}\ln T, \sqrt{d_{\mathrm{tot}}}\}$, where $\sigma_{\max}$ is the maximum number of missing observations. We then consider exp-concave losses and extend the Online Newton Step algorithm to handle delays with an adaptive learning rate tuning, achieving regret $\min\{d_{\max} n\ln T, \sqrt{d_{\mathrm{tot}}}\}$ where $n$ is the dimension. To our knowledge, this is the first algorithm to achieve such a regret bound for exp-concave losses. We further consider the problem of unconstrained online linear regression and achieve a similar guarantee by designing a variant of the Vovk-Azoury-Warmuth forecaster with a clipping trick. Finally, we implement our algorithms and conduct experiments under various types of delay and losses, showing an improved performance over existing methods.
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
EgoBlind: Towards Egocentric Visual Assistance for the Blind People
Mar 11, 2025We present EgoBlind, the first egocentric VideoQA dataset collected from blind individuals to evaluate the assistive capabilities of contemporary multimodal large language models (MLLMs). EgoBlind comprises 1,210 videos that record the daily lives of real blind users from a first-person perspective. It also features 4,927 questions directly posed or generated and verified by blind individuals to reflect their needs for visual assistance under various scenarios. We provide each question with an average of 3 reference answers to alleviate subjective evaluation. Using EgoBlind, we comprehensively evaluate 15 leading MLLMs and find that all models struggle, with the best performers achieving accuracy around 56\%, far behind human performance of 87.4\%. To guide future advancements, we identify and summarize major limitations of existing MLLMs in egocentric visual assistance for the blind and provide heuristic suggestions for improvement. With these efforts, we hope EgoBlind can serve as a valuable foundation for developing more effective AI assistants to enhance the independence of the blind individuals' lives.
Trading-Off Payments and Accuracy in Online Classification with Paid Stochastic Experts
Jul 03, 2023



We investigate online classification with paid stochastic experts. Here, before making their prediction, each expert must be paid. The amount that we pay each expert directly influences the accuracy of their prediction through some unknown Lipschitz "productivity" function. In each round, the learner must decide how much to pay each expert and then make a prediction. They incur a cost equal to a weighted sum of the prediction error and upfront payments for all experts. We introduce an online learning algorithm whose total cost after $T$ rounds exceeds that of a predictor which knows the productivity of all experts in advance by at most $\mathcal{O}(K^2(\log T)\sqrt{T})$ where $K$ is the number of experts. In order to achieve this result, we combine Lipschitz bandits and online classification with surrogate losses. These tools allow us to improve upon the bound of order $T^{2/3}$ one would obtain in the standard Lipschitz bandit setting. Our algorithm is empirically evaluated on synthetic data
Delayed Bandits: When Do Intermediate Observations Help?
May 30, 2023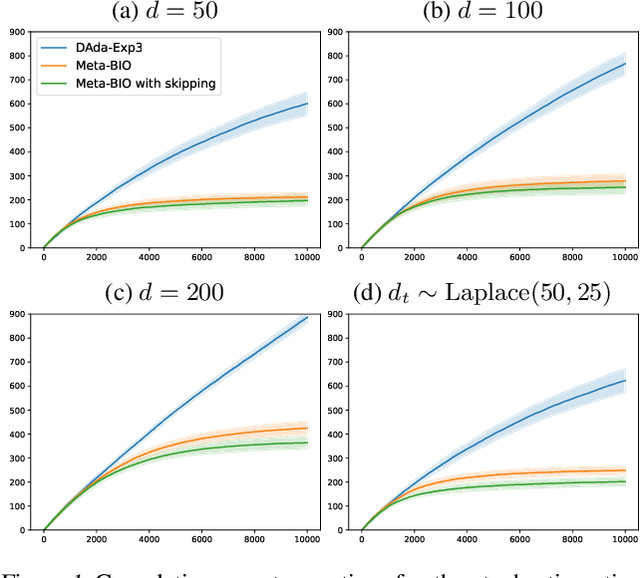



We study a $K$-armed bandit with delayed feedback and intermediate observations. We consider a model where intermediate observations have a form of a finite state, which is observed immediately after taking an action, whereas the loss is observed after an adversarially chosen delay. We show that the regime of the mapping of states to losses determines the complexity of the problem, irrespective of whether the mapping of actions to states is stochastic or adversarial. If the mapping of states to losses is adversarial, then the regret rate is of order $\sqrt{(K+d)T}$ (within log factors), where $T$ is the time horizon and $d$ is a fixed delay. This matches the regret rate of a $K$-armed bandit with delayed feedback and without intermediate observations, implying that intermediate observations are not helpful. However, if the mapping of states to losses is stochastic, we show that the regret grows at a rate of $\sqrt{\big(K+\min\{|\mathcal{S}|,d\}\big)T}$ (within log factors), implying that if the number $|\mathcal{S}|$ of states is smaller than the delay, then intermediate observations help. We also provide refined high-probability regret upper bounds for non-uniform delays, together with experimental validation of our algorithms.
Black-box adversarial attacks using Evolution Strategies
Apr 30, 2021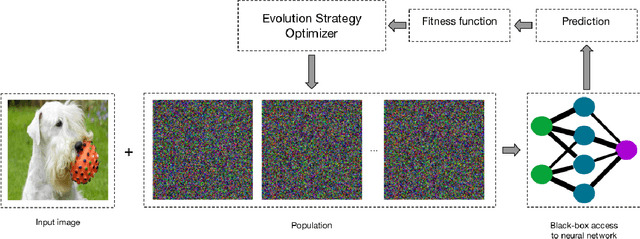



In the last decade, deep neural networks have proven to be very powerful in computer vision tasks, starting a revolution in the computer vision and machine learning fields. However, deep neural networks, usually, are not robust to perturbations of the input data. In fact, several studies showed that slightly changing the content of the images can cause a dramatic decrease in the accuracy of the attacked neural network. Several methods able to generate adversarial samples make use of gradients, which usually are not available to an attacker in real-world scenarios. As opposed to this class of attacks, another class of adversarial attacks, called black-box adversarial attacks, emerged, which does not make use of information on the gradients, being more suitable for real-world attack scenarios. In this work, we compare three well-known evolution strategies on the generation of black-box adversarial attacks for image classification tasks. While our results show that the attacked neural networks can be, in most cases, easily fooled by all the algorithms under comparison, they also show that some black-box optimization algorithms may be better in "harder" setups, both in terms of attack success rate and efficiency (i.e., number of queries).
The Channel Attention based Context Encoder Network for Inner Limiting Membrane Detection
Aug 09, 2019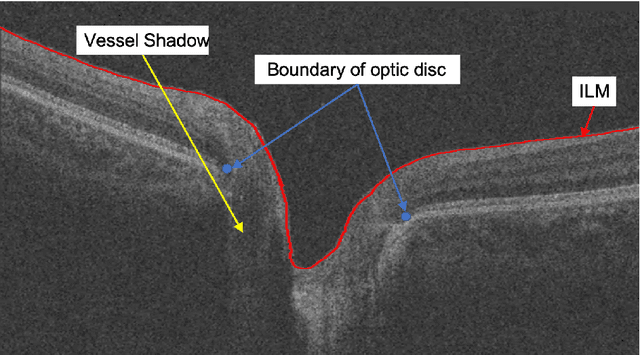
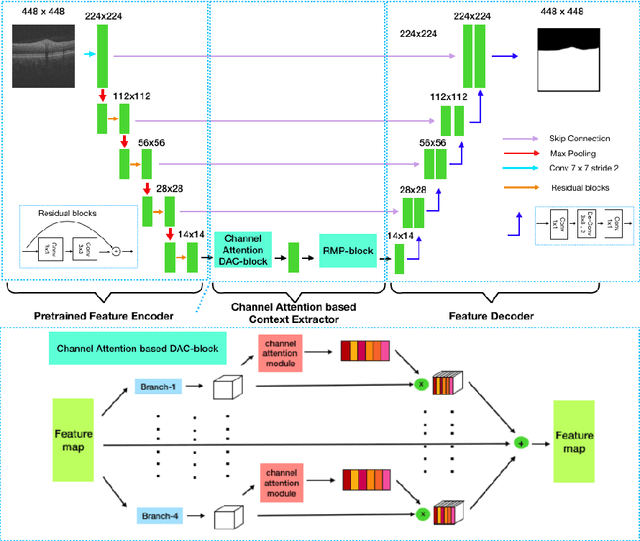

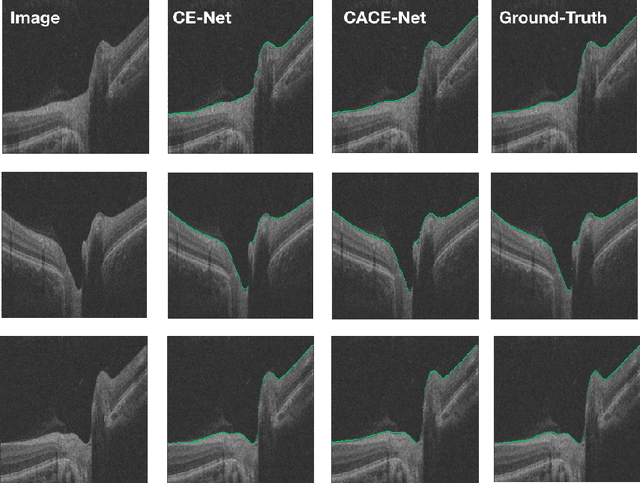
The optic disc segmentation is an important step for retinal image-based disease diagnosis such as glaucoma. The inner limiting membrane (ILM) is the first boundary in the OCT, which can help to extract the retinal pigment epithelium (RPE) through gradient edge information to locate the boundary of the optic disc. Thus, the ILM layer segmentation is of great importance for optic disc localization. In this paper, we build a new optic disc centered dataset from 20 volunteers and manually annotated the ILM boundary in each OCT scan as ground-truth. We also propose a channel attention based context encoder network modified from the CE-Net to segment the optic disc. It mainly contains three phases: the encoder module, the channel attention based context encoder module, and the decoder module. Finally, we demonstrate that our proposed method achieves state-of-the-art disc segmentation performance on our dataset mentioned above.