 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoomda: Balanced Multi-objective Optimization for Multimodal Domain Adaptation
Nov 11, 2025Multimodal learning, while contributing to numerous success stories across various fields, faces the challenge of prohibitively expensive manual annotation. To address the scarcity of annotated data, a popular solution is unsupervised domain adaptation, which has been extensively studied in unimodal settings yet remains less explored in multimodal settings. In this paper, we investigate heterogeneous multimodal domain adaptation, where the primary challenge is the varying domain shifts of different modalities from the source to the target domain. We first introduce the information bottleneck method to learn representations for each modality independently, and then match the source and target domains in the representation space with correlation alignment. To balance the domain alignment of all modalities, we formulate the problem as a multi-objective task, aiming for a Pareto optimal solution. By exploiting the properties specific to our model, the problem can be simplified to a quadratic programming problem. Further approximation yields a closed-form solution, leading to an efficient modality-balanced multimodal domain adaptation algorithm. The proposed method features \textbf{B}alanced multi-\textbf{o}bjective \textbf{o}ptimization for \textbf{m}ultimodal \textbf{d}omain \textbf{a}daptation, termed \textbf{Boomda}. Extensive empirical results showcase the effectiveness of the proposed approach and demonstrate that Boomda outperforms the competing schemes. The code is is available at: https://github.com/sunjunaimer/Boomda.git.
Towards Reliable LLM-based Robot Planning via Combined Uncertainty Estimation
Oct 09, 2025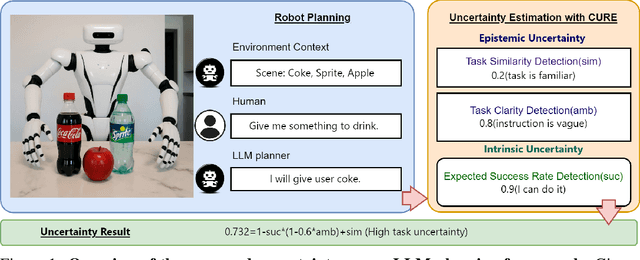
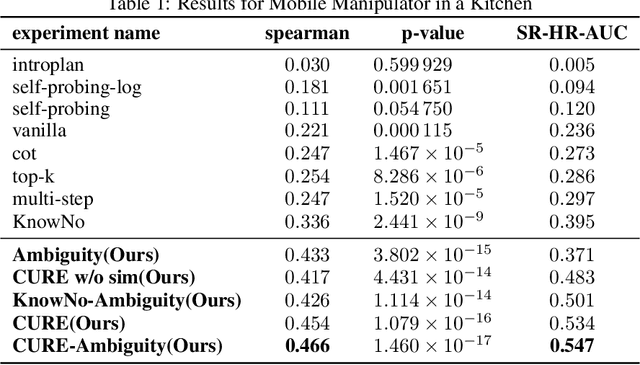
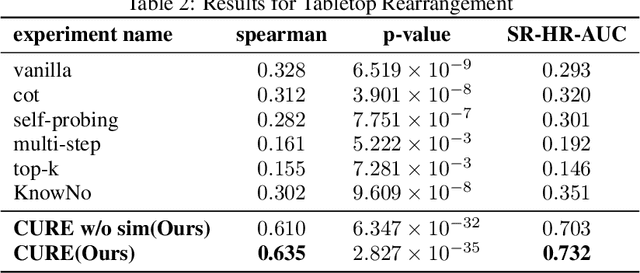
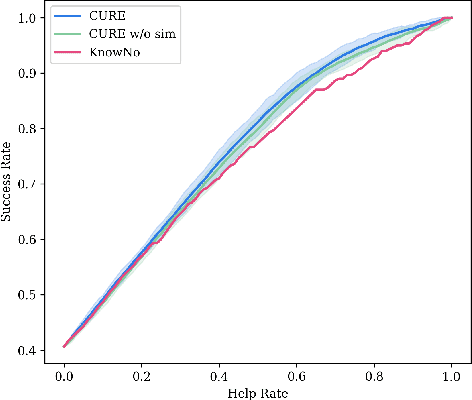
Large language models (LLMs) demonstrate advanced reasoning abilities, enabling robots to understand natural language instructions and generate high-level plans with appropriate grounding. However, LLM hallucinations present a significant challenge, often leading to overconfident yet potentially misaligned or unsafe plans. While researchers have explored uncertainty estimation to improve the reliability of LLM-based planning, existing studies have not sufficiently differentiated between epistemic and intrinsic uncertainty, limiting the effectiveness of uncertainty esti- mation. In this paper, we present Combined Uncertainty estimation for Reliable Embodied planning (CURE), which decomposes the uncertainty into epistemic and intrinsic uncertainty, each estimated separately. Furthermore, epistemic uncertainty is subdivided into task clarity and task familiarity for more accurate evaluation. The overall uncertainty assessments are obtained using random network distillation and multi-layer perceptron regression heads driven by LLM features. We validated our approach in two distinct experimental settings: kitchen manipulation and tabletop rearrangement experiments. The results show that, compared to existing methods, our approach yields uncertainty estimates that are more closely aligned with the actual execution outcomes.
Using Large Language Models for Parametric Shape Optimization
Dec 11, 2024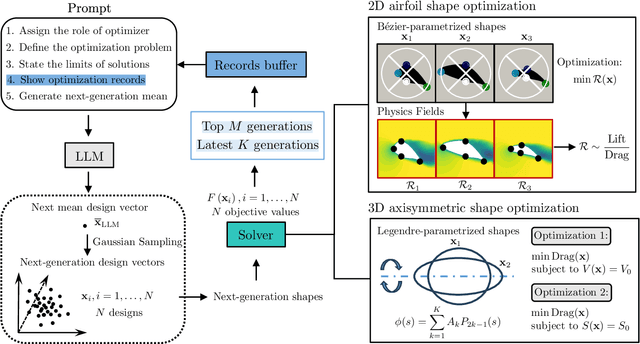

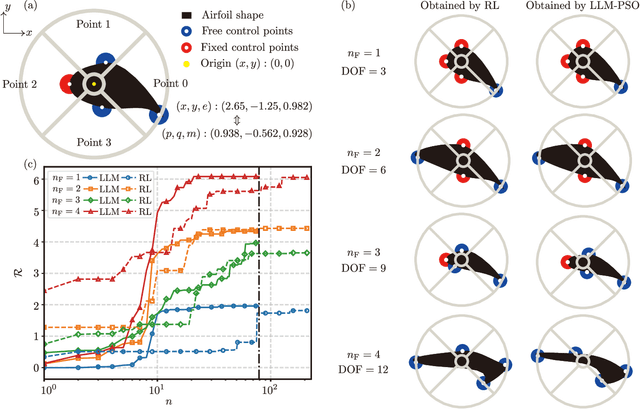
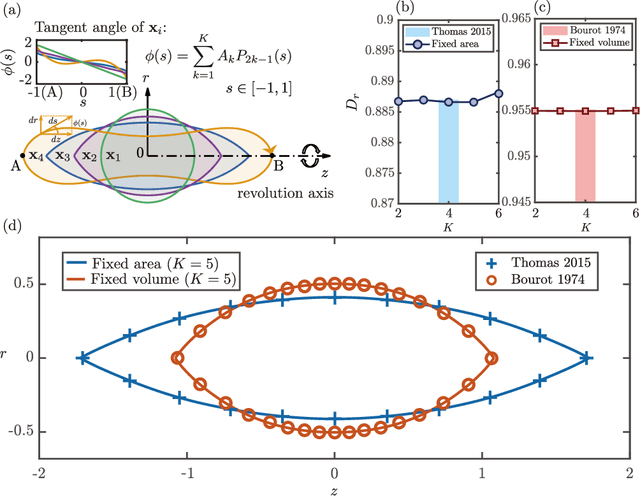
Recent advanced large language models (LLMs) have showcased their emergent capability of in-context learning, facilitating intelligent decision-making through natural language prompts without retraining. This new machine learning paradigm has shown promise in various fields, including general control and optimization problems. Inspired by these advancements, we explore the potential of LLMs for a specific and essential engineering task: parametric shape optimization (PSO). We develop an optimization framework, LLM-PSO, that leverages an LLM to determine the optimal shape of parameterized engineering designs in the spirit of evolutionary strategies. Utilizing the ``Claude 3.5 Sonnet'' LLM, we evaluate LLM-PSO on two benchmark flow optimization problems, specifically aiming to identify drag-minimizing profiles for 1) a two-dimensional airfoil in laminar flow, and 2) a three-dimensional axisymmetric body in Stokes flow. In both cases, LLM-PSO successfully identifies optimal shapes in agreement with benchmark solutions. Besides, it generally converges faster than other classical optimization algorithms. Our preliminary exploration may inspire further investigations into harnessing LLMs for shape optimization and engineering design more broadly.
Unified Embedding Alignment for Open-Vocabulary Video Instance Segmentation
Jul 10, 2024



Open-Vocabulary Video Instance Segmentation (VIS) is attracting increasing attention due to its ability to segment and track arbitrary objects. However, the recent Open-Vocabulary VIS attempts obtained unsatisfactory results, especially in terms of generalization ability of novel categories. We discover that the domain gap between the VLM features (e.g., CLIP) and the instance queries and the underutilization of temporal consistency are two central causes. To mitigate these issues, we design and train a novel Open-Vocabulary VIS baseline called OVFormer. OVFormer utilizes a lightweight module for unified embedding alignment between query embeddings and CLIP image embeddings to remedy the domain gap. Unlike previous image-based training methods, we conduct video-based model training and deploy a semi-online inference scheme to fully mine the temporal consistency in the video. Without bells and whistles, OVFormer achieves 21.9 mAP with a ResNet-50 backbone on LV-VIS, exceeding the previous state-of-the-art performance by 7.7. Extensive experiments on some Close-Vocabulary VIS datasets also demonstrate the strong zero-shot generalization ability of OVFormer (+ 7.6 mAP on YouTube-VIS 2019, + 3.9 mAP on OVIS). Code is available at https://github.com/fanghaook/OVFormer.
Fine-Grained Urban Flow Inference with Multi-scale Representation Learning
Jun 14, 2024Fine-grained urban flow inference (FUFI) is a crucial transportation service aimed at improving traffic efficiency and safety. FUFI can infer fine-grained urban traffic flows based solely on observed coarse-grained data. However, most of existing methods focus on the influence of single-scale static geographic information on FUFI, neglecting the interactions and dynamic information between different-scale regions within the city. Different-scale geographical features can capture redundant information from the same spatial areas. In order to effectively learn multi-scale information across time and space, we propose an effective fine-grained urban flow inference model called UrbanMSR, which uses self-supervised contrastive learning to obtain dynamic multi-scale representations of neighborhood-level and city-level geographic information, and fuses multi-scale representations to improve fine-grained accuracy. The fusion of multi-scale representations enhances fine-grained. We validate the performance through extensive experiments on three real-world datasets. The resutls compared with state-of-the-art methods demonstrate the superiority of the proposed model.
RedCore: Relative Advantage Aware Cross-modal Representation Learning for Missing Modalities with Imbalanced Missing Rates
Dec 16, 2023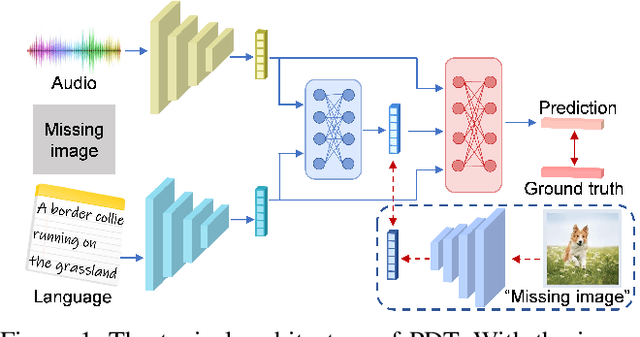
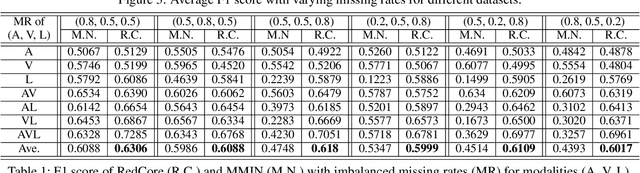
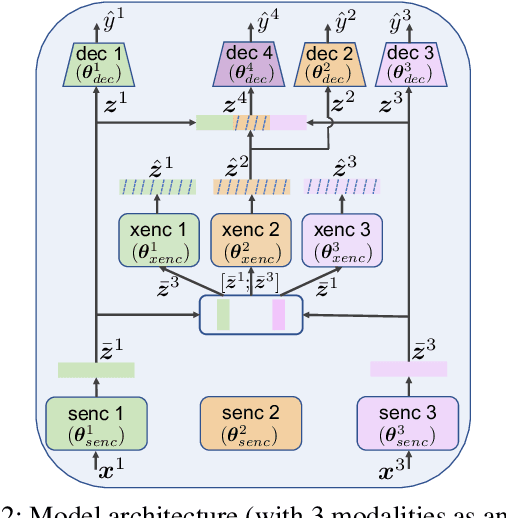
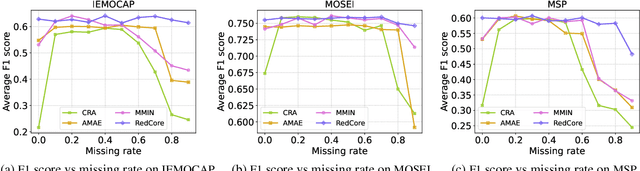
Multimodal learning is susceptible to modality missing, which poses a major obstacle for its practical applications and, thus, invigorates increasing research interest. In this paper, we investigate two challenging problems: 1) when modality missing exists in the training data, how to exploit the incomplete samples while guaranteeing that they are properly supervised? 2) when the missing rates of different modalities vary, causing or exacerbating the imbalance among modalities, how to address the imbalance and ensure all modalities are well-trained? To tackle these two challenges, we first introduce the variational information bottleneck (VIB) method for the cross-modal representation learning of missing modalities, which capitalizes on the available modalities and the labels as supervision. Then, accounting for the imbalanced missing rates, we define relative advantage to quantify the advantage of each modality over others. Accordingly, a bi-level optimization problem is formulated to adaptively regulate the supervision of all modalities during training. As a whole, the proposed approach features \textbf{Re}lative a\textbf{d}vantage aware \textbf{C}ross-m\textbf{o}dal \textbf{r}epresentation l\textbf{e}arning (abbreviated as \textbf{RedCore}) for missing modalities with imbalanced missing rates. Extensive empirical results demonstrate that RedCore outperforms competing models in that it exhibits superior robustness against either large or imbalanced missing rates.
A Reinforcement Learning Framework for Online Speaker Diarization
Feb 21, 2023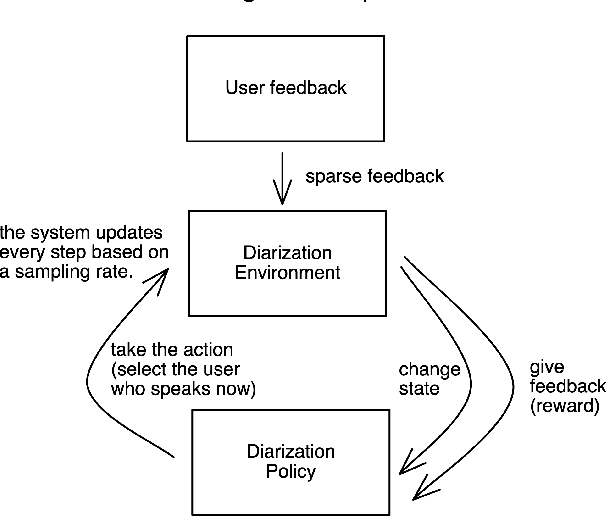
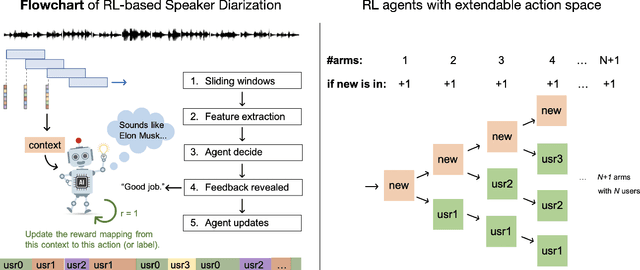
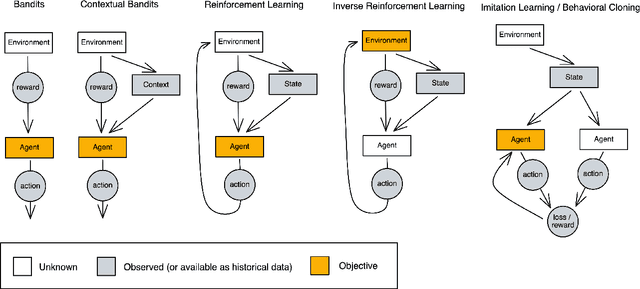
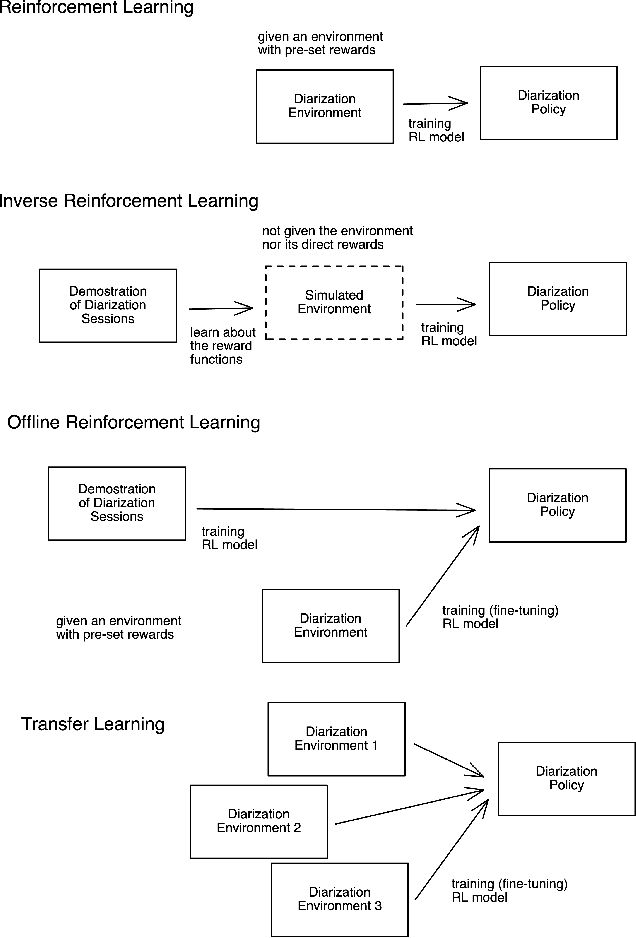
Speaker diarization is a task to label an audio or video recording with the identity of the speaker at each given time stamp. In this work, we propose a novel machine learning framework to conduct real-time multi-speaker diarization and recognition without prior registration and pretraining in a fully online and reinforcement learning setting. Our framework combines embedding extraction, clustering, and resegmentation into the same problem as an online decision-making problem. We discuss practical considerations and advanced techniques such as the offline reinforcement learning, semi-supervision, and domain adaptation to address the challenges of limited training data and out-of-distribution environments. Our approach considers speaker diarization as a fully online learning problem of the speaker recognition task, where the agent receives no pretraining from any training set before deployment, and learns to detect speaker identity on the fly through reward feedbacks. The paradigm of the reinforcement learning approach to speaker diarization presents an adaptive, lightweight, and generalizable system that is useful for multi-user teleconferences, where many people might come and go without extensive pre-registration ahead of time. Lastly, we provide a desktop application that uses our proposed approach as a proof of concept. To the best of our knowledge, this is the first approach to apply a reinforcement learning approach to the speaker diarization task.
RTN: Reinforced Transformer Network for Coronary CT Angiography Vessel-level Image Quality Assessment
Jul 13, 2022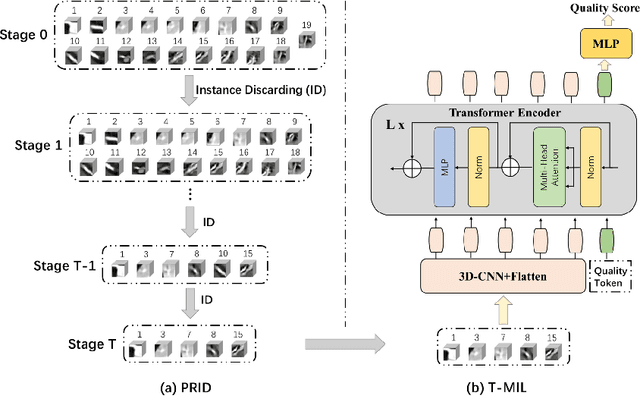
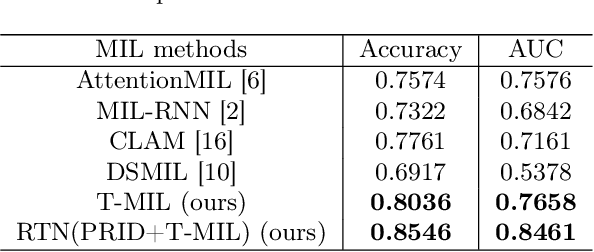
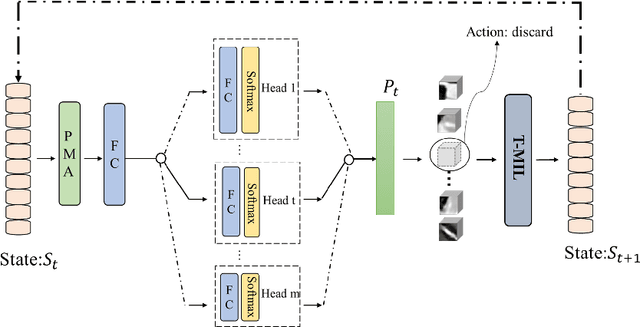

Coronary CT Angiography (CCTA) is susceptible to various distortions (e.g., artifacts and noise), which severely compromise the exact diagnosis of cardiovascular diseases. The appropriate CCTA Vessel-level Image Quality Assessment (CCTA VIQA) algorithm can be used to reduce the risk of error diagnosis. The primary challenges of CCTA VIQA are that the local part of coronary that determines final quality is hard to locate. To tackle the challenge, we formulate CCTA VIQA as a multiple-instance learning (MIL) problem, and exploit Transformer-based MIL backbone (termed as T-MIL) to aggregate the multiple instances along the coronary centerline into the final quality. However, not all instances are informative for final quality. There are some quality-irrelevant/negative instances intervening the exact quality assessment(e.g., instances covering only background or the coronary in instances is not identifiable). Therefore, we propose a Progressive Reinforcement learning based Instance Discarding module (termed as PRID) to progressively remove quality-irrelevant/negative instances for CCTA VIQA. Based on the above two modules, we propose a Reinforced Transformer Network (RTN) for automatic CCTA VIQA based on end-to-end optimization. Extensive experimental results demonstrate that our proposed method achieves the state-of-the-art performance on the real-world CCTA dataset, exceeding previous MIL methods by a large margin.
Geodesic Paths for Image Segmentation with Implicit Region-based Homogeneity Enhancement
Aug 16, 2020
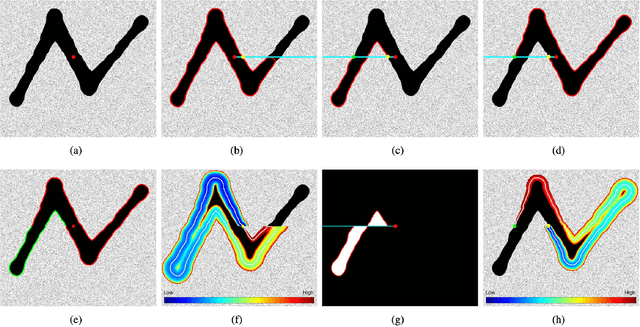

Minimal paths are considered as a powerful and efficient tool for boundary detection and image segmentation due to its global optimality and well-established numerical solutions such as fast marching algorithm. In this paper, we introduce a flexible interactive image segmentation model based on the minimal geodesic framework in conjunction with region-based homogeneity enhancement. A key ingredient in our model is the construction of Finsler geodesic metrics, which are capable of integrating anisotropic and asymmetric edge features, region-based homogeneity and/or curvature regularization. This is done by exploiting an implicit method to incorporate the region-based homogeneity information to the metrics used. Moreover, we also introduce a way to build objective simple closed contours, each of which is treated as the concatenation of two disjoint open paths. Experimental results prove that the proposed model indeed outperforms state-of-the-art minimal paths-based image segmentation approaches.
Speaker Diarization as a Fully Online Learning Problem in MiniVox
Jun 08, 2020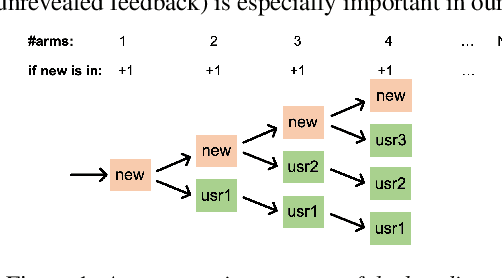
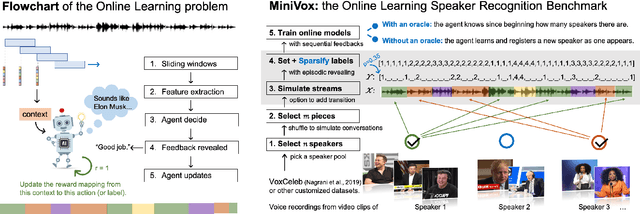
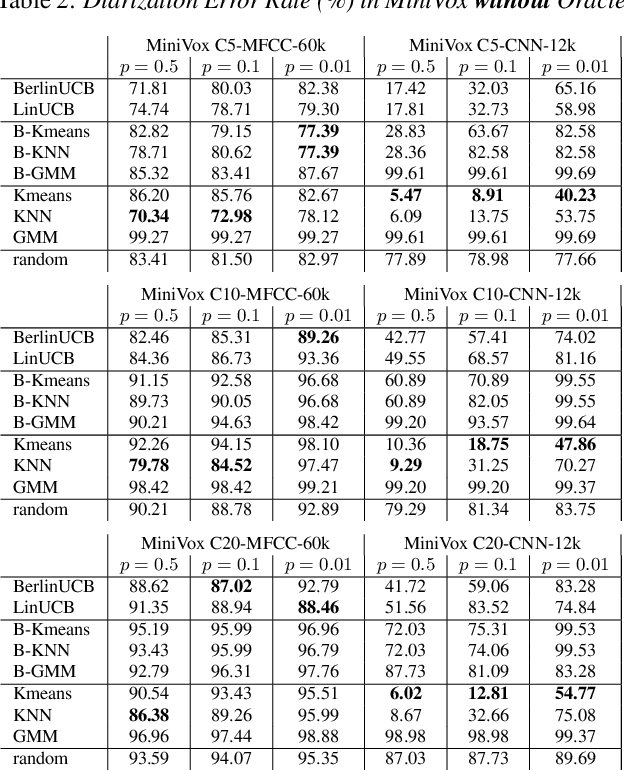

We proposed a novel AI framework to conduct real-time multi-speaker diarization and recognition without prior registration and pretraining in a fully online learning setting. Our contributions are two-fold. First, we proposed a new benchmark to evaluate the rarely studied fully online speaker diarization problem. We built upon existing datasets of real world utterances to automatically curate MiniVox, an experimental environment which generates infinite configurations of continuous multi-speaker speech stream. Secondly, we considered the practical problem of online learning with episodically revealed rewards and introduced a solution based on semi-supervised and self-supervised learning methods. Lastly, we provided a workable web-based recognition system which interactively handles the cold start problem of new user's addition by transferring representations of old arms to new ones with an extendable contextual bandit. We demonstrated that our proposed method obtained robust performance in the online MiniVox framework.