 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntuitive control of supernumerary robotic limbs through a tactile-encoded neural interface
Nov 11, 2025



Brain-computer interfaces (BCIs) promise to extend human movement capabilities by enabling direct neural control of supernumerary effectors, yet integrating augmented commands with multiple degrees of freedom without disrupting natural movement remains a key challenge. Here, we propose a tactile-encoded BCI that leverages sensory afferents through a novel tactile-evoked P300 paradigm, allowing intuitive and reliable decoding of supernumerary motor intentions even when superimposed with voluntary actions. The interface was evaluated in a multi-day experiment comprising of a single motor recognition task to validate baseline BCI performance and a dual task paradigm to assess the potential influence between the BCI and natural human movement. The brain interface achieved real-time and reliable decoding of four supernumerary degrees of freedom, with significant performance improvements after only three days of training. Importantly, after training, performance did not differ significantly between the single- and dual-BCI task conditions, and natural movement remained unimpaired during concurrent supernumerary control. Lastly, the interface was deployed in a movement augmentation task, demonstrating its ability to command two supernumerary robotic arms for functional assistance during bimanual tasks. These results establish a new neural interface paradigm for movement augmentation through stimulation of sensory afferents, expanding motor degrees of freedom without impairing natural movement.
LSVOS Challenge Report: Large-scale Complex and Long Video Object Segmentation
Sep 09, 2024



Despite the promising performance of current video segmentation models on existing benchmarks, these models still struggle with complex scenes. In this paper, we introduce the 6th Large-scale Video Object Segmentation (LSVOS) challenge in conjunction with ECCV 2024 workshop. This year's challenge includes two tasks: Video Object Segmentation (VOS) and Referring Video Object Segmentation (RVOS). In this year, we replace the classic YouTube-VOS and YouTube-RVOS benchmark with latest datasets MOSE, LVOS, and MeViS to assess VOS under more challenging complex environments. This year's challenge attracted 129 registered teams from more than 20 institutes across over 8 countries. This report include the challenge and dataset introduction, and the methods used by top 7 teams in two tracks. More details can be found in our homepage https://lsvos.github.io/.
UNINEXT-Cutie: The 1st Solution for LSVOS Challenge RVOS Track
Aug 19, 2024Referring video object segmentation (RVOS) relies on natural language expressions to segment target objects in video. In this year, LSVOS Challenge RVOS Track replaced the origin YouTube-RVOS benchmark with MeViS. MeViS focuses on referring the target object in a video through its motion descriptions instead of static attributes, posing a greater challenge to RVOS task. In this work, we integrate strengths of that leading RVOS and VOS models to build up a simple and effective pipeline for RVOS. Firstly, We finetune the state-of-the-art RVOS model to obtain mask sequences that are correlated with language descriptions. Secondly, based on a reliable and high-quality key frames, we leverage VOS model to enhance the quality and temporal consistency of the mask results. Finally, we further improve the performance of the RVOS model using semi-supervised learning. Our solution achieved 62.57 J&F on the MeViS test set and ranked 1st place for 6th LSVOS Challenge RVOS Track.
Video Object Segmentation via SAM 2: The 4th Solution for LSVOS Challenge VOS Track
Aug 19, 2024Video Object Segmentation (VOS) task aims to segmenting a particular object instance throughout the entire video sequence given only the object mask of the first frame. Recently, Segment Anything Model 2 (SAM 2) is proposed, which is a foundation model towards solving promptable visual segmentation in images and videos. SAM 2 builds a data engine, which improves model and data via user interaction, to collect the largest video segmentation dataset to date. SAM 2 is a simple transformer architecture with streaming memory for real-time video processing, which trained on the date provides strong performance across a wide range of tasks. In this work, we evaluate the zero-shot performance of SAM 2 on the more challenging VOS datasets MOSE and LVOS. Without fine-tuning on the training set, SAM 2 achieved 75.79 J&F on the test set and ranked 4th place for 6th LSVOS Challenge VOS Track.
PVUW 2024 Challenge on Complex Video Understanding: Methods and Results
Jun 24, 2024



Pixel-level Video Understanding in the Wild Challenge (PVUW) focus on complex video understanding. In this CVPR 2024 workshop, we add two new tracks, Complex Video Object Segmentation Track based on MOSE dataset and Motion Expression guided Video Segmentation track based on MeViS dataset. In the two new tracks, we provide additional videos and annotations that feature challenging elements, such as the disappearance and reappearance of objects, inconspicuous small objects, heavy occlusions, and crowded environments in MOSE. Moreover, we provide a new motion expression guided video segmentation dataset MeViS to study the natural language-guided video understanding in complex environments. These new videos, sentences, and annotations enable us to foster the development of a more comprehensive and robust pixel-level understanding of video scenes in complex environments and realistic scenarios. The MOSE challenge had 140 registered teams in total, 65 teams participated the validation phase and 12 teams made valid submissions in the final challenge phase. The MeViS challenge had 225 registered teams in total, 50 teams participated the validation phase and 5 teams made valid submissions in the final challenge phase.
3rd Place Solution for MeViS Track in CVPR 2024 PVUW workshop: Motion Expression guided Video Segmentation
Jun 07, 2024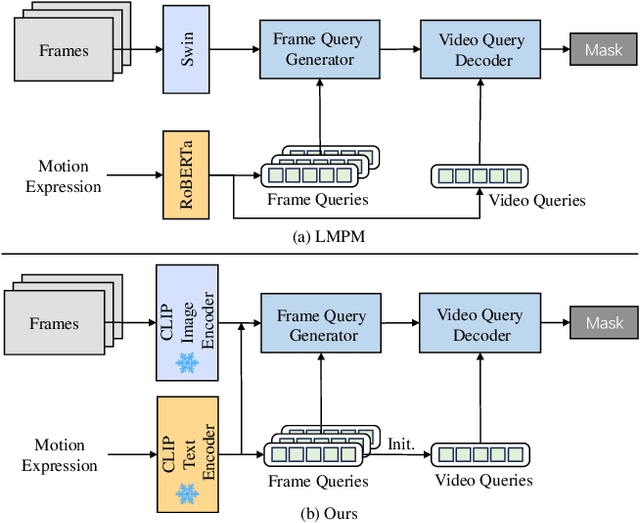
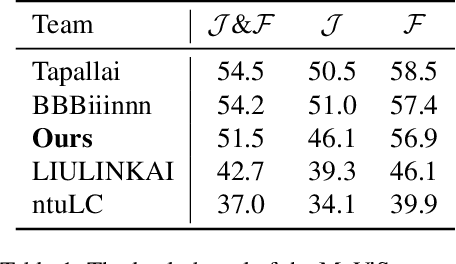
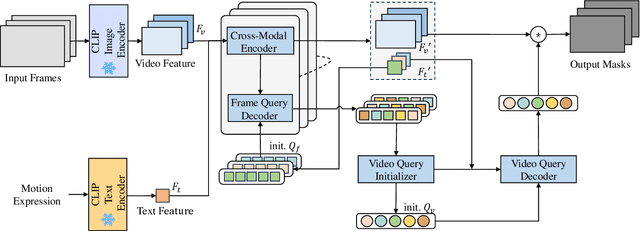

Referring video object segmentation (RVOS) relies on natural language expressions to segment target objects in video, emphasizing modeling dense text-video relations. The current RVOS methods typically use independently pre-trained vision and language models as backbones, resulting in a significant domain gap between video and text. In cross-modal feature interaction, text features are only used as query initialization and do not fully utilize important information in the text. In this work, we propose using frozen pre-trained vision-language models (VLM) as backbones, with a specific emphasis on enhancing cross-modal feature interaction. Firstly, we use frozen convolutional CLIP backbone to generate feature-aligned vision and text features, alleviating the issue of domain gap and reducing training costs. Secondly, we add more cross-modal feature fusion in the pipeline to enhance the utilization of multi-modal information. Furthermore, we propose a novel video query initialization method to generate higher quality video queries. Without bells and whistles, our method achieved 51.5 J&F on the MeViS test set and ranked 3rd place for MeViS Track in CVPR 2024 PVUW workshop: Motion Expression guided Video Segmentation.