 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorkBench Revisited: Workplace Agents Two Years On
Jun 10, 2026The best agent on WorkBench in March 2024, GPT-4, completed 43% of tasks and took an unintended harmful action, such as emailing the wrong person, on 26% of them. We re-visit the benchmark in June 2026 and find that the best agent to date, Claude Opus 4.8, completes 89% and takes an unintended harmful action on 2.5%. Aside from this considerable progress in frontier agent performance, three things stand out. First, capability and safety go together on WorkBench rather than trade off, so the models that finish the most tasks also do the least unintended damage. Second, while several classes of error have been totally eliminated, frontier models still make some basic mistakes that occasionally result in irreversible harm, such as sending an email to the wrong person. Third, the rise of open-weight models has drastically lowered costs for a performance level that was previously only accessible to proprietary models, while frontier costs have stayed relatively stable. We release an updated version of the benchmark with data and code quality improvements, new model scores, and analysis of agent progress on WorkBench since 2024.
WorkBench: a Benchmark Dataset for Agents in a Realistic Workplace Setting
May 01, 2024We introduce WorkBench: a benchmark dataset for evaluating agents' ability to execute tasks in a workplace setting. WorkBench contains a sandbox environment with five databases, 26 tools, and 690 tasks. These tasks represent common business activities, such as sending emails and scheduling meetings. The tasks in WorkBench are challenging as they require planning, tool selection, and often multiple actions. If a task has been successfully executed, one (or more) of the database values may change. The correct outcome for each task is unique and unambiguous, which allows for robust, automated evaluation. We call this key contribution outcome-centric evaluation. We evaluate five existing ReAct agents on WorkBench, finding they successfully complete as few as 3% of tasks (Llama2-70B), and just 43% for the best-performing (GPT-4). We further find that agents' errors can result in the wrong action being taken, such as an email being sent to the wrong person. WorkBench reveals weaknesses in agents' ability to undertake common business activities, raising questions about their use in high-stakes workplace settings. WorkBench is publicly available as a free resource at https://github.com/olly-styles/WorkBench.
Multi-Camera Trajectory Forecasting with Trajectory Tensors
Aug 24, 2021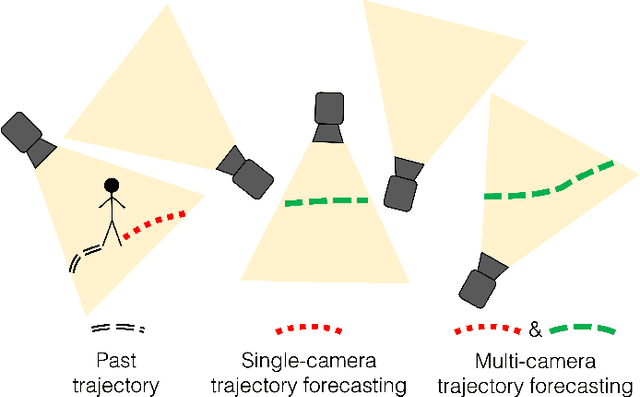
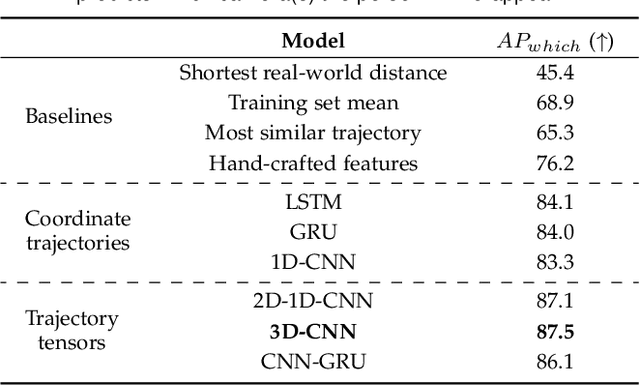
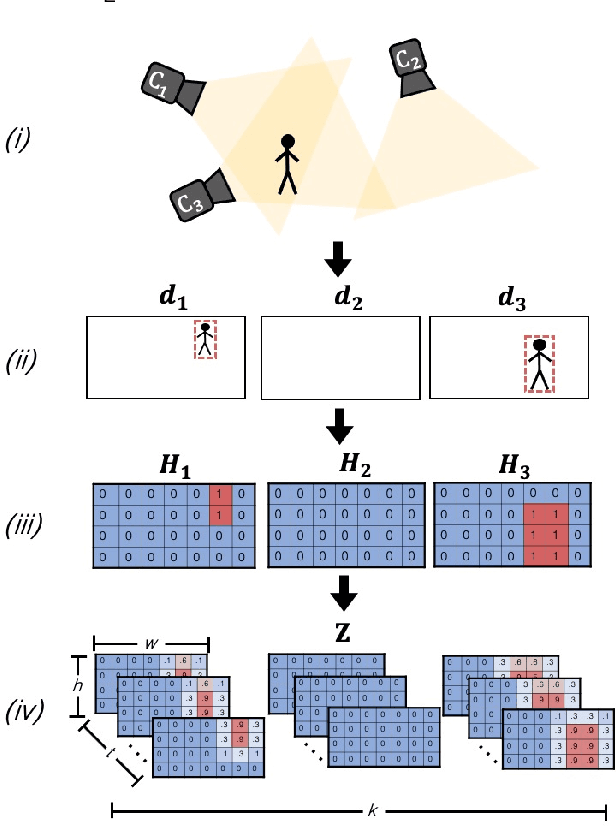
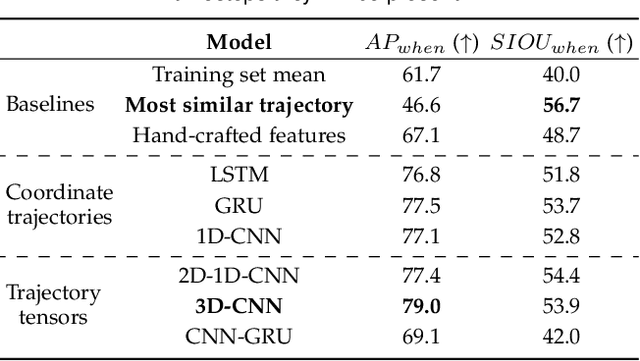
We introduce the problem of multi-camera trajectory forecasting (MCTF), which involves predicting the trajectory of a moving object across a network of cameras. While multi-camera setups are widespread for applications such as surveillance and traffic monitoring, existing trajectory forecasting methods typically focus on single-camera trajectory forecasting (SCTF), limiting their use for such applications. Furthermore, using a single camera limits the field-of-view available, making long-term trajectory forecasting impossible. We address these shortcomings of SCTF by developing an MCTF framework that simultaneously uses all estimated relative object locations from several viewpoints and predicts the object's future location in all possible viewpoints. Our framework follows a Which-When-Where approach that predicts in which camera(s) the objects appear and when and where within the camera views they appear. To this end, we propose the concept of trajectory tensors: a new technique to encode trajectories across multiple camera views and the associated uncertainties. We develop several encoder-decoder MCTF models for trajectory tensors and present extensive experiments on our own database (comprising 600 hours of video data from 15 camera views) created particularly for the MCTF task. Results show that our trajectory tensor models outperform coordinate trajectory-based MCTF models and existing SCTF methods adapted for MCTF. Code is available from: https://github.com/olly-styles/Trajectory-Tensors
Joint Learning Architecture for Multiple Object Tracking and Trajectory Forecasting
Aug 24, 2021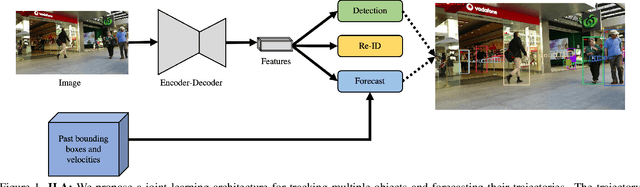
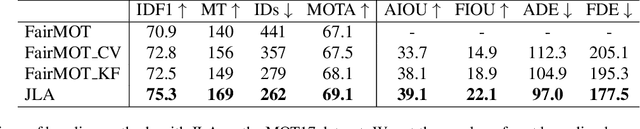
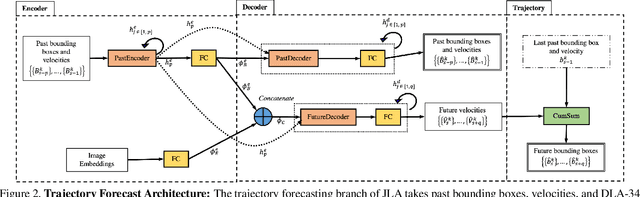
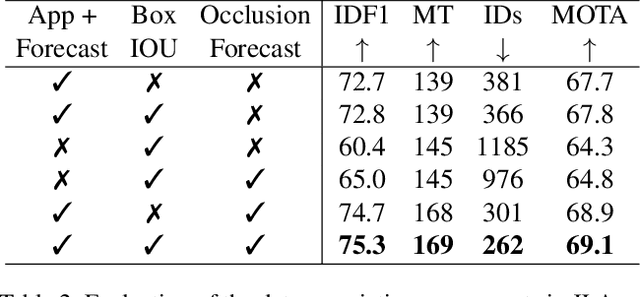
This paper introduces a joint learning architecture (JLA) for multiple object tracking (MOT) and trajectory forecasting in which the goal is to predict objects' current and future trajectories simultaneously. Motion prediction is widely used in several state of the art MOT methods to refine predictions in the form of bounding boxes. Typically, a Kalman Filter provides short-term estimations to help trackers correctly predict objects' locations in the current frame. However, the Kalman Filter-based approaches cannot predict non-linear trajectories. We propose to jointly train a tracking and trajectory forecasting model and use the predicted trajectory forecasts for short-term motion estimates in lieu of linear motion prediction methods such as the Kalman filter. We evaluate our JLA on the MOTChallenge benchmark. Evaluations result show that JLA performs better for short-term motion prediction and reduces ID switches by 33%, 31%, and 47% in the MOT16, MOT17, and MOT20 datasets, respectively, in comparison to FairMOT.
Multi-Camera Trajectory Forecasting: Pedestrian Trajectory Prediction in a Network of Cameras
May 01, 2020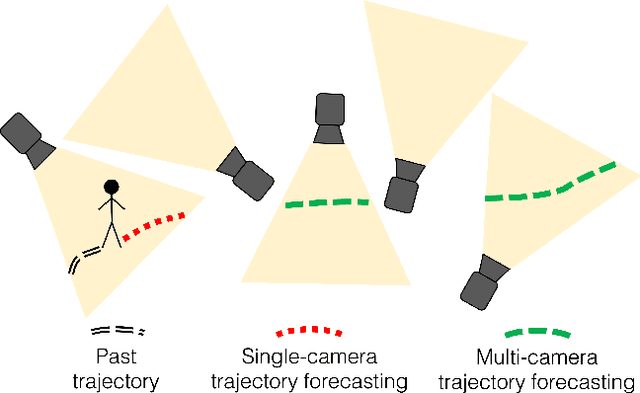

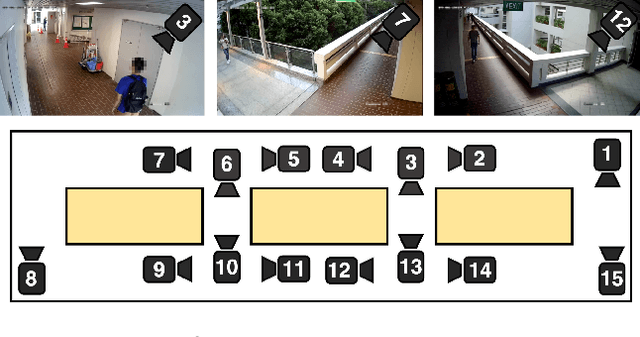
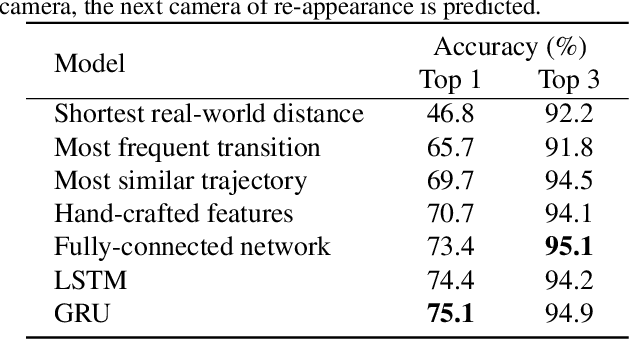
We introduce the task of multi-camera trajectory forecasting (MCTF), where the future trajectory of an object is predicted in a network of cameras. Prior works consider forecasting trajectories in a single camera view. Our work is the first to consider the challenging scenario of forecasting across multiple non-overlapping camera views. This has wide applicability in tasks such as re-identification and multi-target multi-camera tracking. To facilitate research in this new area, we release the Warwick-NTU Multi-camera Forecasting Database (WNMF), a unique dataset of multi-camera pedestrian trajectories from a network of 15 synchronized cameras. To accurately label this large dataset (600 hours of video footage), we also develop a semi-automated annotation method. An effective MCTF model should proactively anticipate where and when a person will re-appear in the camera network. In this paper, we consider the task of predicting the next camera a pedestrian will re-appear after leaving the view of another camera, and present several baseline approaches for this. The labeled database is available online: https://github.com/olly-styles/Multi-Camera-Trajectory-Forecasting.
Multiple Object Forecasting: Predicting Future Object Locations in Diverse Environments
Sep 26, 2019


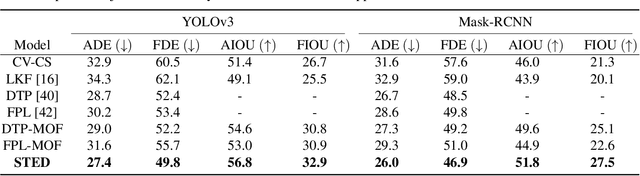
This paper introduces the problem of multiple object forecasting (MOF), in which the goal is to predict future bounding boxes of tracked objects. In contrast to existing works on object trajectory forecasting which primarily consider the problem from a birds-eye perspective, we formulate the problem from an object-level perspective and call for the prediction of full object bounding boxes, rather than trajectories alone. Towards solving this task, we introduce the Citywalks dataset, which consists of over 200k high-resolution video frames. Citywalks comprises of footage recorded in 21 cities from 10 European countries in a variety of weather conditions and over 3.5k unique pedestrian trajectories. For evaluation, we adapt existing trajectory forecasting methods for MOF and confirm cross-dataset generalizability on the MOT-17 dataset without fine-tuning. Finally, we present STED, a novel encoder-decoder architecture for MOF. STED combines visual and temporal features to model both object-motion and ego-motion, and outperforms existing approaches for MOF. Code & dataset link: https://github.com/olly-styles/Multiple-Object-Forecasting
Forecasting Pedestrian Trajectory with Machine-Annotated Training Data
May 09, 2019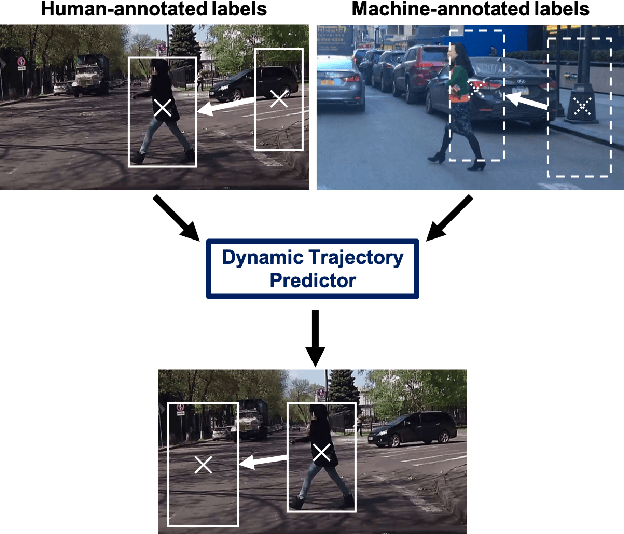
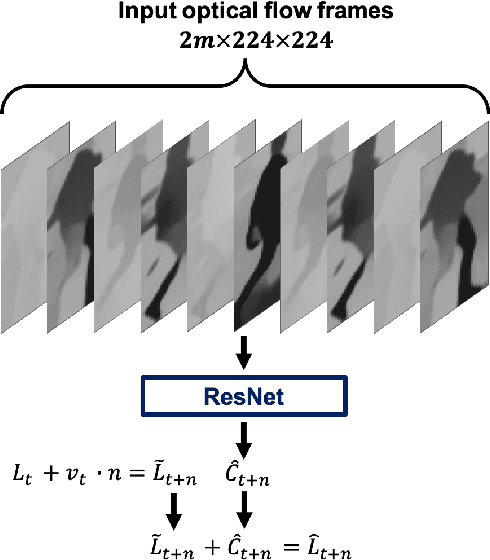

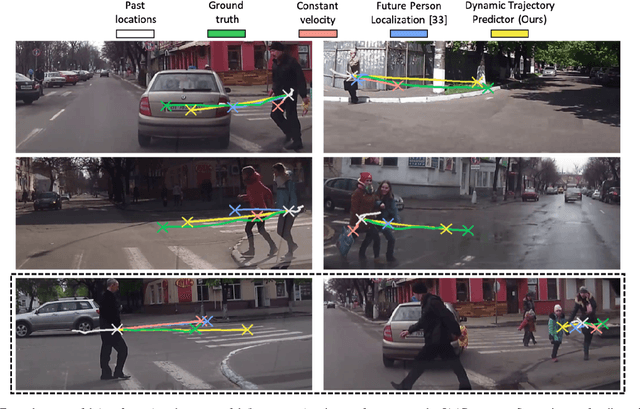
Reliable anticipation of pedestrian trajectory is imperative for the operation of autonomous vehicles and can significantly enhance the functionality of advanced driver assistance systems. While significant progress has been made in the field of pedestrian detection, forecasting pedestrian trajectories remains a challenging problem due to the unpredictable nature of pedestrians and the huge space of potentially useful features. In this work, we present a deep learning approach for pedestrian trajectory forecasting using a single vehicle-mounted camera. Deep learning models that have revolutionized other areas in computer vision have seen limited application to trajectory forecasting, in part due to the lack of richly annotated training data. We address the lack of training data by introducing a scalable machine annotation scheme that enables our model to be trained using a large dataset without human annotation. In addition, we propose Dynamic Trajectory Predictor (DTP), a model for forecasting pedestrian trajectory up to one second into the future. DTP is trained using both human and machine-annotated data, and anticipates dynamic motion that is not captured by linear models. Experimental evaluation confirms the benefits of the proposed model.