 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Prediction for Pulsar Noise with Long Short-Term Memory Network
Jun 02, 2026This work proposes a novel solution to predict pulsar timing residuals with limited data, addressing the critical challenge of data scarcity across spin-frequency subgroups of millisecond pulsars in PTA datasets. The proposed solution applies a Long Short-Term Memory (LSTM) network optimized using the model-agnostic meta-learning algorithm, enabling rapid adaptation to new frequency domain by fine-tuning the LSTM network with only a few-shot of ground truth timing residuals. Particle swarm optimization algorithm is also used for automatic hyperparameter optimization, leading to improved prediction accuracy. Our solution, evaluated on the second data release of the International Pulsar Timing Array (IPTA), demonstrates robust generalization with accurate predictions in three metrics across high-frequency test frequency domains, while requiring only 10% of the timing residuals from these domains for model fine-tuning. Furthermore, our lightweight structure only costs 16.86 MB CPU memory and 18 milliseconds for single-step residual prediction. All these characteristics make our solution highly suitable for real-world applications, where effective and real-time predictions of pulsar timing residuals are essential-particularly in resource-constrained environments with limited computational power, memory, or energy availability.
AllocMV: Optimal Resource Allocation for Music Video Generation via Structured Persistent State
May 11, 2026Generating long-horizon music videos (MVs) is frequently constrained by prohibitive computational costs and difficulty maintaining cross-shot consistency. We propose AllocMV, a hierarchical framework formulating music video synthesis as a Multiple-Choice Knapsack Problem (MCKP). AllocMV represents the video's persistent state as a compact, structured object comprising character entities, scene priors, and sharing graphs, produced by a global planner prior to realization. By estimating segment saliency from multimodal cues, a group-level MCKP solver based on dynamic programming optimally allocates resources across High-Gen, Mid-Gen, and Reuse branches. For repetitive musical motifs, we implement a divergence-based forking strategy that reuses visual prefixes to reduce costs while ensuring motif-level continuity. Evaluated via the Cost-Quality Ratio (CQR), AllocMV achieves an optimal trade-off between perceived quality and resource expenditure under strict budgetary and rhythmic constraints.
Spiking Layer-Adaptive Magnitude-based Pruning
Mar 16, 2026Spiking Neural Networks (SNNs) provide energy-efficient computation but their deployment is constrained by dense connectivity and high spiking operation costs. Existing magnitude-based pruning strategies, when naively applied to SNNs, fail to account for temporal accumulation, non-uniform timestep contributions, and membrane stability, often leading to severe performance degradation. This paper proposes Spiking Layer-Adaptive Magnitude-based Pruning (SLAMP), a theory-guided pruning framework that generalizes layer-adaptive magnitude pruning to temporal SNNs by explicitly controlling worst-case output distortion across layers and timesteps. SLAMP formulates sparsity allocation as a temporal distortion-constrained optimization problem, yielding time-aware layer importance scores that reduce to conventional layer-adaptive pruning in single-timestep limit. An efficient two-stage procedure is derived, combining temporal score estimation, global sparsity allocation, and magnitude pruning with retraining for stability recovery. Experiments on CIFAR10, CIFAR100, and the event-based CIFAR10-DVS datasets demonstrate that SLAMP achieves substantial connectivity and spiking operation reductions while preserving accuracy, enabling efficient and deployable SNN inference.
Co-PLNet: A Collaborative Point-Line Network for Prompt-Guided Wireframe Parsing
Jan 26, 2026Wireframe parsing aims to recover line segments and their junctions to form a structured geometric representation useful for downstream tasks such as Simultaneous Localization and Mapping (SLAM). Existing methods predict lines and junctions separately and reconcile them post-hoc, causing mismatches and reduced robustness. We present Co-PLNet, a point-line collaborative framework that exchanges spatial cues between the two tasks, where early detections are converted into spatial prompts via a Point-Line Prompt Encoder (PLP-Encoder), which encodes geometric attributes into compact and spatially aligned maps. A Cross-Guidance Line Decoder (CGL-Decoder) then refines predictions with sparse attention conditioned on complementary prompts, enforcing point-line consistency and efficiency. Experiments on Wireframe and YorkUrban show consistent improvements in accuracy and robustness, together with favorable real-time efficiency, demonstrating our effectiveness for structured geometry perception.
Adaptive Detector-Verifier Framework for Zero-Shot Polyp Detection in Open-World Settings
Dec 16, 2025Polyp detectors trained on clean datasets often underperform in real-world endoscopy, where illumination changes, motion blur, and occlusions degrade image quality. Existing approaches struggle with the domain gap between controlled laboratory conditions and clinical practice, where adverse imaging conditions are prevalent. In this work, we propose AdaptiveDetector, a novel two-stage detector-verifier framework comprising a YOLOv11 detector with a vision-language model (VLM) verifier. The detector adaptively adjusts per-frame confidence thresholds under VLM guidance, while the verifier is fine-tuned with Group Relative Policy Optimization (GRPO) using an asymmetric, cost-sensitive reward function specifically designed to discourage missed detections -- a critical clinical requirement. To enable realistic assessment under challenging conditions, we construct a comprehensive synthetic testbed by systematically degrading clean datasets with adverse conditions commonly encountered in clinical practice, providing a rigorous benchmark for zero-shot evaluation. Extensive zero-shot evaluation on synthetically degraded CVC-ClinicDB and Kvasir-SEG images demonstrates that our approach improves recall by 14 to 22 percentage points over YOLO alone, while precision remains within 0.7 points below to 1.7 points above the baseline. This combination of adaptive thresholding and cost-sensitive reinforcement learning achieves clinically aligned, open-world polyp detection with substantially fewer false negatives, thereby reducing the risk of missed precancerous polyps and improving patient outcomes.
GPG-HT: Generalized Policy Gradient with History-Aware Decision Transformer for Probabilistic Path Planning
Aug 24, 2025With the rapidly increased number of vehicles in urban areas, existing road infrastructure struggles to accommodate modern traffic demands, resulting in the issue of congestion. This highlights the importance of efficient path planning strategies. However, most recent navigation models focus solely on deterministic or time-dependent networks, while overlooking the correlations and the stochastic nature of traffic flows. In this work, we address the reliable shortest path problem within stochastic transportation networks under certain dependencies. We propose a path planning solution that integrates the decision Transformer with the Generalized Policy Gradient (GPG) framework. Based on the decision Transformer's capability to model long-term dependencies, our proposed solution improves the accuracy and stability of path decisions. Experimental results on the Sioux Falls Network (SFN) demonstrate that our approach outperforms previous baselines in terms of on-time arrival probability, providing more accurate path planning solutions.
Advancing Video Anomaly Detection: A Bi-Directional Hybrid Framework for Enhanced Single- and Multi-Task Approaches
Apr 20, 2025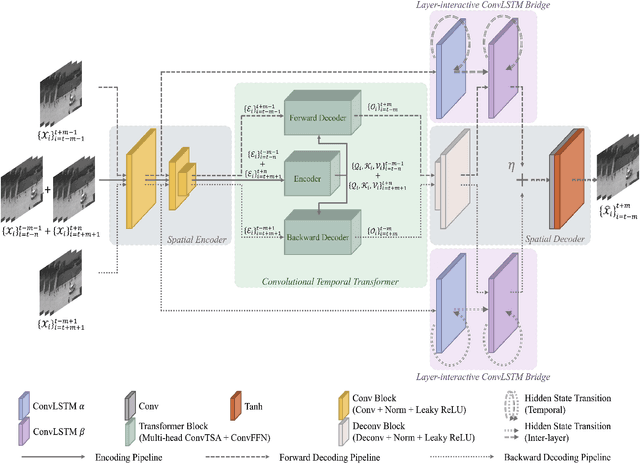
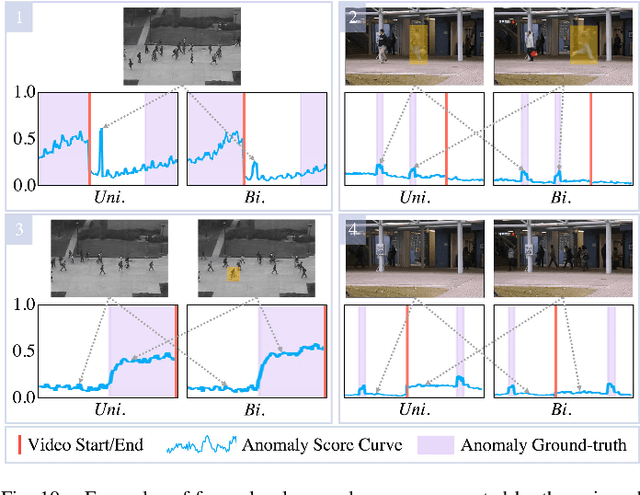
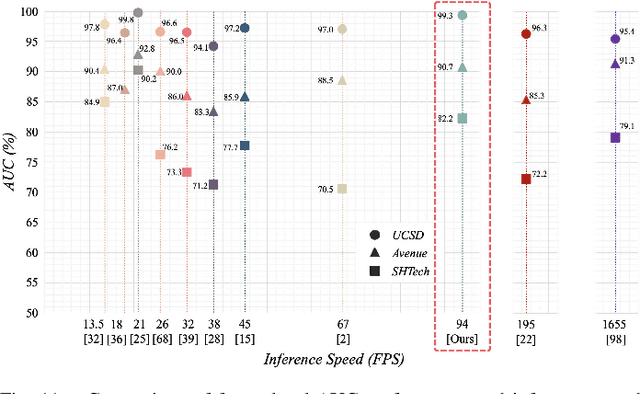
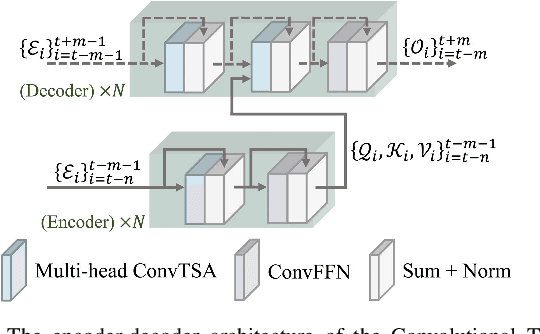
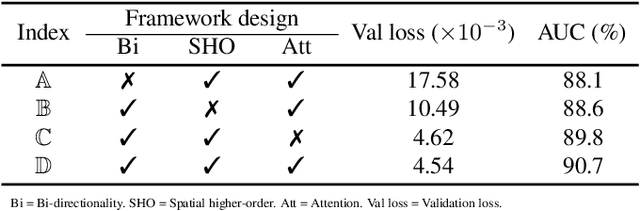
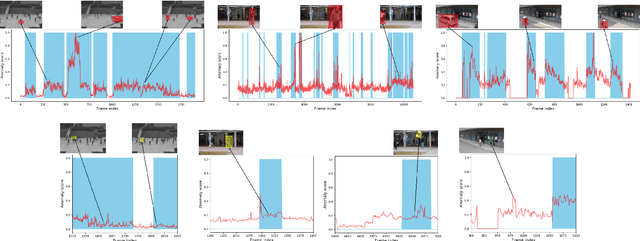
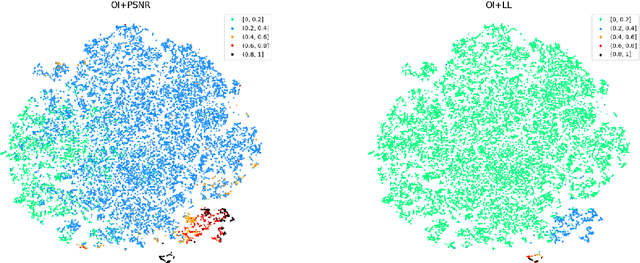
Despite the prevailing transition from single-task to multi-task approaches in video anomaly detection, we observe that many adopt sub-optimal frameworks for individual proxy tasks. Motivated by this, we contend that optimizing single-task frameworks can advance both single- and multi-task approaches. Accordingly, we leverage middle-frame prediction as the primary proxy task, and introduce an effective hybrid framework designed to generate accurate predictions for normal frames and flawed predictions for abnormal frames. This hybrid framework is built upon a bi-directional structure that seamlessly integrates both vision transformers and ConvLSTMs. Specifically, we utilize this bi-directional structure to fully analyze the temporal dimension by predicting frames in both forward and backward directions, significantly boosting the detection stability. Given the transformer's capacity to model long-range contextual dependencies, we develop a convolutional temporal transformer that efficiently associates feature maps from all context frames to generate attention-based predictions for target frames. Furthermore, we devise a layer-interactive ConvLSTM bridge that facilitates the smooth flow of low-level features across layers and time-steps, thereby strengthening predictions with fine details. Anomalies are eventually identified by scrutinizing the discrepancies between target frames and their corresponding predictions. Several experiments conducted on public benchmarks affirm the efficacy of our hybrid framework, whether used as a standalone single-task approach or integrated as a branch in a multi-task approach. These experiments also underscore the advantages of merging vision transformers and ConvLSTMs for video anomaly detection.
* Accepted by IEEE Transactions on Image Processing (TIP)
Look at Adjacent Frames: Video Anomaly Detection without Offline Training
Aug 04, 2022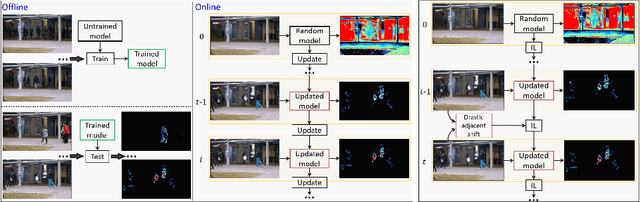


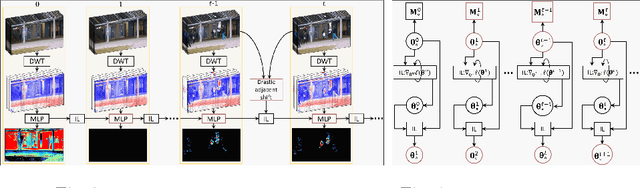
We propose a solution to detect anomalous events in videos without the need to train a model offline. Specifically, our solution is based on a randomly-initialized multilayer perceptron that is optimized online to reconstruct video frames, pixel-by-pixel, from their frequency information. Based on the information shifts between adjacent frames, an incremental learner is used to update parameters of the multilayer perceptron after observing each frame, thus allowing to detect anomalous events along the video stream. Traditional solutions that require no offline training are limited to operating on videos with only a few abnormal frames. Our solution breaks this limit and achieves strong performance on benchmark datasets.
Video Anomaly Detection via Prediction Network with Enhanced Spatio-Temporal Memory Exchange
Jun 26, 2022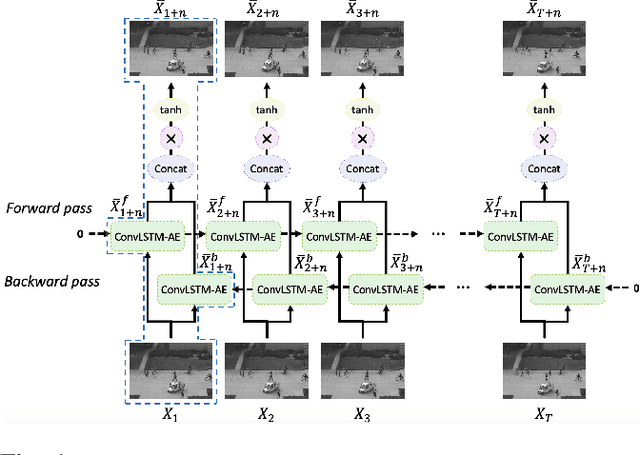
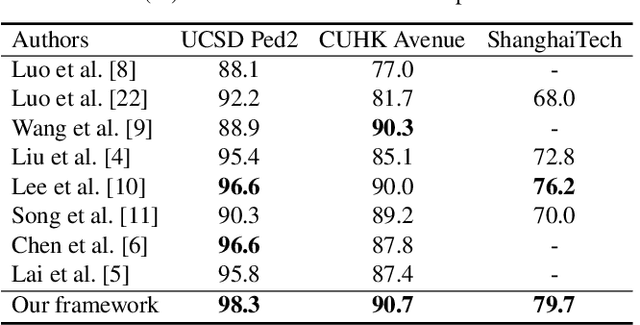
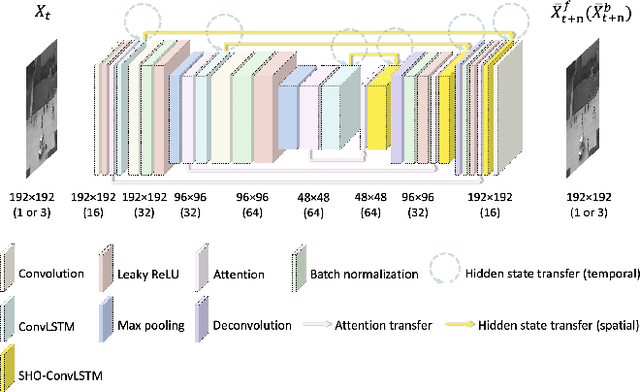
Video anomaly detection is a challenging task because most anomalies are scarce and non-deterministic. Many approaches investigate the reconstruction difference between normal and abnormal patterns, but neglect that anomalies do not necessarily correspond to large reconstruction errors. To address this issue, we design a Convolutional LSTM Auto-Encoder prediction framework with enhanced spatio-temporal memory exchange using bi-directionalilty and a higher-order mechanism. The bi-directional structure promotes learning the temporal regularity through forward and backward predictions. The unique higher-order mechanism further strengthens spatial information interaction between the encoder and the decoder. Considering the limited receptive fields in Convolutional LSTMs, we also introduce an attention module to highlight informative features for prediction. Anomalies are eventually identified by comparing the frames with their corresponding predictions. Evaluations on three popular benchmarks show that our framework outperforms most existing prediction-based anomaly detection methods.
Video Anomaly Detection by Estimating Likelihood of Representations
Dec 02, 2020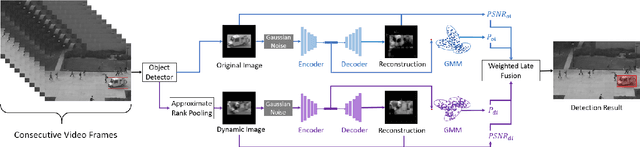
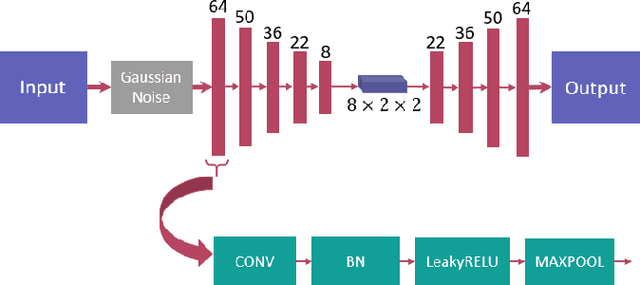
Video anomaly detection is a challenging task not only because it involves solving many sub-tasks such as motion representation, object localization and action recognition, but also because it is commonly considered as an unsupervised learning problem that involves detecting outliers. Traditionally, solutions to this task have focused on the mapping between video frames and their low-dimensional features, while ignoring the spatial connections of those features. Recent solutions focus on analyzing these spatial connections by using hard clustering techniques, such as K-Means, or applying neural networks to map latent features to a general understanding, such as action attributes. In order to solve video anomaly in the latent feature space, we propose a deep probabilistic model to transfer this task into a density estimation problem where latent manifolds are generated by a deep denoising autoencoder and clustered by expectation maximization. Evaluations on several benchmarks datasets show the strengths of our model, achieving outstanding performance on challenging datasets.