 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Security and Safety: Insights from Homotopy-Inspired Prompt Obfuscation
Jan 20, 2026In this study, we propose a homotopy-inspired prompt obfuscation framework to enhance understanding of security and safety vulnerabilities in Large Language Models (LLMs). By systematically applying carefully engineered prompts, we demonstrate how latent model behaviors can be influenced in unexpected ways. Our experiments encompassed 15,732 prompts, including 10,000 high-priority cases, across LLama, Deepseek, KIMI for code generation, and Claude to verify. The results reveal critical insights into current LLM safeguards, highlighting the need for more robust defense mechanisms, reliable detection strategies, and improved resilience. Importantly, this work provides a principled framework for analyzing and mitigating potential weaknesses, with the goal of advancing safe, responsible, and trustworthy AI technologies.
SBAN: A Framework \& Multi-Dimensional Dataset for Large Language Model Pre-Training and Software Code Mining
Oct 21, 2025This paper introduces SBAN (Source code, Binary, Assembly, and Natural Language Description), a large-scale, multi-dimensional dataset designed to advance the pre-training and evaluation of large language models (LLMs) for software code analysis. SBAN comprises more than 3 million samples, including 2.9 million benign and 672,000 malware respectively, each represented across four complementary layers: binary code, assembly instructions, natural language descriptions, and source code. This unique multimodal structure enables research on cross-representation learning, semantic understanding of software, and automated malware detection. Beyond security applications, SBAN supports broader tasks such as code translation, code explanation, and other software mining tasks involving heterogeneous data. It is particularly suited for scalable training of deep models, including transformers and other LLM architectures. By bridging low-level machine representations and high-level human semantics, SBAN provides a robust foundation for building intelligent systems that reason about code. We believe that this dataset opens new opportunities for mining software behavior, improving security analytics, and enhancing LLM capabilities in pre-training and fine-tuning tasks for software code mining.
XGen-Q: An Explainable Domain-Adaptive LLM Framework with Retrieval-Augmented Generation for Software Security
Oct 21, 2025Generative AI and large language models (LLMs) have shown strong capabilities in code understanding, but their use in cybersecurity, particularly for malware detection and analysis, remains limited. Existing detection systems often fail to generalize to obfuscated or previously unseen threats, underscoring the need for more adaptable and explainable models. To address this challenge, we introduce XGen-Q, a domain-adapted LLM built on the Qwen-Coder architecture and pretrained on a large-scale corpus of over one million malware samples, spanning both source and assembly code. XGen-Q uses a multi-stage prompt strategy combined with retrieval-augmented generation (RAG) to deliver reliable malware identification and detailed forensic reporting, even in the presence of complex code obfuscation. To further enhance generalization, we design a training pipeline that systematically exposes the model to diverse obfuscation patterns. Experimental results show that XGen-Q achieves significantly lower perplexity than competitive baselines and exhibits strong performance on novel malware samples, demonstrating the promise of LLM-based approaches for interpretable and robust malware analysis.
FlexiDataGen: An Adaptive LLM Framework for Dynamic Semantic Dataset Generation in Sensitive Domains
Oct 21, 2025Dataset availability and quality remain critical challenges in machine learning, especially in domains where data are scarce, expensive to acquire, or constrained by privacy regulations. Fields such as healthcare, biomedical research, and cybersecurity frequently encounter high data acquisition costs, limited access to annotated data, and the rarity or sensitivity of key events. These issues-collectively referred to as the dataset challenge-hinder the development of accurate and generalizable machine learning models in such high-stakes domains. To address this, we introduce FlexiDataGen, an adaptive large language model (LLM) framework designed for dynamic semantic dataset generation in sensitive domains. FlexiDataGen autonomously synthesizes rich, semantically coherent, and linguistically diverse datasets tailored to specialized fields. The framework integrates four core components: (1) syntactic-semantic analysis, (2) retrieval-augmented generation, (3) dynamic element injection, and (4) iterative paraphrasing with semantic validation. Together, these components ensure the generation of high-quality, domain-relevant data. Experimental results show that FlexiDataGen effectively alleviates data shortages and annotation bottlenecks, enabling scalable and accurate machine learning model development.
Dual Explanations via Subgraph Matching for Malware Detection
Apr 29, 2025



Interpretable malware detection is crucial for understanding harmful behaviors and building trust in automated security systems. Traditional explainable methods for Graph Neural Networks (GNNs) often highlight important regions within a graph but fail to associate them with known benign or malicious behavioral patterns. This limitation reduces their utility in security contexts, where alignment with verified prototypes is essential. In this work, we introduce a novel dual prototype-driven explainable framework that interprets GNN-based malware detection decisions. This dual explainable framework integrates a base explainer (a state-of-the-art explainer) with a novel second-level explainer which is designed by subgraph matching technique, called SubMatch explainer. The proposed explainer assigns interpretable scores to nodes based on their association with matched subgraphs, offering a fine-grained distinction between benign and malicious regions. This prototype-guided scoring mechanism enables more interpretable, behavior-aligned explanations. Experimental results demonstrate that our method preserves high detection performance while significantly improving interpretability in malware analysis.
On the Consistency of GNN Explanations for Malware Detection
Apr 22, 2025Control Flow Graphs (CFGs) are critical for analyzing program execution and characterizing malware behavior. With the growing adoption of Graph Neural Networks (GNNs), CFG-based representations have proven highly effective for malware detection. This study proposes a novel framework that dynamically constructs CFGs and embeds node features using a hybrid approach combining rule-based encoding and autoencoder-based embedding. A GNN-based classifier is then constructed to detect malicious behavior from the resulting graph representations. To improve model interpretability, we apply state-of-the-art explainability techniques, including GNNExplainer, PGExplainer, and CaptumExplainer, the latter is utilized three attribution methods: Integrated Gradients, Guided Backpropagation, and Saliency. In addition, we introduce a novel aggregation method, called RankFusion, that integrates the outputs of the top-performing explainers to enhance the explanation quality. We also evaluate explanations using two subgraph extraction strategies, including the proposed Greedy Edge-wise Composition (GEC) method for improved structural coherence. A comprehensive evaluation using accuracy, fidelity, and consistency metrics demonstrates the effectiveness of the proposed framework in terms of accurate identification of malware samples and generating reliable and interpretable explanations.
Proxy-Anchor and EVT-Driven Continual Learning Method for Generalized Category Discovery
Apr 11, 2025



Continual generalized category discovery has been introduced and studied in the literature as a method that aims to continuously discover and learn novel categories in incoming data batches while avoiding catastrophic forgetting of previously learned categories. A key component in addressing this challenge is the model's ability to separate novel samples, where Extreme Value Theory (EVT) has been effectively employed. In this work, we propose a novel method that integrates EVT with proxy anchors to define boundaries around proxies using a probability of inclusion function, enabling the rejection of unknown samples. Additionally, we introduce a novel EVT-based loss function to enhance the learned representation, achieving superior performance compared to other deep-metric learning methods in similar settings. Using the derived probability functions, novel samples are effectively separated from previously known categories. However, category discovery within these novel samples can sometimes overestimate the number of new categories. To mitigate this issue, we propose a novel EVT-based approach to reduce the model size and discard redundant proxies. We also incorporate experience replay and knowledge distillation mechanisms during the continual learning stage to prevent catastrophic forgetting. Experimental results demonstrate that our proposed approach outperforms state-of-the-art methods in continual generalized category discovery scenarios.
Large Language Model (LLM) for Software Security: Code Analysis, Malware Analysis, Reverse Engineering
Apr 07, 2025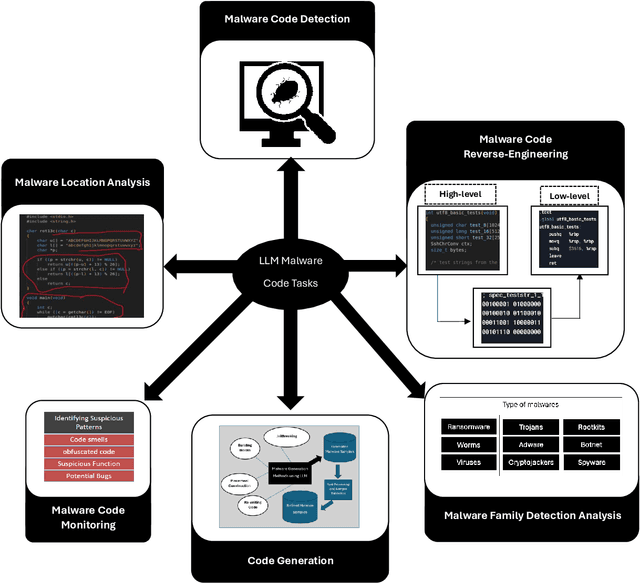
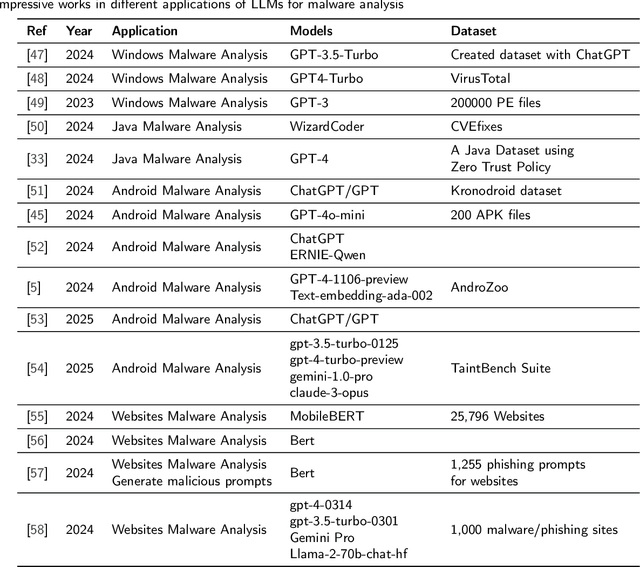
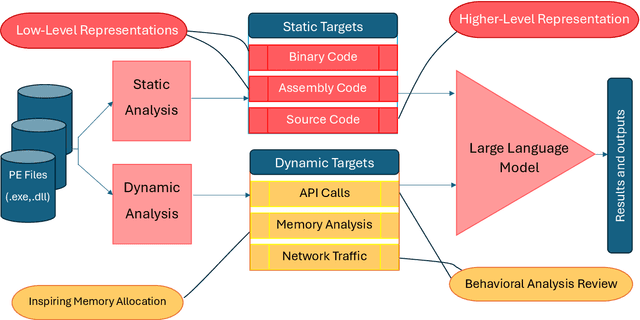
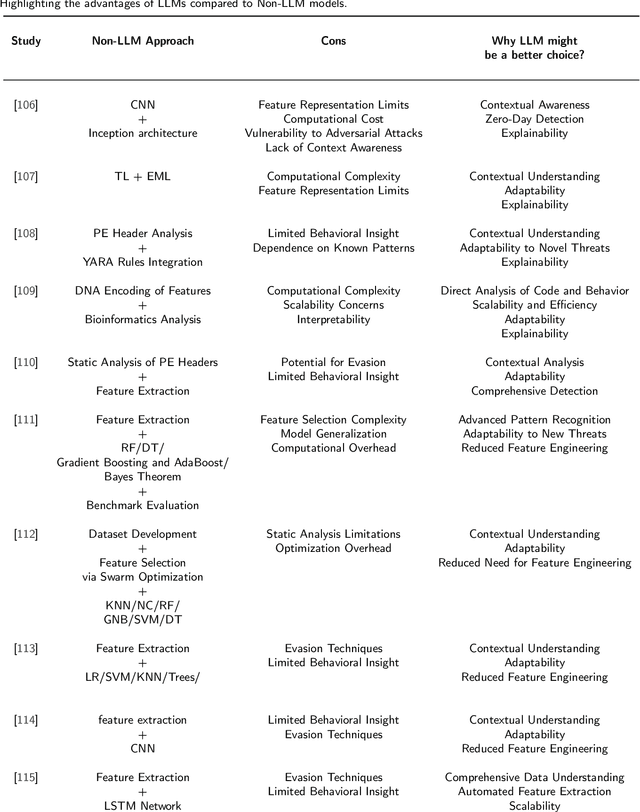
Large Language Models (LLMs) have recently emerged as powerful tools in cybersecurity, offering advanced capabilities in malware detection, generation, and real-time monitoring. Numerous studies have explored their application in cybersecurity, demonstrating their effectiveness in identifying novel malware variants, analyzing malicious code structures, and enhancing automated threat analysis. Several transformer-based architectures and LLM-driven models have been proposed to improve malware analysis, leveraging semantic and structural insights to recognize malicious intent more accurately. This study presents a comprehensive review of LLM-based approaches in malware code analysis, summarizing recent advancements, trends, and methodologies. We examine notable scholarly works to map the research landscape, identify key challenges, and highlight emerging innovations in LLM-driven cybersecurity. Additionally, we emphasize the role of static analysis in malware detection, introduce notable datasets and specialized LLM models, and discuss essential datasets supporting automated malware research. This study serves as a valuable resource for researchers and cybersecurity professionals, offering insights into LLM-powered malware detection and defence strategies while outlining future directions for strengthening cybersecurity resilience.
FedNIA: Noise-Induced Activation Analysis for Mitigating Data Poisoning in FL
Feb 23, 2025Federated learning systems are increasingly threatened by data poisoning attacks, where malicious clients compromise global models by contributing tampered updates. Existing defenses often rely on impractical assumptions, such as access to a central test dataset, or fail to generalize across diverse attack types, particularly those involving multiple malicious clients working collaboratively. To address this, we propose Federated Noise-Induced Activation Analysis (FedNIA), a novel defense framework to identify and exclude adversarial clients without relying on any central test dataset. FedNIA injects random noise inputs to analyze the layerwise activation patterns in client models leveraging an autoencoder that detects abnormal behaviors indicative of data poisoning. FedNIA can defend against diverse attack types, including sample poisoning, label flipping, and backdoors, even in scenarios with multiple attacking nodes. Experimental results on non-iid federated datasets demonstrate its effectiveness and robustness, underscoring its potential as a foundational approach for enhancing the security of federated learning systems.
TrustChain: A Blockchain Framework for Auditing and Verifying Aggregators in Decentralized Federated Learning
Feb 23, 2025The server-less nature of Decentralized Federated Learning (DFL) requires allocating the aggregation role to specific participants in each federated round. Current DFL architectures ensure the trustworthiness of the aggregator node upon selection. However, most of these studies overlook the possibility that the aggregating node may turn rogue and act maliciously after being nominated. To address this problem, this paper proposes a DFL structure, called TrustChain, that scores the aggregators before selection based on their past behavior and additionally audits them after the aggregation. To do this, the statistical independence between the client updates and the aggregated model is continuously monitored using the Hilbert-Schmidt Independence Criterion (HSIC). The proposed method relies on several principles, including blockchain, anomaly detection, and concept drift analysis. The designed structure is evaluated on several federated datasets and attack scenarios with different numbers of Byzantine nodes.