 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShifting from endangerment to rebirth in the Artificial Intelligence Age: An Ensemble Machine Learning Approach for Hawrami Text Classification
Sep 25, 2024
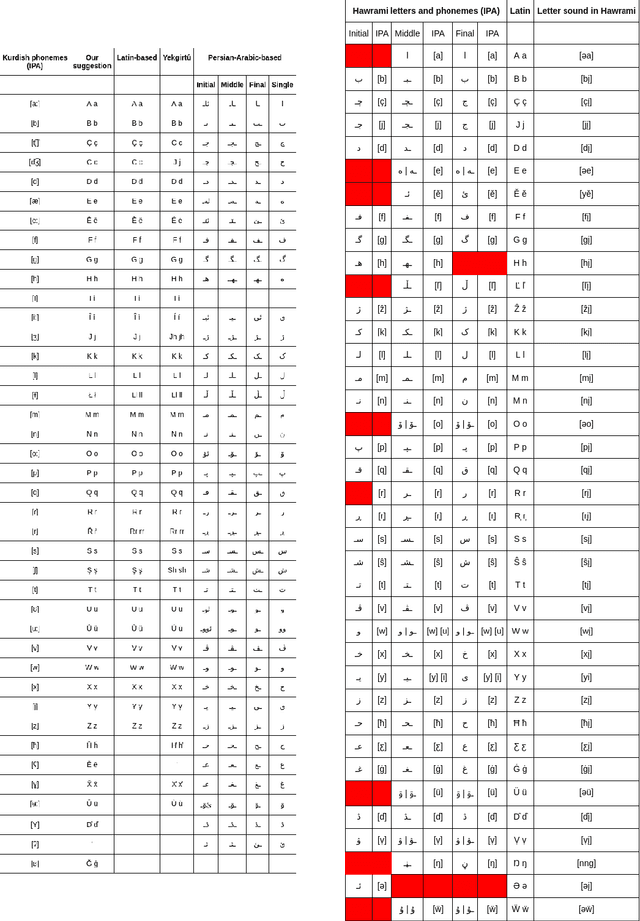
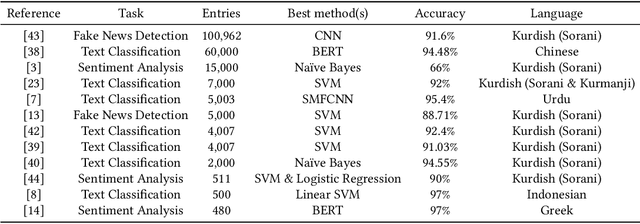
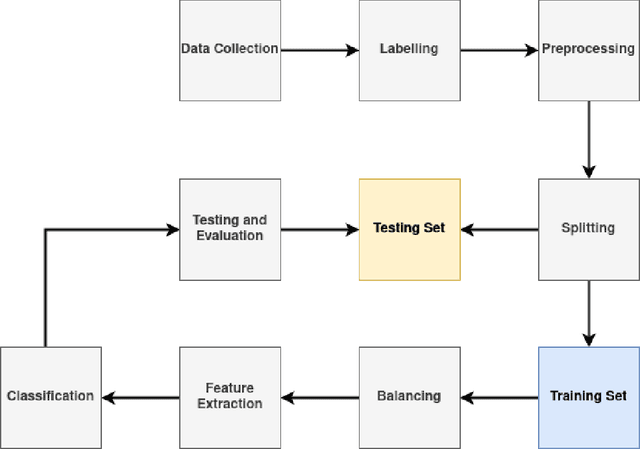
Hawrami, a dialect of Kurdish, is classified as an endangered language as it suffers from the scarcity of data and the gradual loss of its speakers. Natural Language Processing projects can be used to partially compensate for data availability for endangered languages/dialects through a variety of approaches, such as machine translation, language model building, and corpora development. Similarly, NLP projects such as text classification are in language documentation. Several text classification studies have been conducted for Kurdish, but they were mainly dedicated to two particular dialects: Sorani (Central Kurdish) and Kurmanji (Northern Kurdish). In this paper, we introduce various text classification models using a dataset of 6,854 articles in Hawrami labeled into 15 categories by two native speakers. We use K-nearest Neighbor (KNN), Linear Support Vector Machine (Linear SVM), Logistic Regression (LR), and Decision Tree (DT) to evaluate how well those methods perform the classification task. The results indicate that the Linear SVM achieves a 96% of accuracy and outperforms the other approaches.