 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUDIDI: A Two-Stage Framework for Multilingual Dictionary Digitization with Language Models
Jun 08, 2026Multilingual dictionaries are among the most valuable documentary resources for low-resource and endangered languages, yet many remain available only as scans. For many decades, their digitization and conversion into a machine-readable format was nearly impossible due to language-specific scripts, complex multi-column layouts full of entries with abbreviations and cross-references. Recent vision-language models offer a promising solution, but it is unclear how well they preserve characters, markup, and process lexicographic structure. We introduce MUDIDI, a two-stage framework for multi-lingual dictionary digitization. Stage One evaluates the quality of character recognition and markup preservation; Stage Two focuses on dictionary entry segmentation with subsequent mapping into a machine-readable lexicographic schema, SIL's Multi-Dictionary Formatter. We also release a dataset that consists of human-annotated lexicographic entries collected from 30 public-domain dictionaries featuring diverse writing systems, language families, and formats. We benchmark OCR systems, general-purpose Large Language Models (LLMs), and Vision Language Models (VLMs) on the dataset, demonstrating superior performance of LLMs across most writing systems and languages in both stages, and provide practical guidelines on improving the results for more challenging scenarios. Finally, we show that supplementing additional information, such as dictionary introduction, to the LLMs can improve the quality of the digitized dictionary. Github: https://github.com/DavidSamuell/MUDIDI-Pipeline-for-Digitization-of-Multilingual-Dictionary/
Script-Agnostic Language Identification
Jun 25, 2024Language identification is used as the first step in many data collection and crawling efforts because it allows us to sort online text into language-specific buckets. However, many modern languages, such as Konkani, Kashmiri, Punjabi etc., are synchronically written in several scripts. Moreover, languages with different writing systems do not share significant lexical, semantic, and syntactic properties in neural representation spaces, which is a disadvantage for closely related languages and low-resource languages, especially those from the Indian Subcontinent. To counter this, we propose learning script-agnostic representations using several different experimental strategies (upscaling, flattening, and script mixing) focusing on four major Dravidian languages (Tamil, Telugu, Kannada, and Malayalam). We find that word-level script randomization and exposure to a language written in multiple scripts is extremely valuable for downstream script-agnostic language identification, while also maintaining competitive performance on naturally occurring text.
LIMIT: Language Identification, Misidentification, and Translation using Hierarchical Models in 350+ Languages
May 23, 2023Knowing the language of an input text/audio is a necessary first step for using almost every natural language processing (NLP) tool such as taggers, parsers, or translation systems. Language identification is a well-studied problem, sometimes even considered solved; in reality, most of the world's 7000 languages are not supported by current systems. This lack of representation affects large-scale data mining efforts and further exacerbates data shortage for low-resource languages. We take a step towards tackling the data bottleneck by compiling a corpus of over 50K parallel children's stories in 350+ languages and dialects, and the computation bottleneck by building lightweight hierarchical models for language identification. Our data can serve as benchmark data for language identification of short texts and for understudied translation directions such as those between Indian or African languages. Our proposed method, Hierarchical LIMIT, uses limited computation to expand coverage into excluded languages while maintaining prediction quality.
Queer In AI: A Case Study in Community-Led Participatory AI
Apr 10, 2023We present Queer in AI as a case study for community-led participatory design in AI. We examine how participatory design and intersectional tenets started and shaped this community's programs over the years. We discuss different challenges that emerged in the process, look at ways this organization has fallen short of operationalizing participatory and intersectional principles, and then assess the organization's impact. Queer in AI provides important lessons and insights for practitioners and theorists of participatory methods broadly through its rejection of hierarchy in favor of decentralization, success at building aid and programs by and for the queer community, and effort to change actors and institutions outside of the queer community. Finally, we theorize how communities like Queer in AI contribute to the participatory design in AI more broadly by fostering cultures of participation in AI, welcoming and empowering marginalized participants, critiquing poor or exploitative participatory practices, and bringing participation to institutions outside of individual research projects. Queer in AI's work serves as a case study of grassroots activism and participatory methods within AI, demonstrating the potential of community-led participatory methods and intersectional praxis, while also providing challenges, case studies, and nuanced insights to researchers developing and using participatory methods.
PALI: A Language Identification Benchmark for Perso-Arabic Scripts
Apr 03, 2023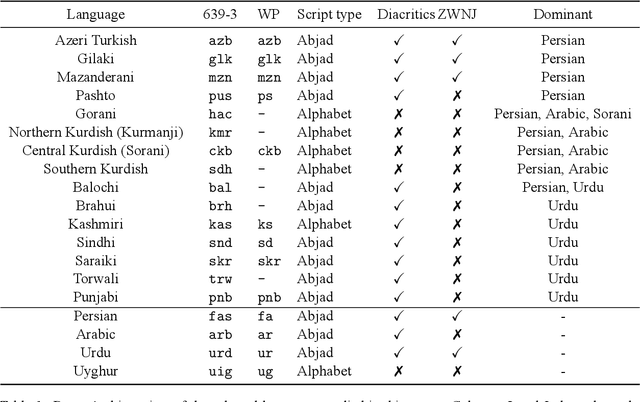
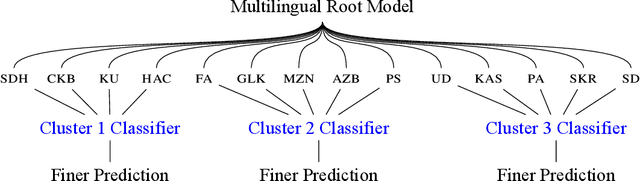
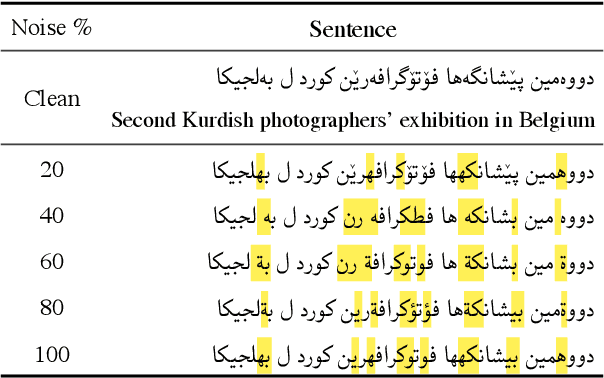
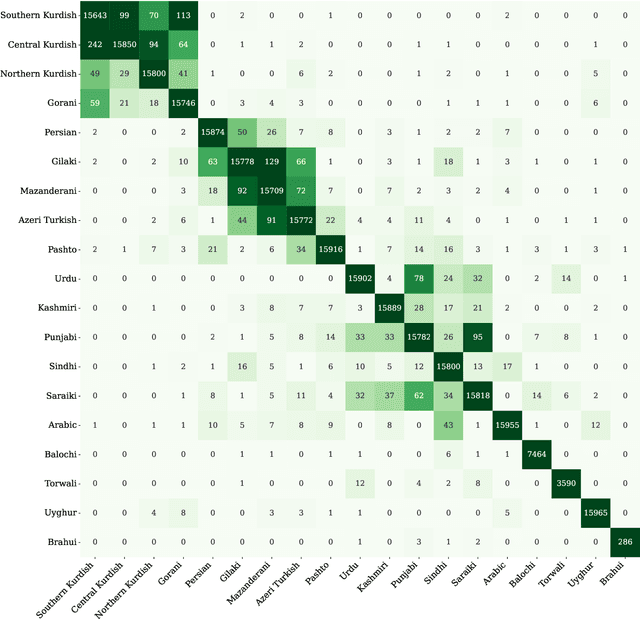
The Perso-Arabic scripts are a family of scripts that are widely adopted and used by various linguistic communities around the globe. Identifying various languages using such scripts is crucial to language technologies and challenging in low-resource setups. As such, this paper sheds light on the challenges of detecting languages using Perso-Arabic scripts, especially in bilingual communities where ``unconventional'' writing is practiced. To address this, we use a set of supervised techniques to classify sentences into their languages. Building on these, we also propose a hierarchical model that targets clusters of languages that are more often confused by the classifiers. Our experiment results indicate the effectiveness of our solutions.