 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding In-Context Learning with a Pelican Soup Framework
Feb 16, 2024



Many existing theoretical analyses of in-context learning for natural language processing are based on latent variable models that leaves gaps between theory and practice. We aim to close these gaps by proposing a theoretical framework, the Pelican Soup Framework. In this framework, we introduce (1) the notion of a common sense knowledge base, (2) a general formalism for natural language classification tasks, and the notion of (3) meaning association. Under this framework, we can establish a $\mathcal{O}(1/T)$ loss bound for in-context learning, where $T$ is the number of example-label pairs in the demonstration. Compared with previous works, our bound reflects the effect of the choice of verbalizers and the effect of instruction tuning. An additional notion of \textit{atom concepts} makes our framework possible to explain the generalization to tasks unseen in the language model training data. Finally, we propose a toy setup, Calcutec, and a digit addition task that mimics types of distribution shifts a model needs to overcome to perform in-context learning. We also experiment with GPT2-Large on real-world NLP tasks. Our empirical results demonstrate the efficacy of our framework to explain in-context learning.
On Retrieval Augmentation and the Limitations of Language Model Training
Nov 16, 2023Augmenting a language model (LM) with $k$-nearest neighbors (kNN) retrieval on its training data alone can decrease its perplexity, though the underlying reasons for this remains elusive. In this work, we first rule out one previously posited possibility -- the "softmax bottleneck." We further identify the MLP hurdle phenomenon, where the final MLP layer in LMs may impede LM optimization early on. We explore memorization and generalization in language models with two new datasets, where advanced model like GPT-3.5-turbo find generalizing to irrelevant information in the training data challenging. However, incorporating kNN retrieval to vanilla GPT-2 117M can consistently improve performance in this setting.
The Distributional Hypothesis Does Not Fully Explain the Benefits of Masked Language Model Pretraining
Oct 25, 2023



We analyze the masked language modeling pretraining objective function from the perspective of the distributional hypothesis. We investigate whether better sample efficiency and the better generalization capability of models pretrained with masked language modeling can be attributed to the semantic similarity encoded in the pretraining data's distributional property. Via a synthetic dataset, our analysis suggests that distributional property indeed leads to the better sample efficiency of pretrained masked language models, but does not fully explain the generalization capability. We also conduct analyses over two real-world datasets and demonstrate that the distributional property does not explain the generalization ability of pretrained natural language models either. Our results illustrate our limited understanding of model pretraining and provide future research directions.
DialCrowd 2.0: A Quality-Focused Dialog System Crowdsourcing Toolkit
Jul 25, 2022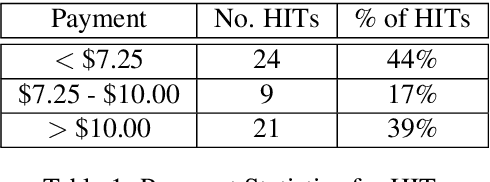
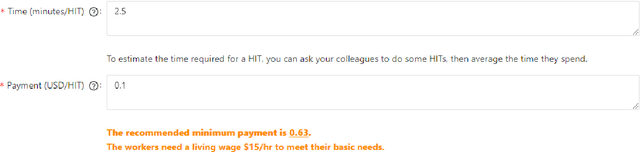
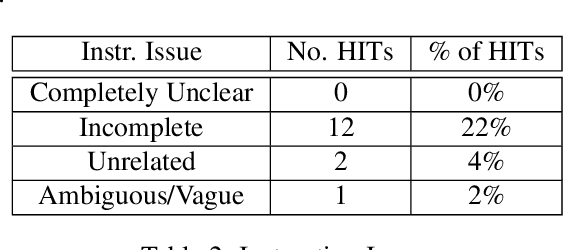
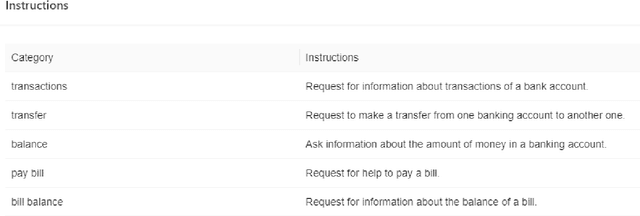
Dialog system developers need high-quality data to train, fine-tune and assess their systems. They often use crowdsourcing for this since it provides large quantities of data from many workers. However, the data may not be of sufficiently good quality. This can be due to the way that the requester presents a task and how they interact with the workers. This paper introduces DialCrowd 2.0 to help requesters obtain higher quality data by, for example, presenting tasks more clearly and facilitating effective communication with workers. DialCrowd 2.0 guides developers in creating improved Human Intelligence Tasks (HITs) and is directly applicable to the workflows used currently by developers and researchers.
Breaking Down Multilingual Machine Translation
Oct 15, 2021
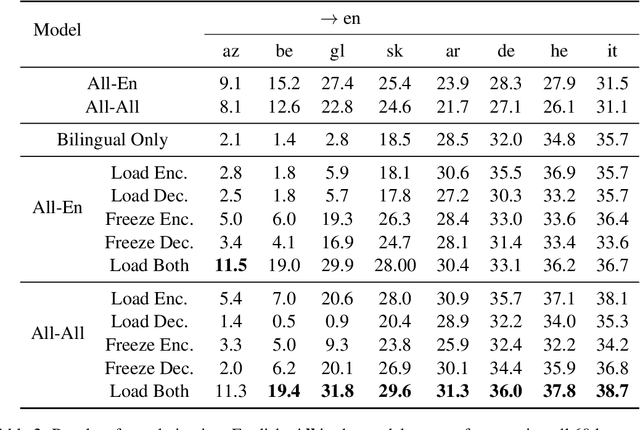
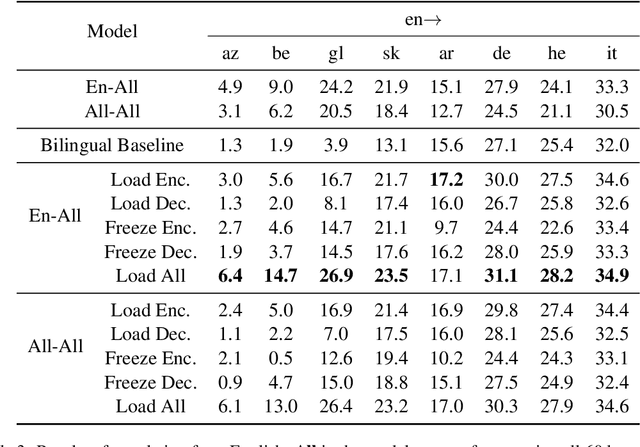
While multilingual training is now an essential ingredient in machine translation (MT) systems, recent work has demonstrated that it has different effects in different multilingual settings, such as many-to-one, one-to-many, and many-to-many learning. These training settings expose the encoder and the decoder in a machine translation model with different data distributions. In this paper, we examine how different varieties of multilingual training contribute to learning these two components of the MT model. Specifically, we compare bilingual models with encoders and/or decoders initialized by multilingual training. We show that multilingual training is beneficial to encoders in general, while it only benefits decoders for low-resource languages (LRLs). We further find the important attention heads for each language pair and compare their correlations during inference. Our analysis sheds light on how multilingual translation models work and also enables us to propose methods to improve performance by training with highly related languages. Our many-to-one models for high-resource languages and one-to-many models for LRL outperform the best results reported by Aharoni et al. (2019).
Are you doing what I say? On modalities alignment in ALFRED
Oct 12, 2021
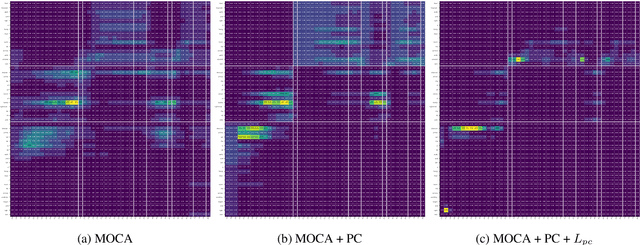
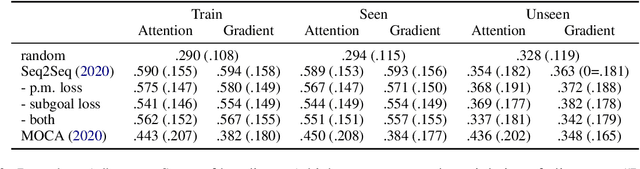
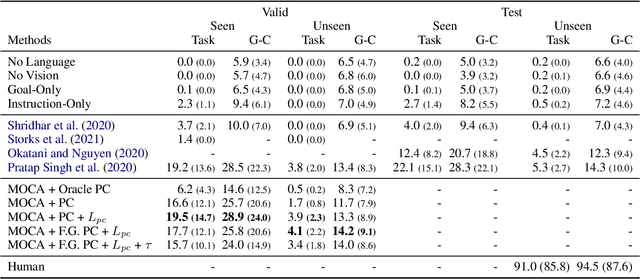
ALFRED is a recently proposed benchmark that requires a model to complete tasks in simulated house environments specified by instructions in natural language. We hypothesize that key to success is accurately aligning the text modality with visual inputs. Motivated by this, we inspect how well existing models can align these modalities using our proposed intrinsic metric, boundary adherence score (BAS). The results show the previous models are indeed failing to perform proper alignment. To address this issue, we introduce approaches aimed at improving model alignment and demonstrate how improved alignment, improves end task performance.
On a Benefit of Mask Language Modeling: Robustness to Simplicity Bias
Oct 11, 2021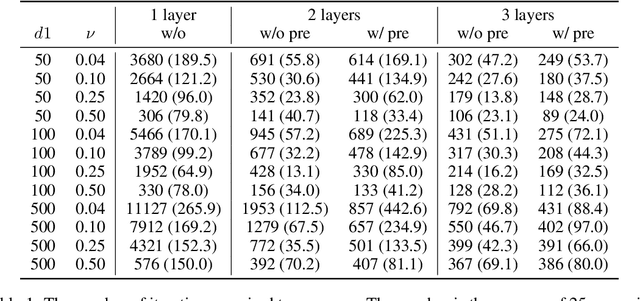
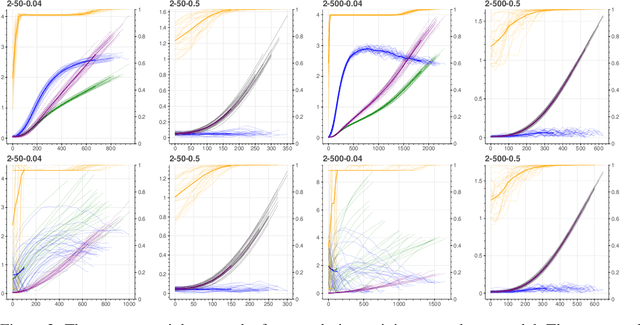
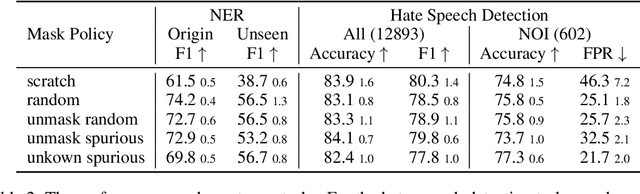
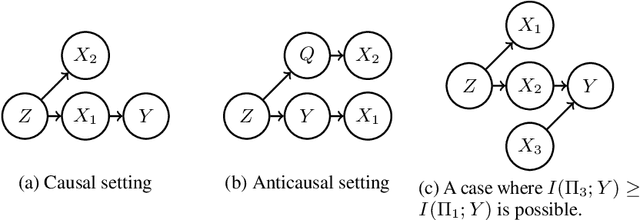
Despite the success of pretrained masked language models (MLM), why MLM pretraining is useful is still a qeustion not fully answered. In this work we theoretically and empirically show that MLM pretraining makes models robust to lexicon-level spurious features, partly answer the question. We theoretically show that, when we can model the distribution of a spurious feature $\Pi$ conditioned on the context, then (1) $\Pi$ is at least as informative as the spurious feature, and (2) learning from $\Pi$ is at least as simple as learning from the spurious feature. Therefore, MLM pretraining rescues the model from the simplicity bias caused by the spurious feature. We also explore the efficacy of MLM pretraing in causal settings. Finally we close the gap between our theories and the real world practices by conducting experiments on the hate speech detection and the name entity recognition tasks.
Improving Dialogue State Tracking by Joint Slot Modeling
Sep 29, 2021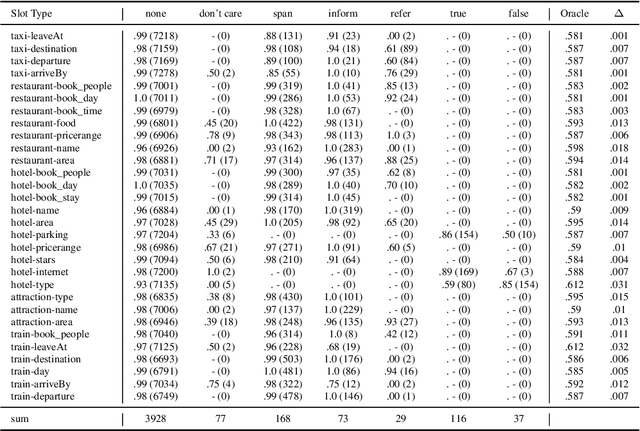
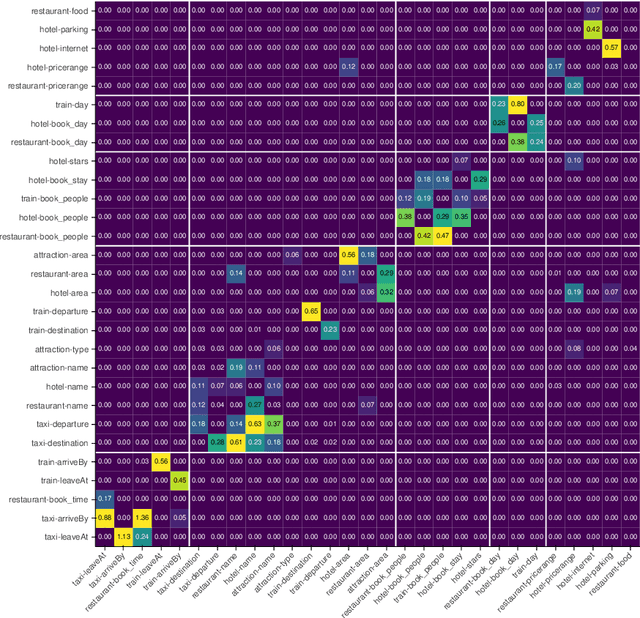
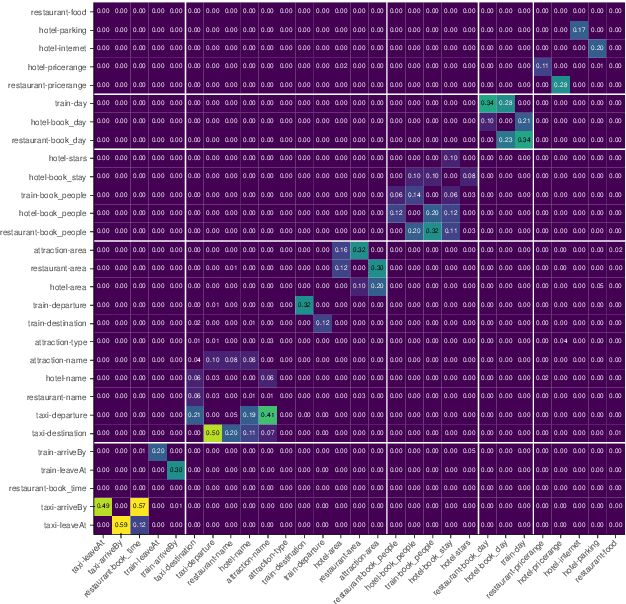
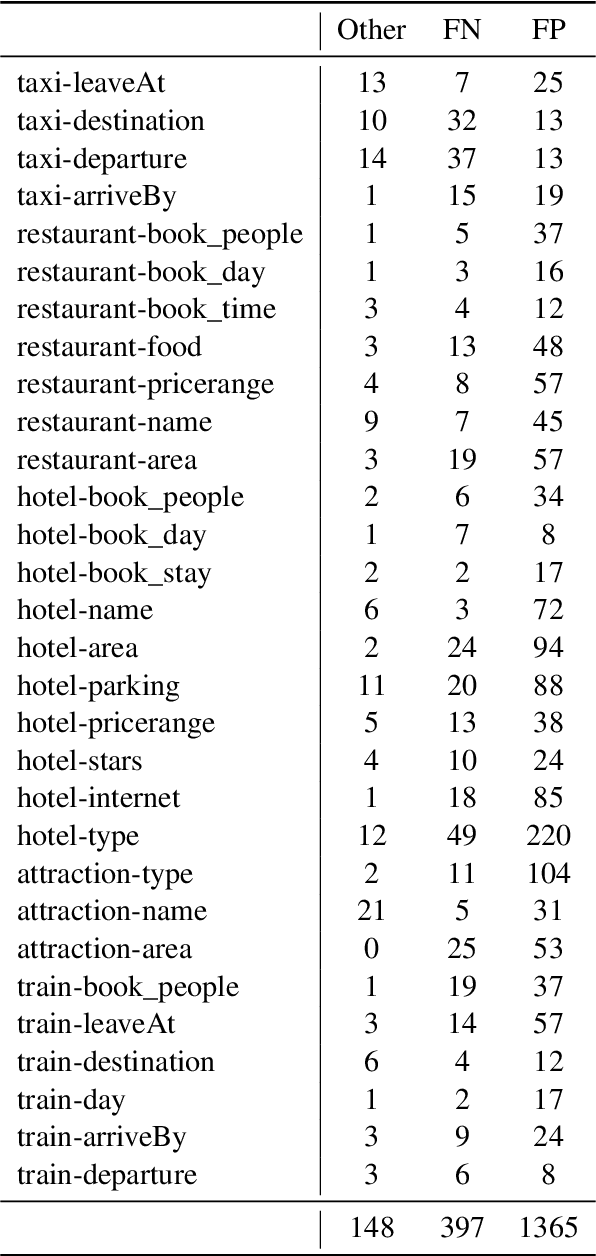
Dialogue state tracking models play an important role in a task-oriented dialogue system. However, most of them model the slot types conditionally independently given the input. We discover that it may cause the model to be confused by slot types that share the same data type. To mitigate this issue, we propose TripPy-MRF and TripPy-LSTM that models the slots jointly. Our results show that they are able to alleviate the confusion mentioned above, and they push the state-of-the-art on dataset MultiWoZ 2.1 from 58.7 to 61.3. Our implementation is available at https://github.com/CTinRay/Trippy-Joint.
Relating Neural Text Degeneration to Exposure Bias
Sep 17, 2021
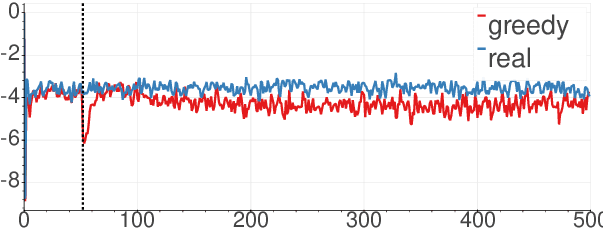
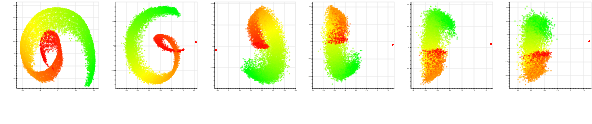
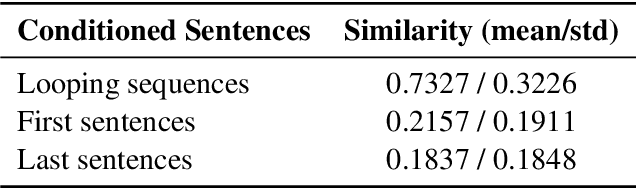
This work focuses on relating two mysteries in neural-based text generation: exposure bias, and text degeneration. Despite the long time since exposure bias was mentioned and the numerous studies for its remedy, to our knowledge, its impact on text generation has not yet been verified. Text degeneration is a problem that the widely-used pre-trained language model GPT-2 was recently found to suffer from (Holtzman et al., 2020). Motivated by the unknown causation of the text degeneration, in this paper we attempt to relate these two mysteries. Specifically, we first qualitatively quantitatively identify mistakes made before text degeneration occurs. Then we investigate the significance of the mistakes by inspecting the hidden states in GPT-2. Our results show that text degeneration is likely to be partly caused by exposure bias. We also study the self-reinforcing mechanism of text degeneration, explaining why the mistakes amplify. In sum, our study provides a more concrete foundation for further investigation on exposure bias and text degeneration problems.
Why Can You Lay Off Heads? Investigating How BERT Heads Transfer
Jun 14, 2021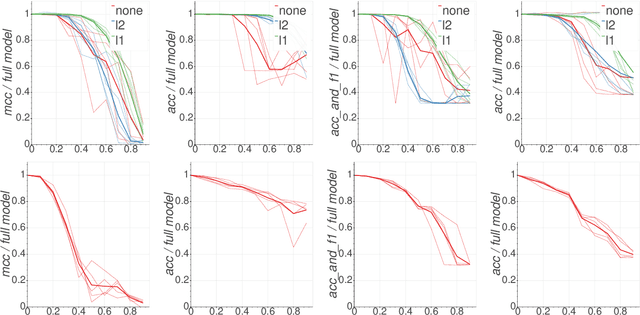
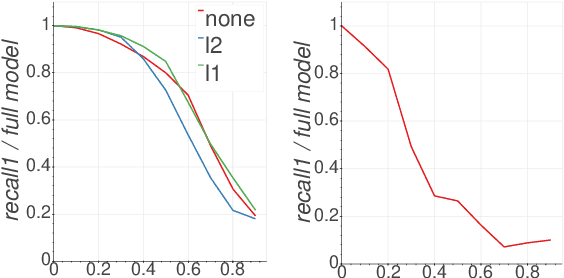
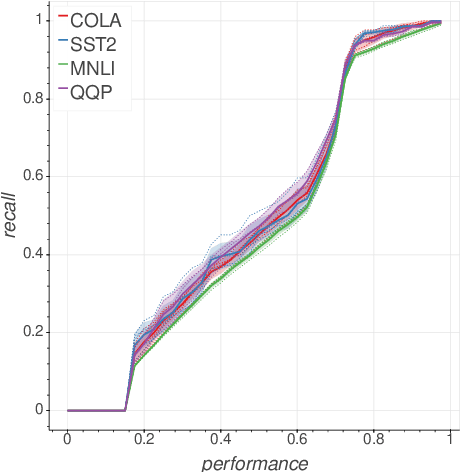
The huge size of the widely used BERT family models has led to recent efforts about model distillation. The main goal of distillation is to create a task-agnostic pre-trained model that can be fine-tuned on downstream tasks without fine-tuning its full-sized version. Despite the progress of distillation, to what degree and for what reason a task-agnostic model can be created from distillation has not been well studied. Also, the mechanisms behind transfer learning of those BERT models are not well investigated either. Therefore, this work focuses on analyzing the acceptable deduction when distillation for guiding the future distillation procedure. Specifically, we first inspect the prunability of the Transformer heads in RoBERTa and ALBERT using their head importance estimation proposed by Michel et al. (2019), and then check the coherence of the important heads between the pre-trained task and downstream tasks. Hence, the acceptable deduction of performance on the pre-trained task when distilling a model can be derived from the results, and we further compare the behavior of the pruned model before and after fine-tuning. Our studies provide guidance for future directions about BERT family model distillation.