 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn a Benefit of Mask Language Modeling: Robustness to Simplicity Bias
Paper and Code
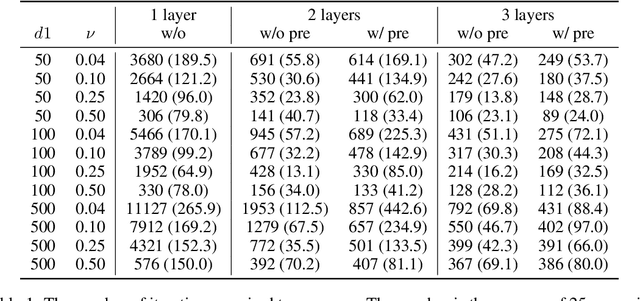
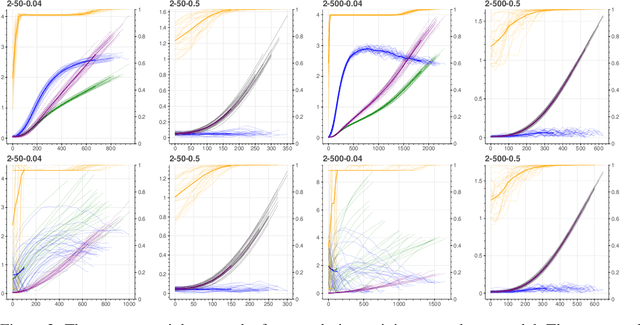
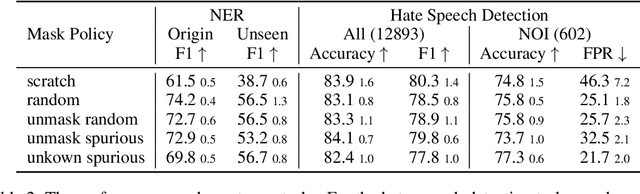
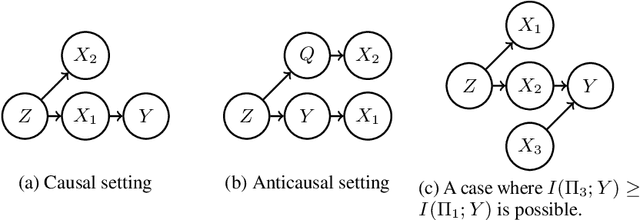
Despite the success of pretrained masked language models (MLM), why MLM pretraining is useful is still a qeustion not fully answered. In this work we theoretically and empirically show that MLM pretraining makes models robust to lexicon-level spurious features, partly answer the question. We theoretically show that, when we can model the distribution of a spurious feature $\Pi$ conditioned on the context, then (1) $\Pi$ is at least as informative as the spurious feature, and (2) learning from $\Pi$ is at least as simple as learning from the spurious feature. Therefore, MLM pretraining rescues the model from the simplicity bias caused by the spurious feature. We also explore the efficacy of MLM pretraing in causal settings. Finally we close the gap between our theories and the real world practices by conducting experiments on the hate speech detection and the name entity recognition tasks.