 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor decomposition for minimization of E2E SLU model toward on-device processing
Jun 02, 2023



Spoken Language Understanding (SLU) is a critical speech recognition application and is often deployed on edge devices. Consequently, on-device processing plays a significant role in the practical implementation of SLU. This paper focuses on the end-to-end (E2E) SLU model due to its small latency property, unlike a cascade system, and aims to minimize the computational cost. We reduce the model size by applying tensor decomposition to the Conformer and E-Branchformer architectures used in our E2E SLU models. We propose to apply singular value decomposition to linear layers and the Tucker decomposition to convolution layers, respectively. We also compare COMP/PARFAC decomposition and Tensor-Train decomposition to the Tucker decomposition. Since the E2E model is represented by a single neural network, our tensor decomposition can flexibly control the number of parameters without changing feature dimensions. On the STOP dataset, we achieved 70.9% exact match accuracy under the tight constraint of only 15 million parameters.
The Pipeline System of ASR and NLU with MLM-based Data Augmentation toward STOP Low-resource Challenge
May 11, 2023This paper describes our system for the low-resource domain adaptation track (Track 3) in Spoken Language Understanding Grand Challenge, which is a part of ICASSP Signal Processing Grand Challenge 2023. In the track, we adopt a pipeline approach of ASR and NLU. For ASR, we fine-tune Whisper for each domain with upsampling. For NLU, we fine-tune BART on all the Track3 data and then on low-resource domain data. We apply masked LM (MLM) -based data augmentation, where some of input tokens and corresponding target labels are replaced using MLM. We also apply a retrieval-based approach, where model input is augmented with similar training samples. As a result, we achieved exact match (EM) accuracy 63.3/75.0 (average: 69.15) for reminder/weather domain, and won the 1st place at the challenge.
A Study on the Integration of Pipeline and E2E SLU systems for Spoken Semantic Parsing toward STOP Quality Challenge
May 06, 2023


Recently there have been efforts to introduce new benchmark tasks for spoken language understanding (SLU), like semantic parsing. In this paper, we describe our proposed spoken semantic parsing system for the quality track (Track 1) in Spoken Language Understanding Grand Challenge which is part of ICASSP Signal Processing Grand Challenge 2023. We experiment with both end-to-end and pipeline systems for this task. Strong automatic speech recognition (ASR) models like Whisper and pretrained Language models (LM) like BART are utilized inside our SLU framework to boost performance. We also investigate the output level combination of various models to get an exact match accuracy of 80.8, which won the 1st place at the challenge.
Understanding the Effectiveness of Very Large Language Models on Dialog Evaluation
Jan 27, 2023



Language models have steadily increased in size over the past few years. They achieve a high level of performance on various natural language processing (NLP) tasks such as question answering and summarization. Large language models (LLMs) have been used for generation and can now output human-like text. Due to this, there are other downstream tasks in the realm of dialog that can now harness the LLMs' language understanding capabilities. Dialog evaluation is one task that this paper will explore. It concentrates on prompting with LLMs: BLOOM, OPT, GPT-3, Flan-T5, InstructDial and TNLGv2. The paper shows that the choice of datasets used for training a model contributes to how well it performs on a task as well as on how the prompt should be structured. Specifically, the more diverse and relevant the group of datasets that a model is trained on, the better dialog evaluation performs. This paper also investigates how the number of examples in the prompt and the type of example selection used affect the model's performance.
The DialPort tools
Aug 18, 2022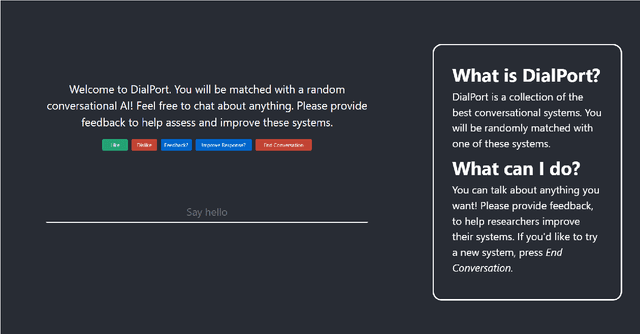
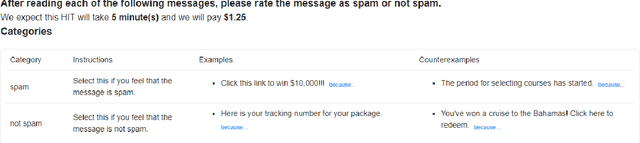
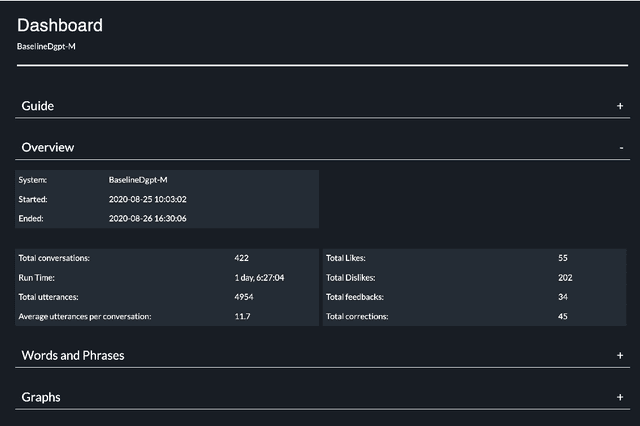
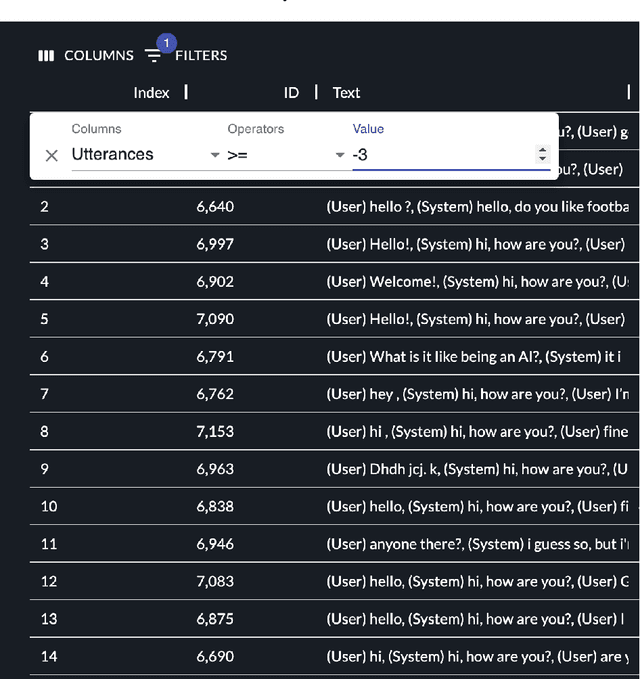
The DialPort project http://dialport.org/, funded by the National Science Foundation (NSF), covers a group of tools and services that aim at fulfilling the needs of the dialog research community. Over the course of six years, several offerings have been created, including the DialPort Portal and DialCrowd. This paper describes these contributions, which will be demoed at SIGDIAL, including implementation, prior studies, corresponding discoveries, and the locations at which the tools will remain freely available to the community going forward.
DialCrowd 2.0: A Quality-Focused Dialog System Crowdsourcing Toolkit
Jul 25, 2022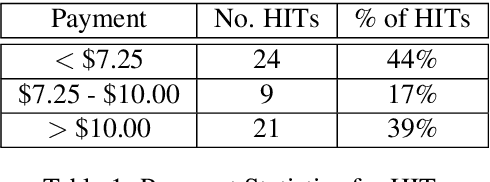
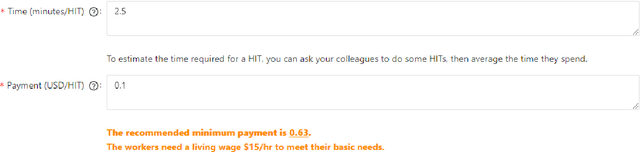
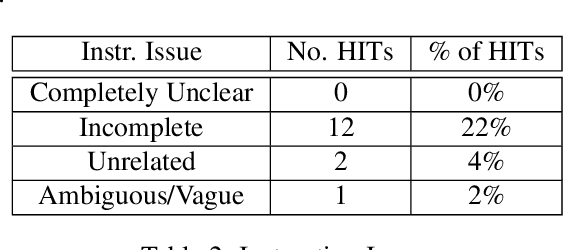
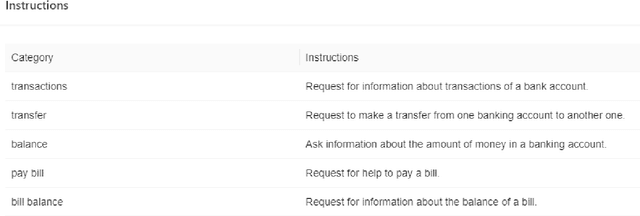
Dialog system developers need high-quality data to train, fine-tune and assess their systems. They often use crowdsourcing for this since it provides large quantities of data from many workers. However, the data may not be of sufficiently good quality. This can be due to the way that the requester presents a task and how they interact with the workers. This paper introduces DialCrowd 2.0 to help requesters obtain higher quality data by, for example, presenting tasks more clearly and facilitating effective communication with workers. DialCrowd 2.0 guides developers in creating improved Human Intelligence Tasks (HITs) and is directly applicable to the workflows used currently by developers and researchers.
A Survey of NLP-Related Crowdsourcing HITs: what works and what does not
Nov 09, 2021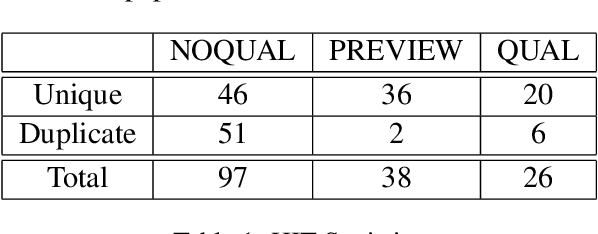
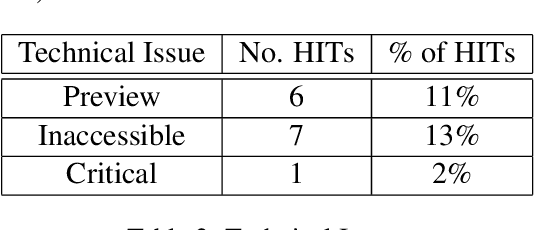

Crowdsourcing requesters on Amazon Mechanical Turk (AMT) have raised questions about the reliability of the workers. The AMT workforce is very diverse and it is not possible to make blanket assumptions about them as a group. Some requesters now reject work en mass when they do not get the results they expect. This has the effect of giving each worker (good or bad) a lower Human Intelligence Task (HIT) approval score, which is unfair to the good workers. It also has the effect of giving the requester a bad reputation on the workers' forums. Some of the issues causing the mass rejections stem from the requesters not taking the time to create a well-formed task with complete instructions and/or not paying a fair wage. To explore this assumption, this paper describes a study that looks at the crowdsourcing HITs on AMT that were available over a given span of time and records information about those HITs. This study also records information from a crowdsourcing forum on the worker perspective on both those HITs and on their corresponding requesters. Results reveal issues in worker payment and presentation issues such as missing instructions or HITs that are not doable.
SAPPHIRE: Approaches for Enhanced Concept-to-Text Generation
Aug 15, 2021

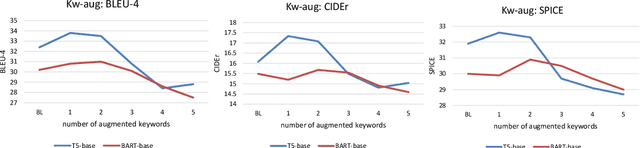
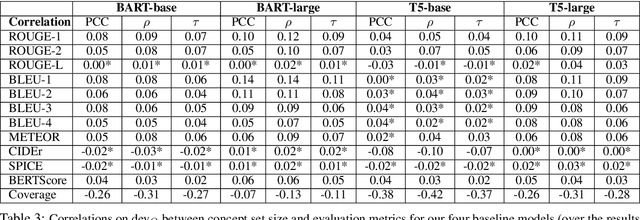
We motivate and propose a suite of simple but effective improvements for concept-to-text generation called SAPPHIRE: Set Augmentation and Post-hoc PHrase Infilling and REcombination. We demonstrate their effectiveness on generative commonsense reasoning, a.k.a. the CommonGen task, through experiments using both BART and T5 models. Through extensive automatic and human evaluation, we show that SAPPHIRE noticeably improves model performance. An in-depth qualitative analysis illustrates that SAPPHIRE effectively addresses many issues of the baseline model generations, including lack of commonsense, insufficient specificity, and poor fluency.
Multi-Modal Emotion Detection with Transfer Learning
Nov 13, 2020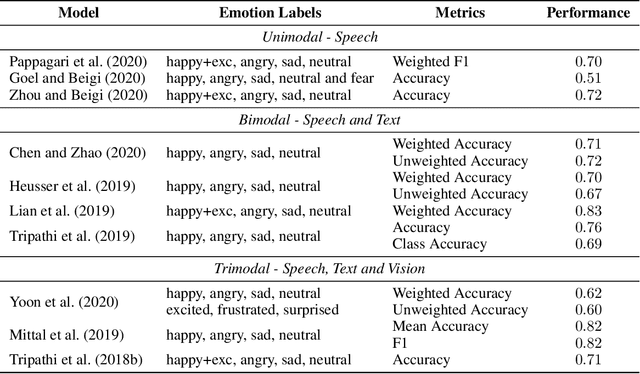
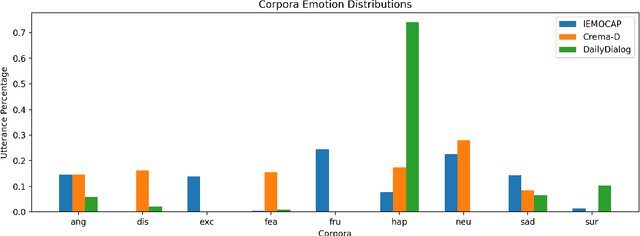

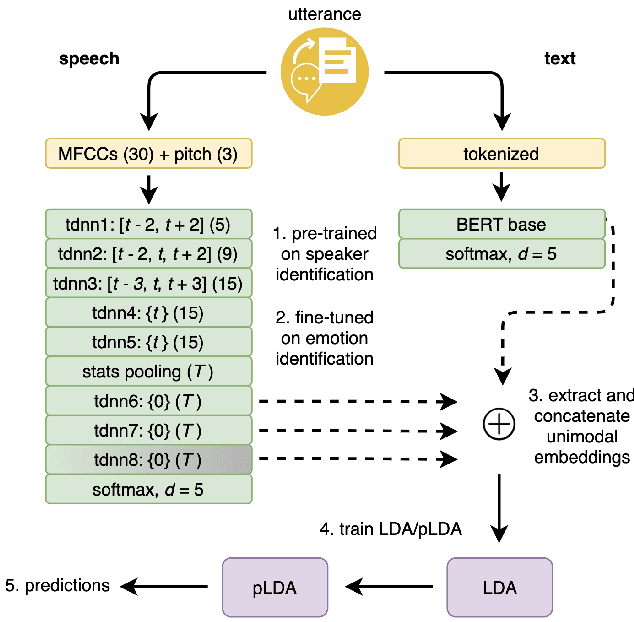
Automated emotion detection in speech is a challenging task due to the complex interdependence between words and the manner in which they are spoken. It is made more difficult by the available datasets; their small size and incompatible labeling idiosyncrasies make it hard to build generalizable emotion detection systems. To address these two challenges, we present a multi-modal approach that first transfers learning from related tasks in speech and text to produce robust neural embeddings and then uses these embeddings to train a pLDA classifier that is able to adapt to previously unseen emotions and domains. We begin by training a multilayer TDNN on the task of speaker identification with the VoxCeleb corpora and then fine-tune it on the task of emotion identification with the Crema-D corpus. Using this network, we extract speech embeddings for Crema-D from each of its layers, generate and concatenate text embeddings for the accompanying transcripts using a fine-tuned BERT model and then train an LDA - pLDA classifier on the resulting dense representations. We exhaustively evaluate the predictive power of every component: the TDNN alone, speech embeddings from each of its layers alone, text embeddings alone and every combination thereof. Our best variant, trained on only VoxCeleb and Crema-D and evaluated on IEMOCAP, achieves an EER of 38.05%. Including a portion of IEMOCAP during training produces a 5-fold averaged EER of 25.72% (For comparison, 44.71% of the gold-label annotations include at least one annotator who disagrees).