 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of NLP-Related Crowdsourcing HITs: what works and what does not
Paper and Code
Nov 09, 2021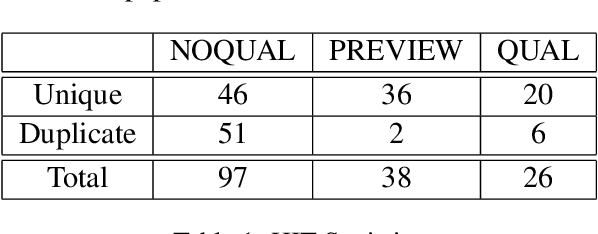
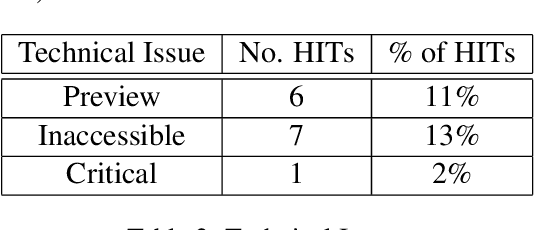

Crowdsourcing requesters on Amazon Mechanical Turk (AMT) have raised questions about the reliability of the workers. The AMT workforce is very diverse and it is not possible to make blanket assumptions about them as a group. Some requesters now reject work en mass when they do not get the results they expect. This has the effect of giving each worker (good or bad) a lower Human Intelligence Task (HIT) approval score, which is unfair to the good workers. It also has the effect of giving the requester a bad reputation on the workers' forums. Some of the issues causing the mass rejections stem from the requesters not taking the time to create a well-formed task with complete instructions and/or not paying a fair wage. To explore this assumption, this paper describes a study that looks at the crowdsourcing HITs on AMT that were available over a given span of time and records information about those HITs. This study also records information from a crowdsourcing forum on the worker perspective on both those HITs and on their corresponding requesters. Results reveal issues in worker payment and presentation issues such as missing instructions or HITs that are not doable.