 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Conversational Quality in Spoken Dialogue Systems with Reinforcement Learning from AI Feedback
Jan 27, 2026Reinforcement learning from human or AI feedback (RLHF/RLAIF) for speech-in/speech-out dialogue systems (SDS) remains underexplored, with prior work largely limited to single semantic rewards applied at the utterance level. Such setups overlook the multi-dimensional and multi-modal nature of conversational quality, which encompasses semantic coherence, audio naturalness, speaker consistency, emotion alignment, and turn-taking behavior. Moreover, they are fundamentally mismatched with duplex spoken dialogue systems that generate responses incrementally, where agents must make decisions based on partial utterances. We address these limitations with the first multi-reward RLAIF framework for SDS, combining semantic, audio-quality, and emotion-consistency rewards. To align utterance-level preferences with incremental, blockwise decoding in duplex models, we apply turn-level preference sampling and aggregate per-block log-probabilities within a single DPO objective. We present the first systematic study of preference learning for improving SDS quality in both multi-turn Chain-of-Thought and blockwise duplex models, and release a multi-reward DPO dataset to support reproducible research. Experiments show that single-reward RLAIF selectively improves its targeted metric, while joint multi-reward training yields consistent gains across semantic quality and audio naturalness. These results highlight the importance of holistic, multi-reward alignment for practical conversational SDS.
Chain-of-Thought Reasoning in Streaming Full-Duplex End-to-End Spoken Dialogue Systems
Oct 02, 2025Most end-to-end (E2E) spoken dialogue systems (SDS) rely on voice activity detection (VAD) for turn-taking, but VAD fails to distinguish between pauses and turn completions. Duplex SDS models address this by predicting output continuously, including silence tokens, thus removing the need for explicit VAD. However, they often have complex dual-channel architecture and lag behind cascaded models in semantic reasoning. To overcome these challenges, we propose SCoT: a Streaming Chain-of-Thought (CoT) framework for Duplex SDS, alternating between processing fixed-duration user input and generating responses in a blockwise manner. Using frame-level alignments, we create intermediate targets-aligned user transcripts and system responses for each block. Experiments show that our approach produces more coherent and interpretable responses than existing duplex methods while supporting lower-latency and overlapping interactions compared to turn-by-turn systems.
Scheduled Interleaved Speech-Text Training for Speech-to-Speech Translation with LLMs
Jun 12, 2025Speech-to-speech translation (S2ST) has been advanced with large language models (LLMs), which are fine-tuned on discrete speech units. In such approaches, modality adaptation from text to speech has been an issue. LLMs are trained on text-only data, which presents challenges to adapt them to speech modality with limited speech-to-speech data. To address the training difficulty, we propose scheduled interleaved speech--text training in this study. We use interleaved speech--text units instead of speech units during training, where aligned text tokens are interleaved at the word level. We gradually decrease the ratio of text as training progresses, to facilitate progressive modality adaptation from text to speech. We conduct experimental evaluations by fine-tuning LLaMA3.2-1B for S2ST on the CVSS dataset. We show that the proposed method consistently improves the translation performances, especially for languages with limited training data.
Differentiable K-means for Fully-optimized Discrete Token-based ASR
May 22, 2025Recent studies have highlighted the potential of discrete tokens derived from self-supervised learning (SSL) models for various speech-related tasks. These tokens serve not only as substitutes for text in language modeling but also as intermediate representations for tasks such as automatic speech recognition (ASR). However, discrete tokens are typically obtained via k-means clustering of SSL features independently of downstream tasks, making them suboptimal for specific applications. This paper proposes the use of differentiable k-means, enabling the joint optimization of tokenization and downstream tasks. This approach enables the fine-tuning of the SSL parameters and learning weights for outputs from multiple SSL layers. Experiments were conducted with ASR as a downstream task. ASR accuracy successfully improved owing to the optimized tokens. The acquired tokens also exhibited greater purity of phonetic information, which were found to be useful even in speech resynthesis.
ESPnet-SDS: Unified Toolkit and Demo for Spoken Dialogue Systems
Mar 11, 2025



Advancements in audio foundation models (FMs) have fueled interest in end-to-end (E2E) spoken dialogue systems, but different web interfaces for each system makes it challenging to compare and contrast them effectively. Motivated by this, we introduce an open-source, user-friendly toolkit designed to build unified web interfaces for various cascaded and E2E spoken dialogue systems. Our demo further provides users with the option to get on-the-fly automated evaluation metrics such as (1) latency, (2) ability to understand user input, (3) coherence, diversity, and relevance of system response, and (4) intelligibility and audio quality of system output. Using the evaluation metrics, we compare various cascaded and E2E spoken dialogue systems with a human-human conversation dataset as a proxy. Our analysis demonstrates that the toolkit allows researchers to effortlessly compare and contrast different technologies, providing valuable insights such as current E2E systems having poorer audio quality and less diverse responses. An example demo produced using our toolkit is publicly available here: https://huggingface.co/spaces/Siddhant/Voice_Assistant_Demo.
Task Arithmetic for Language Expansion in Speech Translation
Sep 17, 2024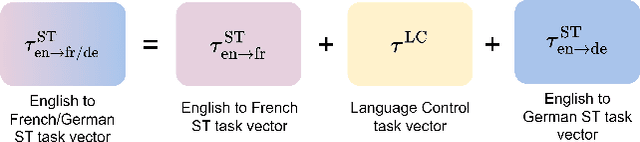
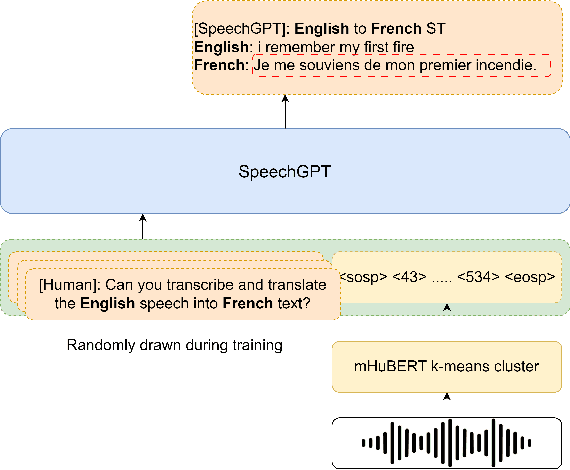


Recent advances in large language models (LLMs) have gained interest in speech-text multimodal foundation models, achieving strong performance on instruction-based speech translation (ST). However, expanding language pairs from an existing instruction-tuned ST system is costly due to the necessity of re-training on a combination of new and previous datasets. We propose to expand new language pairs by merging the model trained on new language pairs and the existing model, using task arithmetic. We find that the direct application of task arithmetic for ST causes the merged model to fail to follow instructions; thus, generating translation in incorrect languages. To eliminate language confusion, we propose an augmented task arithmetic method that merges an additional language control model. It is trained to generate the correct target language token following the instructions. Our experiments demonstrate that our proposed language control model can achieve language expansion by eliminating language confusion. In our MuST-C and CoVoST-2 experiments, it shows up to 4.66 and 4.92 BLEU scores improvement, respectively. In addition, we demonstrate the use of our task arithmetic framework can expand to a language pair where neither paired ST training data nor a pre-trained ST model is available. We first synthesize the ST system from machine translation (MT) systems via task analogy, then merge the synthesized ST system to the existing ST model.
Decoder-only Architecture for Streaming End-to-end Speech Recognition
Jun 23, 2024


Decoder-only language models (LMs) have been successfully adopted for speech-processing tasks including automatic speech recognition (ASR). The LMs have ample expressiveness and perform efficiently. This efficiency is a suitable characteristic for streaming applications of ASR. In this work, we propose to use a decoder-only architecture for blockwise streaming ASR. In our approach, speech features are compressed using CTC output and context embedding using blockwise speech subnetwork, and are sequentially provided as prompts to the decoder. The decoder estimates the output tokens promptly at each block. To this end, we also propose a novel training scheme using random-length prefix prompts to make the model robust to the truncated prompts caused by blockwise processing. An experimental comparison shows that our proposed decoder-only streaming ASR achieves 8% relative word error rate reduction in the LibriSpeech test-other set while being twice as fast as the baseline model.
Rapid Language Adaptation for Multilingual E2E Speech Recognition Using Encoder Prompting
Jun 18, 2024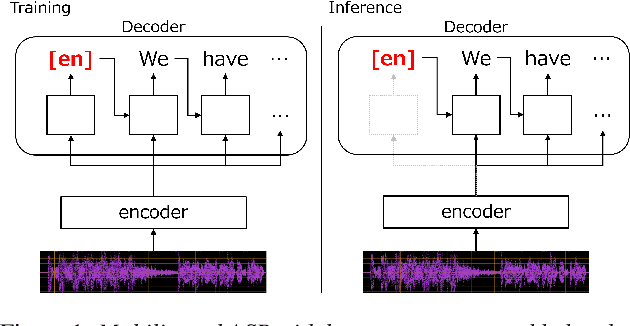
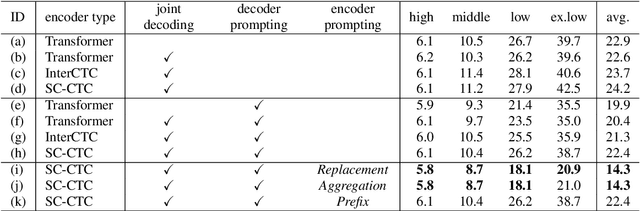
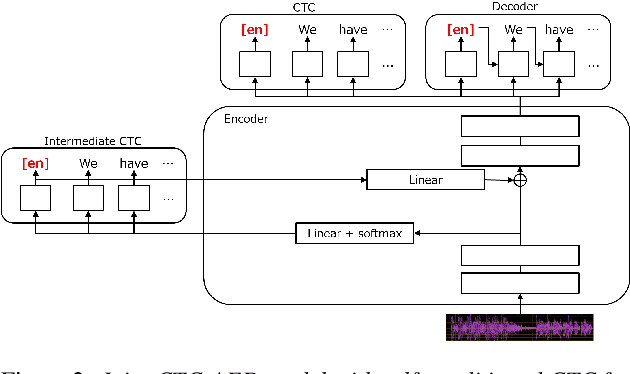
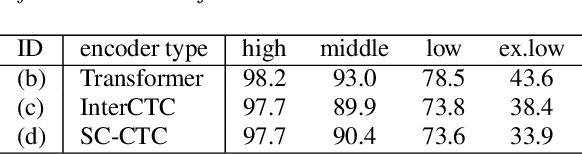
End-to-end multilingual speech recognition models handle multiple languages through a single model, often incorporating language identification to automatically detect the language of incoming speech. Since the common scenario is where the language is already known, these models can perform as language-specific by using language information as prompts, which is particularly beneficial for attention-based encoder-decoder architectures. However, the Connectionist Temporal Classification (CTC) approach, which enhances recognition via joint decoding and multi-task training, does not normally incorporate language prompts due to its conditionally independent output tokens. To overcome this, we introduce an encoder prompting technique within the self-conditioned CTC framework, enabling language-specific adaptation of the CTC model in a zero-shot manner. Our method has shown to significantly reduce errors by 28% on average and by 41% on low-resource languages.
Finding Task-specific Subnetworks in Multi-task Spoken Language Understanding Model
Jun 18, 2024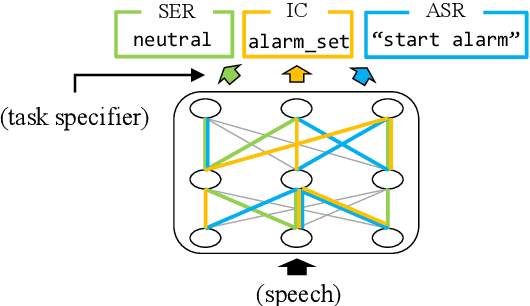
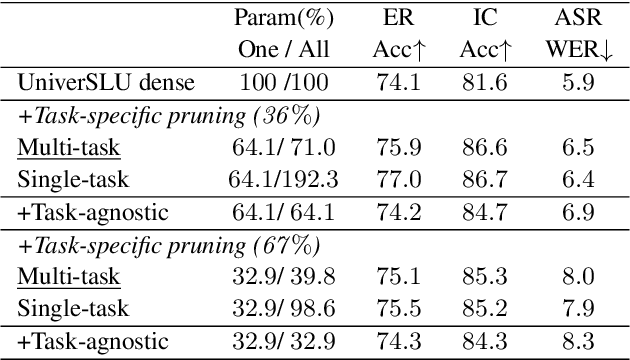
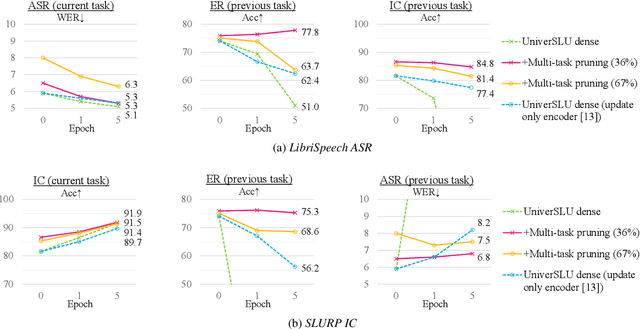

Recently, multi-task spoken language understanding (SLU) models have emerged, designed to address various speech processing tasks. However, these models often rely on a large number of parameters. Also, they often encounter difficulties in adapting to new data for a specific task without experiencing catastrophic forgetting of previously trained tasks. In this study, we propose finding task-specific subnetworks within a multi-task SLU model via neural network pruning. In addition to model compression, we expect that the forgetting of previously trained tasks can be mitigated by updating only a task-specific subnetwork. We conduct experiments on top of the state-of-the-art multi-task SLU model ``UniverSLU'', trained for several tasks such as emotion recognition (ER), intent classification (IC), and automatic speech recognition (ASR). We show that pruned models were successful in adapting to additional ASR or IC data with minimal performance degradation on previously trained tasks.
Phoneme-aware Encoding for Prefix-tree-based Contextual ASR
Dec 15, 2023In speech recognition applications, it is important to recognize context-specific rare words, such as proper nouns. Tree-constrained Pointer Generator (TCPGen) has shown promise for this purpose, which efficiently biases such words with a prefix tree. While the original TCPGen relies on grapheme-based encoding, we propose extending it with phoneme-aware encoding to better recognize words of unusual pronunciations. As TCPGen handles biasing words as subword units, we propose obtaining subword-level phoneme-aware encoding by using alignment between phonemes and subwords. Furthermore, we propose injecting phoneme-level predictions from CTC into queries of TCPGen so that the model better interprets the phoneme-aware encodings. We conducted ASR experiments with TCPGen for RNN transducer. We observed that proposed phoneme-aware encoding outperformed ordinary grapheme-based encoding on both the English LibriSpeech and Japanese CSJ datasets, demonstrating the robustness of our approach across linguistically diverse languages.