 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Arithmetic for Language Expansion in Speech Translation
Sep 17, 2024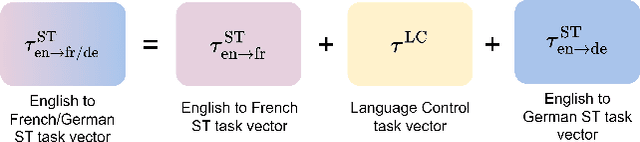
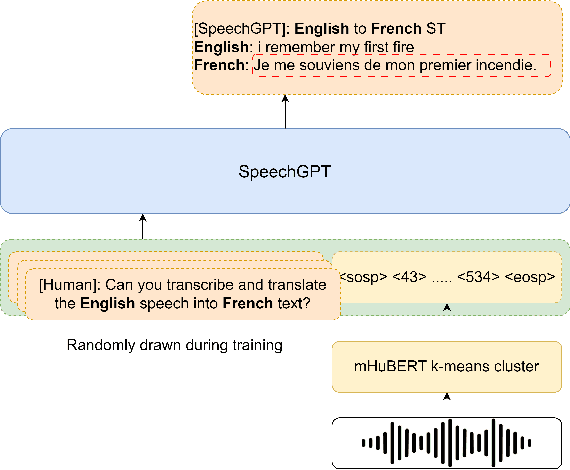


Recent advances in large language models (LLMs) have gained interest in speech-text multimodal foundation models, achieving strong performance on instruction-based speech translation (ST). However, expanding language pairs from an existing instruction-tuned ST system is costly due to the necessity of re-training on a combination of new and previous datasets. We propose to expand new language pairs by merging the model trained on new language pairs and the existing model, using task arithmetic. We find that the direct application of task arithmetic for ST causes the merged model to fail to follow instructions; thus, generating translation in incorrect languages. To eliminate language confusion, we propose an augmented task arithmetic method that merges an additional language control model. It is trained to generate the correct target language token following the instructions. Our experiments demonstrate that our proposed language control model can achieve language expansion by eliminating language confusion. In our MuST-C and CoVoST-2 experiments, it shows up to 4.66 and 4.92 BLEU scores improvement, respectively. In addition, we demonstrate the use of our task arithmetic framework can expand to a language pair where neither paired ST training data nor a pre-trained ST model is available. We first synthesize the ST system from machine translation (MT) systems via task analogy, then merge the synthesized ST system to the existing ST model.