 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Recipe for Universal Phone Recognition
Mar 30, 2026Phone recognition (PR) is a key enabler of multilingual and low-resource speech processing tasks, yet robust performance remains elusive. Highly performant English-focused models do not generalize across languages, while multilingual models underutilize pretrained representations. It also remains unclear how data scale, architecture, and training objective contribute to multilingual PR. We present PhoneticXEUS -- trained on large-scale multilingual data and achieving state-of-the-art performance on both multilingual (17.7% PFER) and accented English speech (10.6% PFER). Through controlled ablations with evaluations across 100+ languages under a unified scheme, we empirically establish our training recipe and quantify the impact of SSL representations, data scale, and loss objectives. In addition, we analyze error patterns across language families, accented speech, and articulatory features. All data and code are released openly.
The CMU-AIST submission for the ICME 2025 Audio Encoder Challenge
Jan 22, 2026This technical report describes our submission to the ICME 2025 audio encoder challenge. Our submitted system is built on BEATs, a masked speech token prediction based audio encoder. We extend the BEATs model using 74,000 hours of data derived from various speech, music, and sound corpora and scale its architecture upto 300 million parameters. We experiment with speech-heavy and balanced pre-training mixtures to study the impact of different domains on final performance. Our submitted system consists of an ensemble of the Dasheng 1.2 billion model with two custom scaled-up BEATs models trained on the aforementioned pre-training data mixtures. We also propose a simple ensembling technique that retains the best capabilities of constituent models and surpasses both the baseline and Dasheng 1.2B. For open science, we publicly release our trained checkpoints via huggingface at https://huggingface.co/shikhar7ssu/OpenBEATs-ICME-SOUND and https://huggingface.co/shikhar7ssu/OpenBEATs-ICME.
PRiSM: Benchmarking Phone Realization in Speech Models
Jan 20, 2026Phone recognition (PR) serves as the atomic interface for language-agnostic modeling for cross-lingual speech processing and phonetic analysis. Despite prolonged efforts in developing PR systems, current evaluations only measure surface-level transcription accuracy. We introduce PRiSM, the first open-source benchmark designed to expose blind spots in phonetic perception through intrinsic and extrinsic evaluation of PR systems. PRiSM standardizes transcription-based evaluation and assesses downstream utility in clinical, educational, and multilingual settings with transcription and representation probes. We find that diverse language exposure during training is key to PR performance, encoder-CTC models are the most stable, and specialized PR models still outperform Large Audio Language Models. PRiSM releases code, recipes, and datasets to move the field toward multilingual speech models with robust phonetic ability: https://github.com/changelinglab/prism.
OpenBEATs: A Fully Open-Source General-Purpose Audio Encoder
Jul 18, 2025



Masked token prediction has emerged as a powerful pre-training objective across language, vision, and speech, offering the potential to unify these diverse modalities through a single pre-training task. However, its application for general audio understanding remains underexplored, with BEATs being the only notable example. BEATs has seen limited modifications due to the absence of open-source pre-training code. Furthermore, BEATs was trained only on AudioSet, restricting its broader downstream applicability. To address these gaps, we present OpenBEATs, an open-source framework that extends BEATs via multi-domain audio pre-training. We conduct comprehensive evaluations across six types of tasks, twenty five datasets, and three audio domains, including audio reasoning tasks such as audio question answering, entailment, and captioning. OpenBEATs achieves state-of-the-art performance on six bioacoustics datasets, two environmental sound datasets and five reasoning datasets, performing better than models exceeding a billion parameters at one-fourth their parameter size. These results demonstrate the effectiveness of multi-domain datasets and masked token prediction task to learn general-purpose audio representations. To promote further research and reproducibility, we release all pre-training and evaluation code, pretrained and fine-tuned checkpoints, and training logs at https://shikhar-s.github.io/OpenBEATs
Context-Driven Dynamic Pruning for Large Speech Foundation Models
May 24, 2025



Speech foundation models achieve strong generalization across languages and acoustic conditions, but require significant computational resources for inference. In the context of speech foundation models, pruning techniques have been studied that dynamically optimize model structures based on the target audio leveraging external context. In this work, we extend this line of research and propose context-driven dynamic pruning, a technique that optimizes the model computation depending on the context between different input frames and additional context during inference. We employ the Open Whisper-style Speech Model (OWSM) and incorporate speaker embeddings, acoustic event embeddings, and language information as additional context. By incorporating the speaker embedding, our method achieves a reduction of 56.7 GFLOPs while improving BLEU scores by a relative 25.7% compared to the fully fine-tuned OWSM model.
ESPnet-SDS: Unified Toolkit and Demo for Spoken Dialogue Systems
Mar 11, 2025



Advancements in audio foundation models (FMs) have fueled interest in end-to-end (E2E) spoken dialogue systems, but different web interfaces for each system makes it challenging to compare and contrast them effectively. Motivated by this, we introduce an open-source, user-friendly toolkit designed to build unified web interfaces for various cascaded and E2E spoken dialogue systems. Our demo further provides users with the option to get on-the-fly automated evaluation metrics such as (1) latency, (2) ability to understand user input, (3) coherence, diversity, and relevance of system response, and (4) intelligibility and audio quality of system output. Using the evaluation metrics, we compare various cascaded and E2E spoken dialogue systems with a human-human conversation dataset as a proxy. Our analysis demonstrates that the toolkit allows researchers to effortlessly compare and contrast different technologies, providing valuable insights such as current E2E systems having poorer audio quality and less diverse responses. An example demo produced using our toolkit is publicly available here: https://huggingface.co/spaces/Siddhant/Voice_Assistant_Demo.
ESPnet-SpeechLM: An Open Speech Language Model Toolkit
Feb 21, 2025



We present ESPnet-SpeechLM, an open toolkit designed to democratize the development of speech language models (SpeechLMs) and voice-driven agentic applications. The toolkit standardizes speech processing tasks by framing them as universal sequential modeling problems, encompassing a cohesive workflow of data preprocessing, pre-training, inference, and task evaluation. With ESPnet-SpeechLM, users can easily define task templates and configure key settings, enabling seamless and streamlined SpeechLM development. The toolkit ensures flexibility, efficiency, and scalability by offering highly configurable modules for every stage of the workflow. To illustrate its capabilities, we provide multiple use cases demonstrating how competitive SpeechLMs can be constructed with ESPnet-SpeechLM, including a 1.7B-parameter model pre-trained on both text and speech tasks, across diverse benchmarks. The toolkit and its recipes are fully transparent and reproducible at: https://github.com/espnet/espnet/tree/speechlm.
STAB: Speech Tokenizer Assessment Benchmark
Sep 04, 2024
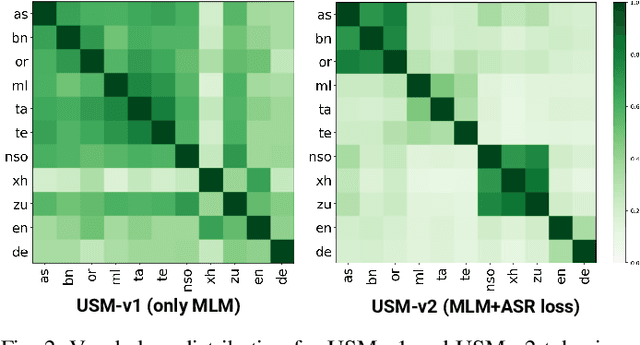
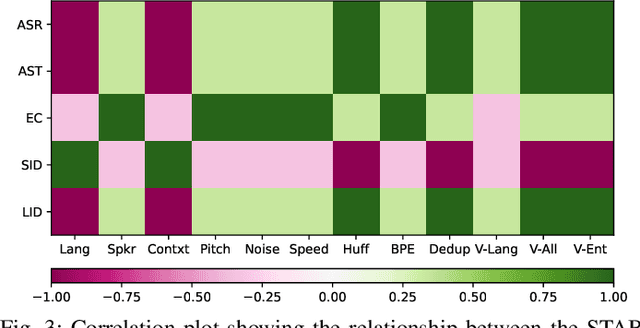
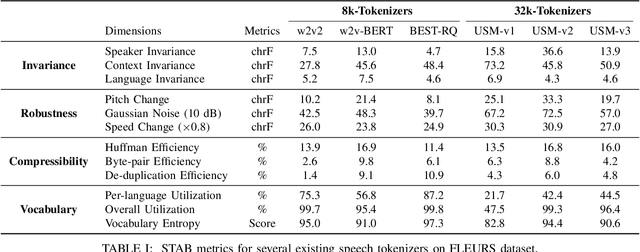
Representing speech as discrete tokens provides a framework for transforming speech into a format that closely resembles text, thus enabling the use of speech as an input to the widely successful large language models (LLMs). Currently, while several speech tokenizers have been proposed, there is ambiguity regarding the properties that are desired from a tokenizer for specific downstream tasks and its overall generalizability. Evaluating the performance of tokenizers across different downstream tasks is a computationally intensive effort that poses challenges for scalability. To circumvent this requirement, we present STAB (Speech Tokenizer Assessment Benchmark), a systematic evaluation framework designed to assess speech tokenizers comprehensively and shed light on their inherent characteristics. This framework provides a deeper understanding of the underlying mechanisms of speech tokenization, thereby offering a valuable resource for expediting the advancement of future tokenizer models and enabling comparative analysis using a standardized benchmark. We evaluate the STAB metrics and correlate this with downstream task performance across a range of speech tasks and tokenizer choices.
IndicGenBench: A Multilingual Benchmark to Evaluate Generation Capabilities of LLMs on Indic Languages
Apr 25, 2024As large language models (LLMs) see increasing adoption across the globe, it is imperative for LLMs to be representative of the linguistic diversity of the world. India is a linguistically diverse country of 1.4 Billion people. To facilitate research on multilingual LLM evaluation, we release IndicGenBench - the largest benchmark for evaluating LLMs on user-facing generation tasks across a diverse set 29 of Indic languages covering 13 scripts and 4 language families. IndicGenBench is composed of diverse generation tasks like cross-lingual summarization, machine translation, and cross-lingual question answering. IndicGenBench extends existing benchmarks to many Indic languages through human curation providing multi-way parallel evaluation data for many under-represented Indic languages for the first time. We evaluate a wide range of proprietary and open-source LLMs including GPT-3.5, GPT-4, PaLM-2, mT5, Gemma, BLOOM and LLaMA on IndicGenBench in a variety of settings. The largest PaLM-2 models performs the best on most tasks, however, there is a significant performance gap in all languages compared to English showing that further research is needed for the development of more inclusive multilingual language models. IndicGenBench is released at www.github.com/google-research-datasets/indic-gen-bench
Multimodal Modeling For Spoken Language Identification
Sep 19, 2023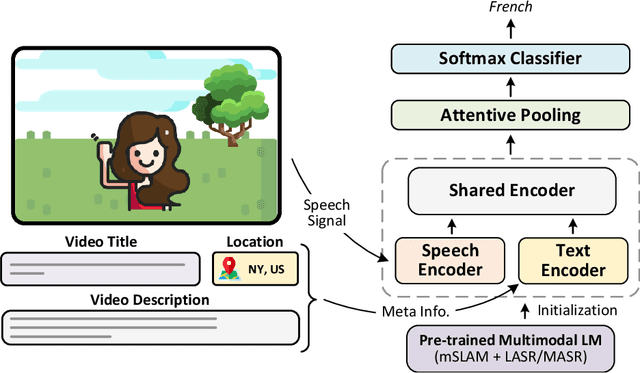
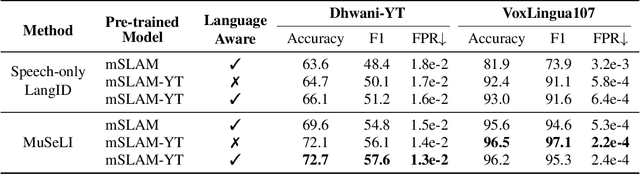
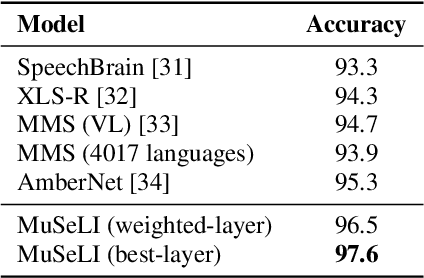
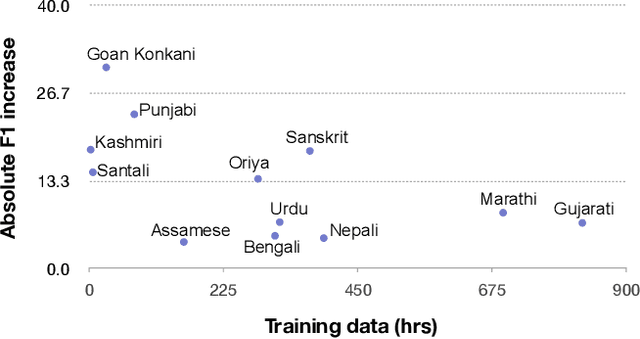
Spoken language identification refers to the task of automatically predicting the spoken language in a given utterance. Conventionally, it is modeled as a speech-based language identification task. Prior techniques have been constrained to a single modality; however in the case of video data there is a wealth of other metadata that may be beneficial for this task. In this work, we propose MuSeLI, a Multimodal Spoken Language Identification method, which delves into the use of various metadata sources to enhance language identification. Our study reveals that metadata such as video title, description and geographic location provide substantial information to identify the spoken language of the multimedia recording. We conduct experiments using two diverse public datasets of YouTube videos, and obtain state-of-the-art results on the language identification task. We additionally conduct an ablation study that describes the distinct contribution of each modality for language recognition.