 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Language Adaptation for Multilingual E2E Speech Recognition Using Encoder Prompting
Paper and Code
Jun 18, 2024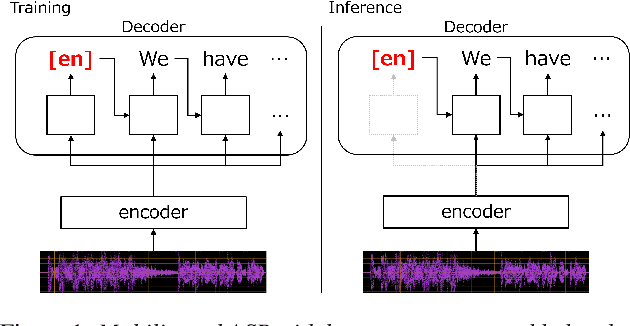
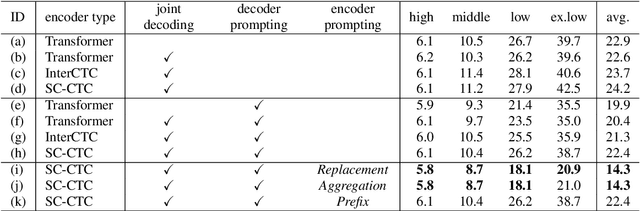
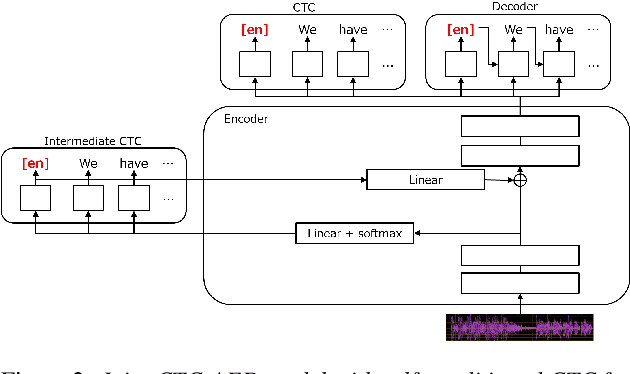
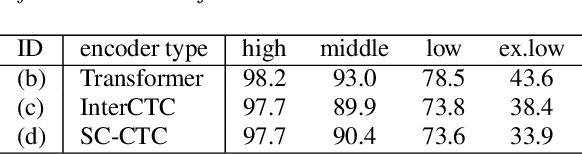
End-to-end multilingual speech recognition models handle multiple languages through a single model, often incorporating language identification to automatically detect the language of incoming speech. Since the common scenario is where the language is already known, these models can perform as language-specific by using language information as prompts, which is particularly beneficial for attention-based encoder-decoder architectures. However, the Connectionist Temporal Classification (CTC) approach, which enhances recognition via joint decoding and multi-task training, does not normally incorporate language prompts due to its conditionally independent output tokens. To overcome this, we introduce an encoder prompting technique within the self-conditioned CTC framework, enabling language-specific adaptation of the CTC model in a zero-shot manner. Our method has shown to significantly reduce errors by 28% on average and by 41% on low-resource languages.