 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelating Neural Text Degeneration to Exposure Bias
Paper and Code

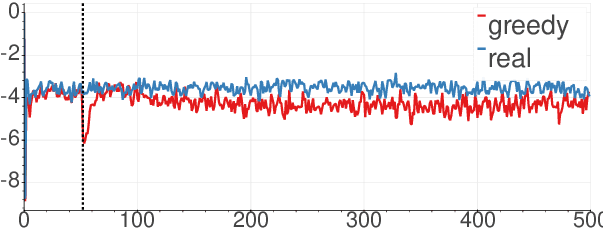
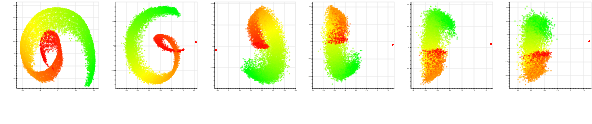
This work focuses on relating two mysteries in neural-based text generation: exposure bias, and text degeneration. Despite the long time since exposure bias was mentioned and the numerous studies for its remedy, to our knowledge, its impact on text generation has not yet been verified. Text degeneration is a problem that the widely-used pre-trained language model GPT-2 was recently found to suffer from (Holtzman et al., 2020). Motivated by the unknown causation of the text degeneration, in this paper we attempt to relate these two mysteries. Specifically, we first qualitatively quantitatively identify mistakes made before text degeneration occurs. Then we investigate the significance of the mistakes by inspecting the hidden states in GPT-2. Our results show that text degeneration is likely to be partly caused by exposure bias. We also study the self-reinforcing mechanism of text degeneration, explaining why the mistakes amplify. In sum, our study provides a more concrete foundation for further investigation on exposure bias and text degeneration problems.