 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Approximation Can Strictly Outperform Superpositional Approximation
Jun 07, 2026Many classically studied function classes are known to be approximated optimally by superpositional methods, i.e. with approximants constructed as the linear combination of elements in some dictionary. Here optimality means that the uniform approximation error viewed as a function of the number of parameters used has polynomial decay of the highest order achievable by any parametrized method whose parameters can be encoded as a bit string of length proportional, up to logarithmic factors, to the number of parameters. While compositional methods like neural networks are structurally different, their approximation rates can be made comparable by imposing constraints that ensure such a proportional bit string encoding. In this work we study function classes exhibiting structural properties that limit superpositional approximation rates to be strictly lower than compositional approximation rates. In particular, we construct explicit examples for which there is an arbitrarily large gap.
Adaptivity Under Realizability Constraints: Comparing In-Context and Agentic Learning
May 06, 2026We compare in-context learning with fixed queries and agentic learning with adaptive queries for uniform approximation of task families. We consider two settings: an unrestricted regime, where querying and approximation are arbitrary functions, and a realizable regime, where we require these operations to be implemented by ReLU neural networks. In both settings, adaptivity never hinders approximation performance. However, this advantage can change when one passes from the unrestricted regime to the realizable regime. We identify four distinct approximation scenarios, each witnessed by an explicit task family: (a) no advantage of adaptivity; (b) an advantage in the unrestricted regime that persists under ReLU realizability; (c) an advantage that arises only under realizability; and (d) an advantage that disappears under realizability. This demonstrates that representational constraints interact profoundly with the effect of adaptivity.
LAMP: Look-Ahead Mixed-Precision Inference of Large Language Models
Jan 29, 2026Mixed-precision computations are a hallmark of the current stage of AI, driving the progress in large language models towards efficient, locally deployable solutions. This article addresses the floating-point computation of compositionally-rich functions, concentrating on transformer inference. Based on the rounding error analysis of a composition $f(g(\mathrm{x}))$, we provide an adaptive strategy that selects a small subset of components of $g(\mathrm{x})$ to be computed more accurately while all other computations can be carried out with lower accuracy. We then explain how this strategy can be applied to different compositions within a transformer and illustrate its overall effect on transformer inference. We study the effectiveness of this algorithm numerically on GPT-2 models and demonstrate that already very low recomputation rates allow for improvements of up to two orders of magnitude in accuracy.
Minimax learning rates for estimating binary classifiers under margin conditions
May 15, 2025
We study classification problems using binary estimators where the decision boundary is described by horizon functions and where the data distribution satisfies a geometric margin condition. We establish upper and lower bounds for the minimax learning rate over broad function classes with bounded Kolmogorov entropy in Lebesgue norms. A key novelty of our work is the derivation of lower bounds on the worst-case learning rates under a geometric margin condition -- a setting that is almost universally satisfied in practice but remains theoretically challenging. Moreover, our results deal with the noiseless setting, where lower bounds are particularly hard to establish. We apply our general results to classification problems with decision boundaries belonging to several function classes: for Barron-regular functions, and for H\"older-continuous functions with strong margins, we identify optimal rates close to the fast learning rates of $\mathcal{O}(n^{-1})$ for $n \in \mathbb{N}$ samples. Also for merely convex decision boundaries, in a strong margin case optimal rates near $\mathcal{O}(n^{-1/2})$ can be achieved.
Numerical Error Analysis of Large Language Models
Mar 13, 2025Large language models based on transformer architectures have become integral to state-of-the-art natural language processing applications. However, their training remains computationally expensive and exhibits instabilities, some of which are expected to be caused by finite-precision computations. We provide a theoretical analysis of the impact of round-off errors within the forward pass of a transformer architecture which yields fundamental bounds for these effects. In addition, we conduct a series of numerical experiments which demonstrate the practical relevance of our bounds. Our results yield concrete guidelines for choosing hyperparameters that mitigate round-off errors, leading to more robust and stable inference.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
High-dimensional classification problems with Barron regular boundaries under margin conditions
Dec 10, 2024We prove that a classifier with a Barron-regular decision boundary can be approximated with a rate of high polynomial degree by ReLU neural networks with three hidden layers when a margin condition is assumed. In particular, for strong margin conditions, high-dimensional discontinuous classifiers can be approximated with a rate that is typically only achievable when approximating a low-dimensional smooth function. We demonstrate how these expression rate bounds imply fast-rate learning bounds that are close to $n^{-1}$ where $n$ is the number of samples. In addition, we carry out comprehensive numerical experimentation on binary classification problems with various margins. We study three different dimensions, with the highest dimensional problem corresponding to images from the MNIST data set.
The sampling complexity of learning invertible residual neural networks
Nov 08, 2024In recent work it has been shown that determining a feedforward ReLU neural network to within high uniform accuracy from point samples suffers from the curse of dimensionality in terms of the number of samples needed. As a consequence, feedforward ReLU neural networks are of limited use for applications where guaranteed high uniform accuracy is required. We consider the question of whether the sampling complexity can be improved by restricting the specific neural network architecture. To this end, we investigate invertible residual neural networks which are foundational architectures in deep learning and are widely employed in models that power modern generative methods. Our main result shows that the residual neural network architecture and invertibility do not help overcome the complexity barriers encountered with simpler feedforward architectures. Specifically, we demonstrate that the computational complexity of approximating invertible residual neural networks from point samples in the uniform norm suffers from the curse of dimensionality. Similar results are established for invertible convolutional Residual neural networks.
Dimension-independent learning rates for high-dimensional classification problems
Sep 26, 2024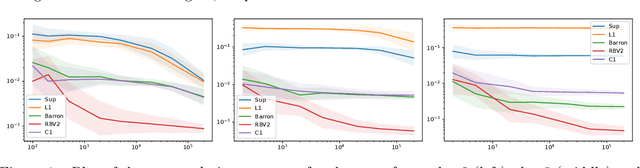
We study the problem of approximating and estimating classification functions that have their decision boundary in the $RBV^2$ space. Functions of $RBV^2$ type arise naturally as solutions of regularized neural network learning problems and neural networks can approximate these functions without the curse of dimensionality. We modify existing results to show that every $RBV^2$ function can be approximated by a neural network with bounded weights. Thereafter, we prove the existence of a neural network with bounded weights approximating a classification function. And we leverage these bounds to quantify the estimation rates. Finally, we present a numerical study that analyzes the effect of different regularity conditions on the decision boundaries.
Mathematical theory of deep learning
Jul 25, 2024
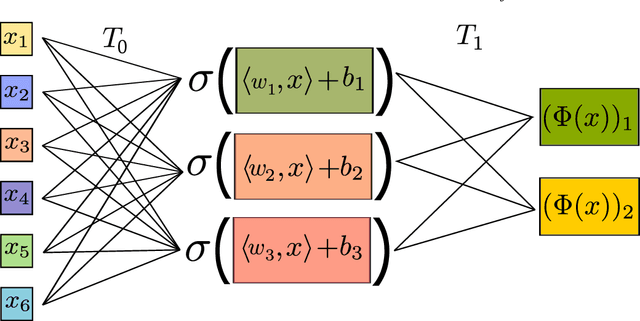
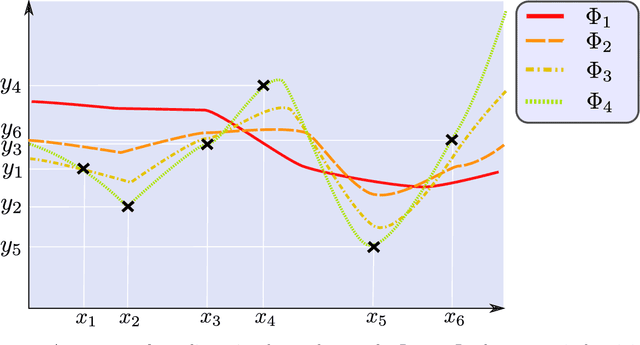
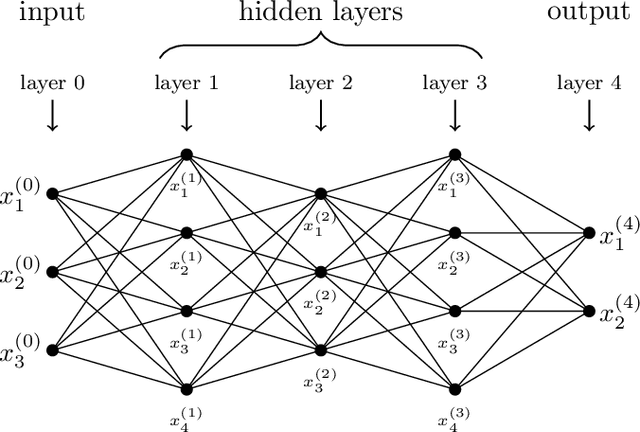
This book provides an introduction to the mathematical analysis of deep learning. It covers fundamental results in approximation theory, optimization theory, and statistical learning theory, which are the three main pillars of deep neural network theory. Serving as a guide for students and researchers in mathematics and related fields, the book aims to equip readers with foundational knowledge on the topic. It prioritizes simplicity over generality, and presents rigorous yet accessible results to help build an understanding of the essential mathematical concepts underpinning deep learning.