 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumerical Error Analysis of Large Language Models
Mar 13, 2025Large language models based on transformer architectures have become integral to state-of-the-art natural language processing applications. However, their training remains computationally expensive and exhibits instabilities, some of which are expected to be caused by finite-precision computations. We provide a theoretical analysis of the impact of round-off errors within the forward pass of a transformer architecture which yields fundamental bounds for these effects. In addition, we conduct a series of numerical experiments which demonstrate the practical relevance of our bounds. Our results yield concrete guidelines for choosing hyperparameters that mitigate round-off errors, leading to more robust and stable inference.
Digital Twin Brain: a simulation and assimilation platform for whole human brain
Aug 02, 2023In this work, we present a computing platform named digital twin brain (DTB) that can simulate spiking neuronal networks of the whole human brain scale and more importantly, a personalized biological brain structure. In comparison to most brain simulations with a homogeneous global structure, we highlight that the sparseness, couplingness and heterogeneity in the sMRI, DTI and PET data of the brain has an essential impact on the efficiency of brain simulation, which is proved from the scaling experiments that the DTB of human brain simulation is communication-intensive and memory-access intensive computing systems rather than computation-intensive. We utilize a number of optimization techniques to balance and integrate the computation loads and communication traffics from the heterogeneous biological structure to the general GPU-based HPC and achieve leading simulation performance for the whole human brain-scaled spiking neuronal networks. On the other hand, the biological structure, equipped with a mesoscopic data assimilation, enables the DTB to investigate brain cognitive function by a reverse-engineering method, which is demonstrated by a digital experiment of visual evaluation on the DTB. Furthermore, we believe that the developing DTB will be a promising powerful platform for a large of research orients including brain-inspiredintelligence, rain disease medicine and brain-machine interface.
Rethinking Precision of Pseudo Label: Test-Time Adaptation via Complementary Learning
Jan 15, 2023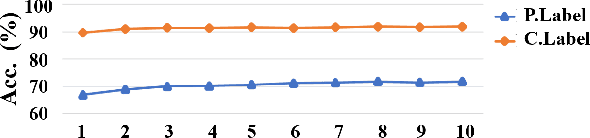

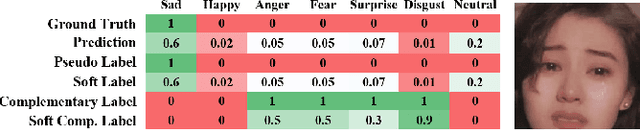
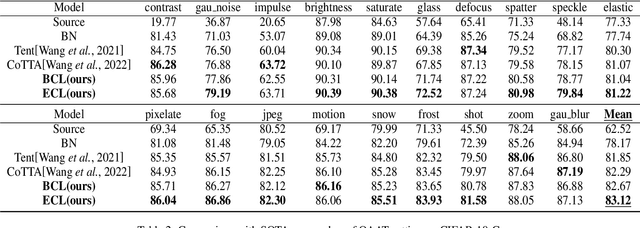
In this work, we propose a novel complementary learning approach to enhance test-time adaptation (TTA), which has been proven to exhibit good performance on testing data with distribution shifts such as corruptions. In test-time adaptation tasks, information from the source domain is typically unavailable and the model has to be optimized without supervision for test-time samples. Hence, usual methods assign labels for unannotated data with the prediction by a well-trained source model in an unsupervised learning framework. Previous studies have employed unsupervised objectives, such as the entropy of model predictions, as optimization targets to effectively learn features for test-time samples. However, the performance of the model is easily compromised by the quality of pseudo-labels, since inaccuracies in pseudo-labels introduce noise to the model. Therefore, we propose to leverage the "less probable categories" to decrease the risk of incorrect pseudo-labeling. The complementary label is introduced to designate these categories. We highlight that the risk function of complementary labels agrees with their Vanilla loss formula under the conventional true label distribution. Experiments show that the proposed learning algorithm achieves state-of-the-art performance on different datasets and experiment settings.