 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Nonasymptotic Scaling Guarantee of Hyperparameter Estimation in Inhomogeneous, Weakly-Dependent Complex Network Dynamical Systems
Jan 22, 2026Hierarchical Bayesian models are increasingly used in large, inhomogeneous complex network dynamical systems by modeling parameters as draws from a hyperparameter-governed distribution. However, theoretical guarantees for these estimates as the system size grows have been lacking. A critical concern is that hyperparameter estimation may diverge for larger networks, undermining the model's reliability. Formulating the system's evolution in a measure transport perspective, we propose a theoretical framework for estimating hyperparameters with mean-type observations, which are prevalent in many scientific applications. Our primary contribution is a nonasymptotic bound for the deviation of estimate of hyperparameters in inhomogeneous complex network dynamical systems with respect to network population size, which is established for a general family of optimization algorithms within a fixed observation duration. While we firstly establish a consistency result for systems with independent nodes, our main result extends this guarantee to the more challenging and realistic setting of weakly-dependent nodes. We validate our theoretical findings with numerical experiments on two representative models: a Susceptible-Infected-Susceptible model and a Spiking Neuronal Network model. In both cases, the results confirm that the estimation error decreases as the network population size increases, aligning with our theoretical guarantees. This research proposes the foundational theory to ensure that hierarchical Bayesian methods are statistically consistent for large-scale inhomogeneous systems, filling a gap in this area of theoretical research and justifying their application in practice.
Stochastic Forward-Forward Learning through Representational Dimensionality Compression
May 22, 2025The Forward-Forward (FF) algorithm provides a bottom-up alternative to backpropagation (BP) for training neural networks, relying on a layer-wise "goodness" function to guide learning. Existing goodness functions, inspired by energy-based learning (EBL), are typically defined as the sum of squared post-synaptic activations, neglecting the correlations between neurons. In this work, we propose a novel goodness function termed dimensionality compression that uses the effective dimensionality (ED) of fluctuating neural responses to incorporate second-order statistical structure. Our objective minimizes ED for clamped inputs when noise is considered while maximizing it across the sample distribution, promoting structured representations without the need to prepare negative samples. We demonstrate that this formulation achieves competitive performance compared to other non-BP methods. Moreover, we show that noise plays a constructive role that can enhance generalization and improve inference when predictions are derived from the mean of squared outputs, which is equivalent to making predictions based on the energy term. Our findings contribute to the development of more biologically plausible learning algorithms and suggest a natural fit for neuromorphic computing, where stochasticity is a computational resource rather than a nuisance. The code is available at https://github.com/ZhichaoZhu/StochasticForwardForward
Uncertainty Quantification in Working Memory via Moment Neural Networks
Nov 21, 2024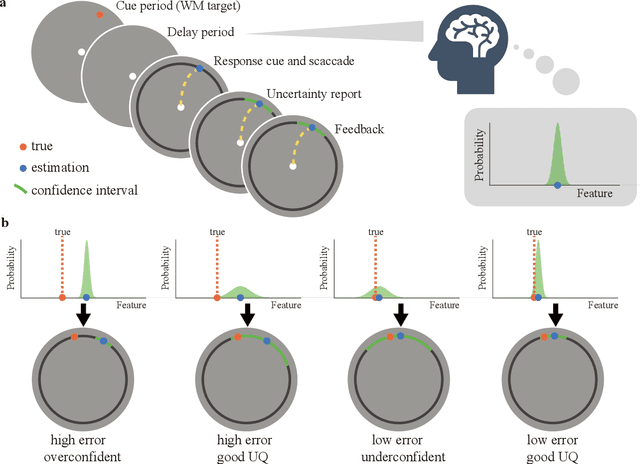
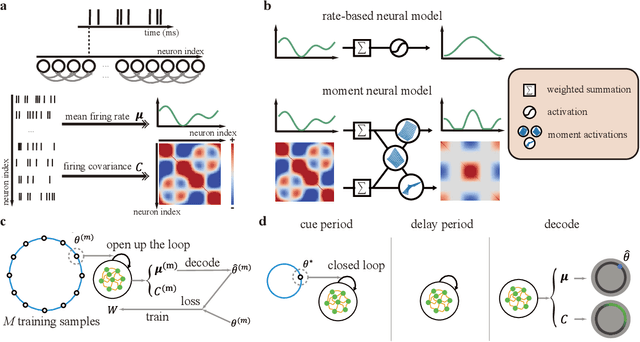
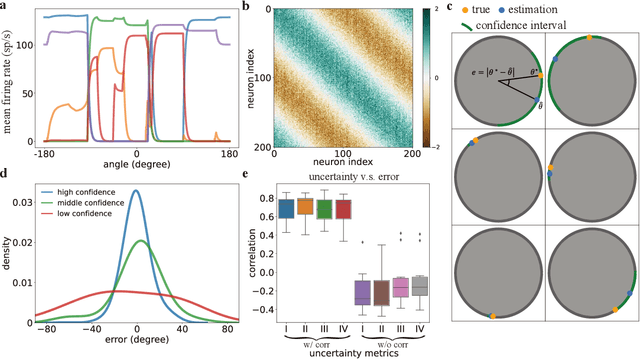
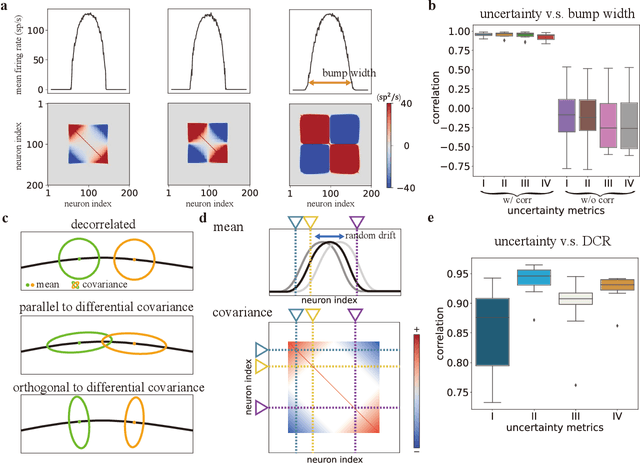
Humans possess a finely tuned sense of uncertainty that helps anticipate potential errors, vital for adaptive behavior and survival. However, the underlying neural mechanisms remain unclear. This study applies moment neural networks (MNNs) to explore the neural mechanism of uncertainty quantification in working memory (WM). The MNN captures nonlinear coupling of the first two moments in spiking neural networks (SNNs), identifying firing covariance as a key indicator of uncertainty in encoded information. Trained on a WM task, the model demonstrates coding precision and uncertainty quantification comparable to human performance. Analysis reveals a link between the probabilistic and sampling-based coding for uncertainty representation. Transferring the MNN's weights to an SNN replicates these results. Furthermore, the study provides testable predictions demonstrating how noise and heterogeneity enhance WM performance, highlighting their beneficial role rather than being mere biological byproducts. These findings offer insights into how the brain effectively manages uncertainty with exceptional accuracy.
Towards free-response paradigm: a theory on decision-making in spiking neural networks
Apr 16, 2024The energy-efficient and brain-like information processing abilities of Spiking Neural Networks (SNNs) have attracted considerable attention, establishing them as a crucial element of brain-inspired computing. One prevalent challenge encountered by SNNs is the trade-off between inference speed and accuracy, which requires sufficient time to achieve the desired level of performance. Drawing inspiration from animal behavior experiments that demonstrate a connection between decision-making reaction times, task complexity, and confidence levels, this study seeks to apply these insights to SNNs. The focus is on understanding how SNNs make inferences, with a particular emphasis on untangling the interplay between signal and noise in decision-making processes. The proposed theoretical framework introduces a new optimization objective for SNN training, highlighting the importance of not only the accuracy of decisions but also the development of predictive confidence through learning from past experiences. Experimental results demonstrate that SNNs trained according to this framework exhibit improved confidence expression, leading to better decision-making outcomes. In addition, a strategy is introduced for efficient decision-making during inference, which allows SNNs to complete tasks more quickly and can use stopping times as indicators of decision confidence. By integrating neuroscience insights with neuromorphic computing, this study opens up new possibilities to explore the capabilities of SNNs and advance their application in complex decision-making scenarios.
Efficient Combinatorial Optimization via Heat Diffusion
Mar 14, 2024Combinatorial optimization problems are widespread but inherently challenging due to their discrete nature.The primary limitation of existing methods is that they can only access a small fraction of the solution space at each iteration, resulting in limited efficiency for searching the global optimal. To overcome this challenge, diverging from conventional efforts of expanding the solver's search scope, we focus on enabling information to actively propagate to the solver through heat diffusion. By transforming the target function while preserving its optima, heat diffusion facilitates information flow from distant regions to the solver, providing more efficient navigation. Utilizing heat diffusion, we propose a framework for solving general combinatorial optimization problems. The proposed methodology demonstrates superior performance across a range of the most challenging and widely encountered combinatorial optimizations. Echoing recent advancements in harnessing thermodynamics for generative artificial intelligence, our study further reveals its significant potential in advancing combinatorial optimization.
Let LLMs Take on the Latest Challenges! A Chinese Dynamic Question Answering Benchmark
Mar 02, 2024

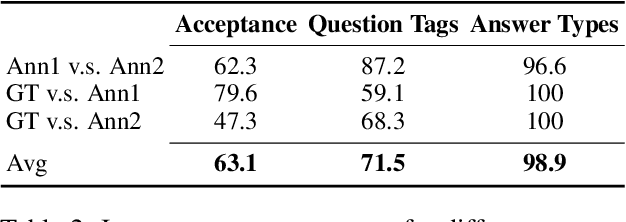
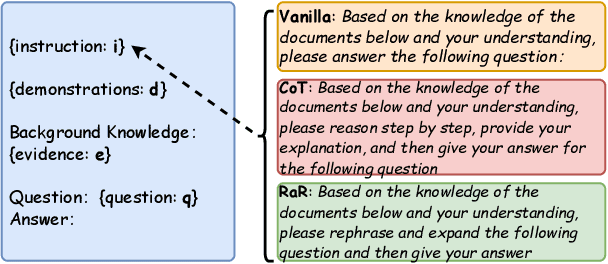
How to better evaluate the capabilities of Large Language Models (LLMs) is the focal point and hot topic in current LLMs research. Previous work has noted that due to the extremely high cost of iterative updates of LLMs, they are often unable to answer the latest dynamic questions well. To promote the improvement of Chinese LLMs' ability to answer dynamic questions, in this paper, we introduce CDQA, a Chinese Dynamic QA benchmark containing question-answer pairs related to the latest news on the Chinese Internet. We obtain high-quality data through a pipeline that combines humans and models, and carefully classify the samples according to the frequency of answer changes to facilitate a more fine-grained observation of LLMs' capabilities. We have also evaluated and analyzed mainstream and advanced Chinese LLMs on CDQA. Extensive experiments and valuable insights suggest that our proposed CDQA is challenging and worthy of more further study. We believe that the benchmark we provide will become one of the key data resources for improving LLMs' Chinese question-answering ability in the future.
Learn to integrate parts for whole through correlated neural variability
Jan 01, 2024Sensory perception originates from the responses of sensory neurons, which react to a collection of sensory signals linked to various physical attributes of a singular perceptual object. Unraveling how the brain extracts perceptual information from these neuronal responses is a pivotal challenge in both computational neuroscience and machine learning. Here we introduce a statistical mechanical theory, where perceptual information is first encoded in the correlated variability of sensory neurons and then reformatted into the firing rates of downstream neurons. Applying this theory, we illustrate the encoding of motion direction using neural covariance and demonstrate high-fidelity direction recovery by spiking neural networks. Networks trained under this theory also show enhanced performance in classifying natural images, achieving higher accuracy and faster inference speed. Our results challenge the traditional view of neural covariance as a secondary factor in neural coding, highlighting its potential influence on brain function.
Digital Twin Brain: a simulation and assimilation platform for whole human brain
Aug 02, 2023In this work, we present a computing platform named digital twin brain (DTB) that can simulate spiking neuronal networks of the whole human brain scale and more importantly, a personalized biological brain structure. In comparison to most brain simulations with a homogeneous global structure, we highlight that the sparseness, couplingness and heterogeneity in the sMRI, DTI and PET data of the brain has an essential impact on the efficiency of brain simulation, which is proved from the scaling experiments that the DTB of human brain simulation is communication-intensive and memory-access intensive computing systems rather than computation-intensive. We utilize a number of optimization techniques to balance and integrate the computation loads and communication traffics from the heterogeneous biological structure to the general GPU-based HPC and achieve leading simulation performance for the whole human brain-scaled spiking neuronal networks. On the other hand, the biological structure, equipped with a mesoscopic data assimilation, enables the DTB to investigate brain cognitive function by a reverse-engineering method, which is demonstrated by a digital experiment of visual evaluation on the DTB. Furthermore, we believe that the developing DTB will be a promising powerful platform for a large of research orients including brain-inspiredintelligence, rain disease medicine and brain-machine interface.
Modify Training Directions in Function Space to Reduce Generalization Error
Jul 25, 2023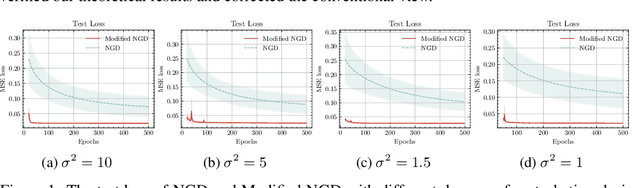
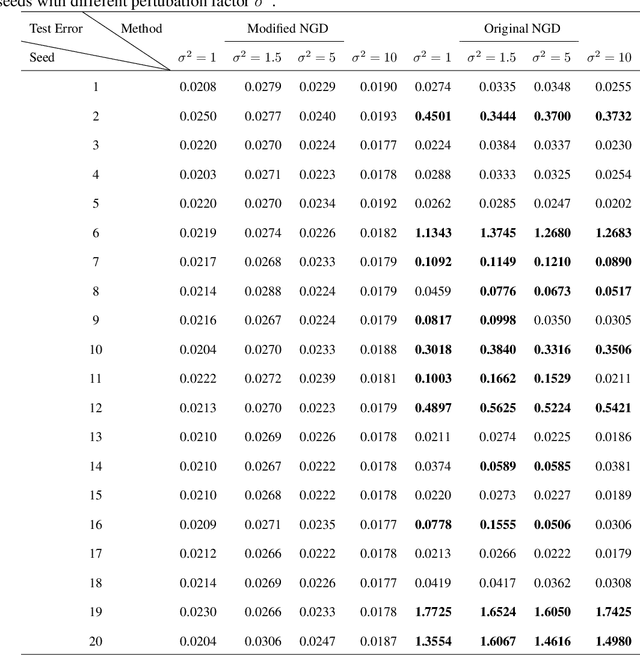
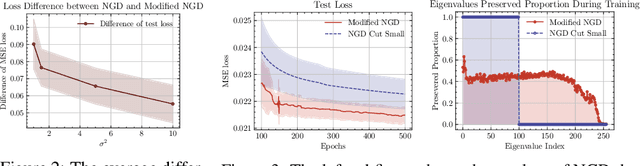
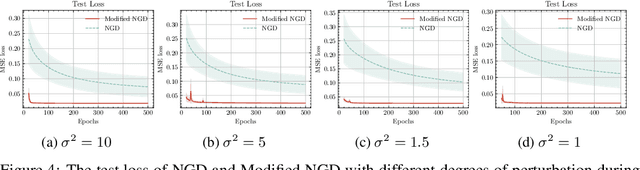
We propose theoretical analyses of a modified natural gradient descent method in the neural network function space based on the eigendecompositions of neural tangent kernel and Fisher information matrix. We firstly present analytical expression for the function learned by this modified natural gradient under the assumptions of Gaussian distribution and infinite width limit. Thus, we explicitly derive the generalization error of the learned neural network function using theoretical methods from eigendecomposition and statistics theory. By decomposing of the total generalization error attributed to different eigenspace of the kernel in function space, we propose a criterion for balancing the errors stemming from training set and the distribution discrepancy between the training set and the true data. Through this approach, we establish that modifying the training direction of the neural network in function space leads to a reduction in the total generalization error. Furthermore, We demonstrate that this theoretical framework is capable to explain many existing results of generalization enhancing methods. These theoretical results are also illustrated by numerical examples on synthetic data.
Probabilistic Computation with Emerging Covariance: Towards Efficient Uncertainty Quantification
May 31, 2023Building robust, interpretable, and secure artificial intelligence system requires some degree of quantifying and representing uncertainty via a probabilistic perspective, as it allows to mimic human cognitive abilities. However, probabilistic computation presents significant challenges due to its inherent complexity. In this paper, we develop an efficient and interpretable probabilistic computation framework by truncating the probabilistic representation up to its first two moments, i.e., mean and covariance. We instantiate the framework by training a deterministic surrogate of a stochastic network that learns the complex probabilistic representation via combinations of simple activations, encapsulating the non-linearities coupling of the mean and covariance. We show that when the mean is supervised for optimizing the task objective, the unsupervised covariance spontaneously emerging from the non-linear coupling with the mean faithfully captures the uncertainty associated with model predictions. Our research highlights the inherent computability and simplicity of probabilistic computation, enabling its wider application in large-scale settings.