 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-channel Prototype Network for few-shot Classification of Pathological Images
Nov 14, 2023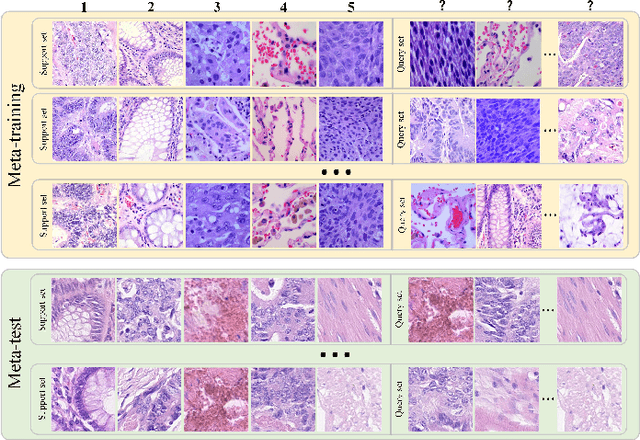
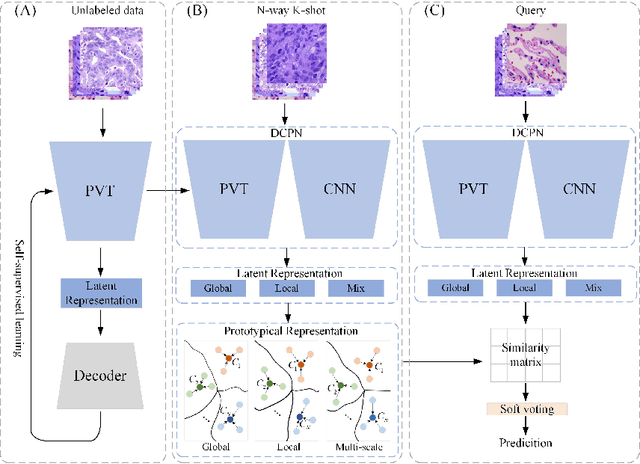
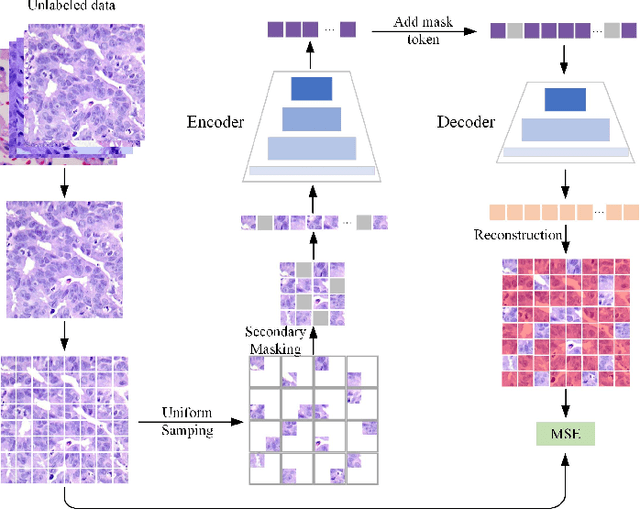
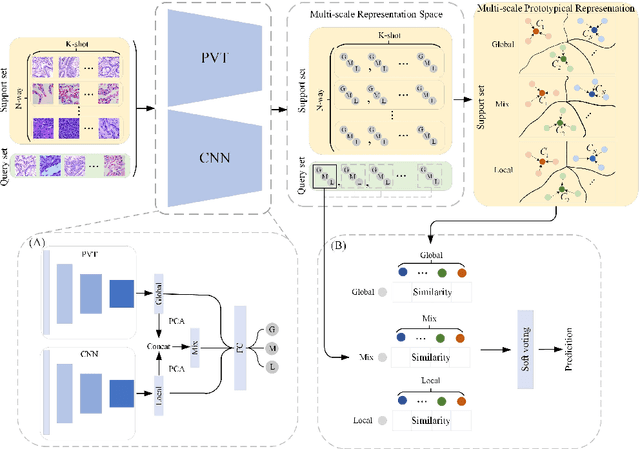
In pathology, the rarity of certain diseases and the complexity in annotating pathological images significantly hinder the creation of extensive, high-quality datasets. This limitation impedes the progress of deep learning-assisted diagnostic systems in pathology. Consequently, it becomes imperative to devise a technology that can discern new disease categories from a minimal number of annotated examples. Such a technology would substantially advance deep learning models for rare diseases. Addressing this need, we introduce the Dual-channel Prototype Network (DCPN), rooted in the few-shot learning paradigm, to tackle the challenge of classifying pathological images with limited samples. DCPN augments the Pyramid Vision Transformer (PVT) framework for few-shot classification via self-supervised learning and integrates it with convolutional neural networks. This combination forms a dual-channel architecture that extracts multi-scale, highly precise pathological features. The approach enhances the versatility of prototype representations and elevates the efficacy of prototype networks in few-shot pathological image classification tasks. We evaluated DCPN using three publicly available pathological datasets, configuring small-sample classification tasks that mirror varying degrees of clinical scenario domain shifts. Our experimental findings robustly affirm DCPN's superiority in few-shot pathological image classification, particularly in tasks within the same domain, where it achieves the benchmarks of supervised learning.
FedDKD: Federated Learning with Decentralized Knowledge Distillation
May 02, 2022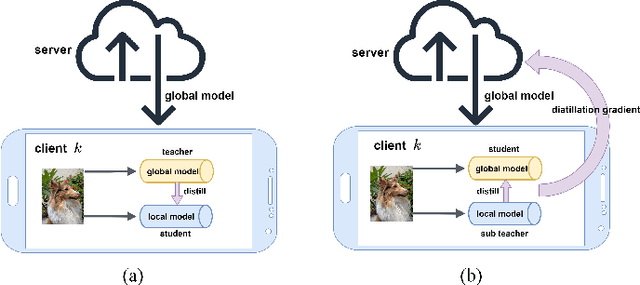
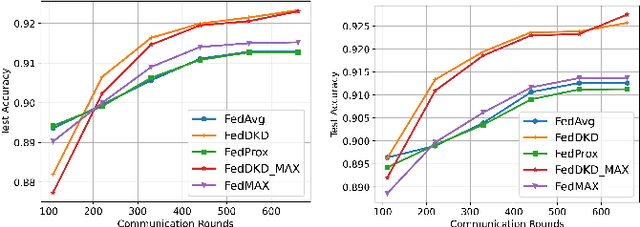
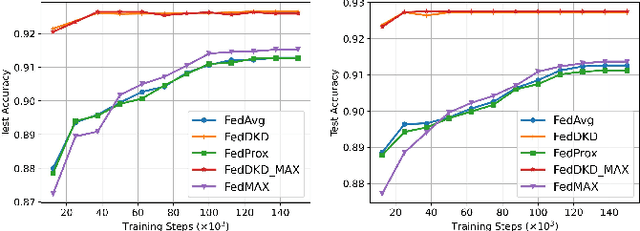
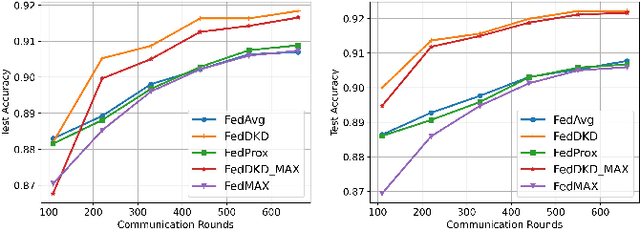
The performance of federated learning in neural networks is generally influenced by the heterogeneity of the data distribution. For a well-performing global model, taking a weighted average of the local models, as done by most existing federated learning algorithms, may not guarantee consistency with local models in the space of neural network maps. In this paper, we propose a novel framework of federated learning equipped with the process of decentralized knowledge distillation (FedDKD) (i.e., without data on the server). The FedDKD introduces a module of decentralized knowledge distillation (DKD) to distill the knowledge of the local models to train the global model by approaching the neural network map average based on the metric of divergence defined in the loss function, other than only averaging parameters as done in literature. Numeric experiments on various heterogeneous datasets reveal that FedDKD outperforms the state-of-the-art methods with more efficient communication and training in a few DKD steps, especially on some extremely heterogeneous datasets.