 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedDKD: Federated Learning with Decentralized Knowledge Distillation
Paper and Code
May 02, 2022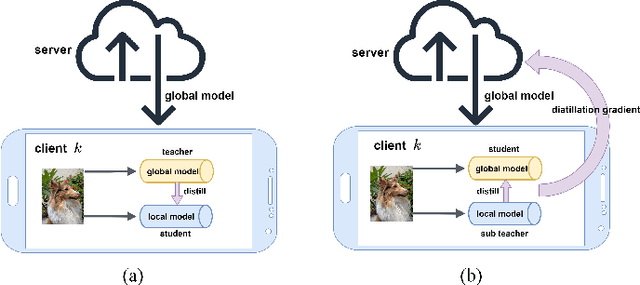
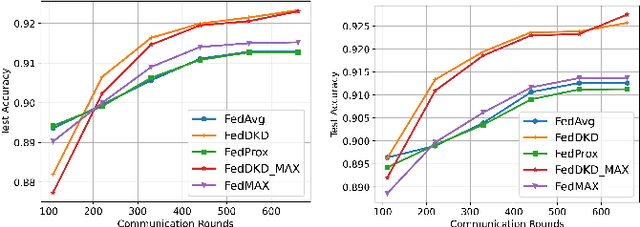
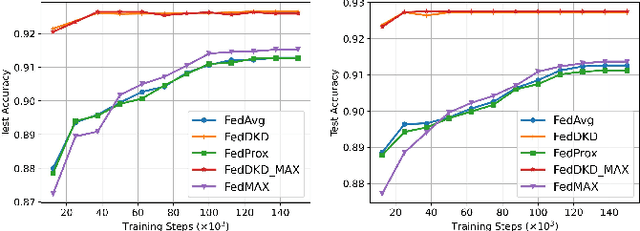
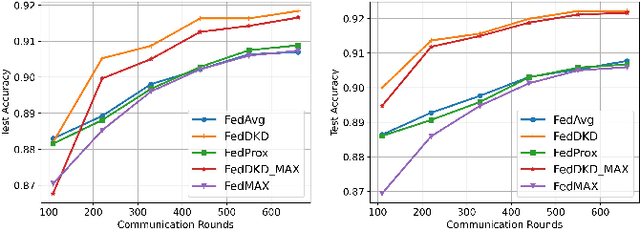
The performance of federated learning in neural networks is generally influenced by the heterogeneity of the data distribution. For a well-performing global model, taking a weighted average of the local models, as done by most existing federated learning algorithms, may not guarantee consistency with local models in the space of neural network maps. In this paper, we propose a novel framework of federated learning equipped with the process of decentralized knowledge distillation (FedDKD) (i.e., without data on the server). The FedDKD introduces a module of decentralized knowledge distillation (DKD) to distill the knowledge of the local models to train the global model by approaching the neural network map average based on the metric of divergence defined in the loss function, other than only averaging parameters as done in literature. Numeric experiments on various heterogeneous datasets reveal that FedDKD outperforms the state-of-the-art methods with more efficient communication and training in a few DKD steps, especially on some extremely heterogeneous datasets.