 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArenaRL: Scaling RL for Open-Ended Agents via Tournament-based Relative Ranking
Jan 10, 2026Reinforcement learning has substantially improved the performance of LLM agents on tasks with verifiable outcomes, but it still struggles on open-ended agent tasks with vast solution spaces (e.g., complex travel planning). Due to the absence of objective ground-truth for these tasks, current RL algorithms largely rely on reward models that assign scalar scores to individual responses. We contend that such pointwise scoring suffers from an inherent discrimination collapse: the reward model struggles to distinguish subtle advantages among different trajectories, resulting in scores within a group being compressed into a narrow range. Consequently, the effective reward signal becomes dominated by noise from the reward model, leading to optimization stagnation. To address this, we propose ArenaRL, a reinforcement learning paradigm that shifts from pointwise scalar scoring to intra-group relative ranking. ArenaRL introduces a process-aware pairwise evaluation mechanism, employing multi-level rubrics to assign fine-grained relative scores to trajectories. Additionally, we construct an intra-group adversarial arena and devise a tournament-based ranking scheme to obtain stable advantage signals. Empirical results confirm that the built seeded single-elimination scheme achieves nearly equivalent advantage estimation accuracy to full pairwise comparisons with O(N^2) complexity, while operating with only O(N) complexity, striking an optimal balance between efficiency and precision. Furthermore, to address the lack of full-cycle benchmarks for open-ended agents, we build Open-Travel and Open-DeepResearch, two high-quality benchmarks featuring a comprehensive pipeline covering SFT, RL training, and multi-dimensional evaluation. Extensive experiments show that ArenaRL substantially outperforms standard RL baselines, enabling LLM agents to generate more robust solutions for complex real-world tasks.
Data-driven modeling and supervisory control system optimization for plug-in hybrid electric vehicles
Jun 13, 2024
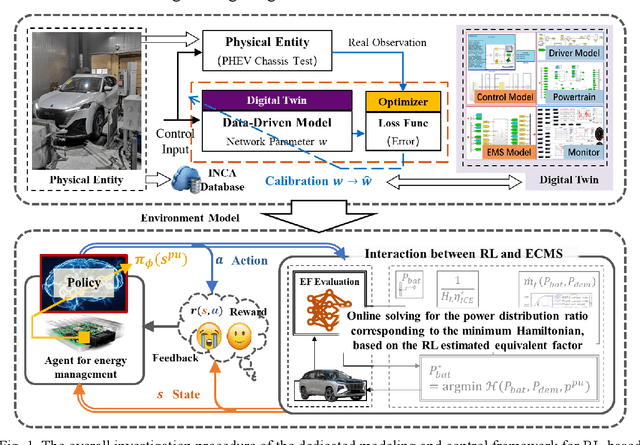


Learning-based intelligent energy management systems for plug-in hybrid electric vehicles (PHEVs) are crucial for achieving efficient energy utilization. However, their application faces system reliability challenges in the real world, which prevents widespread acceptance by original equipment manufacturers (OEMs). This paper begins by establishing a PHEV model based on physical and data-driven models, focusing on the high-fidelity training environment. It then proposes a real-vehicle application-oriented control framework, combining horizon-extended reinforcement learning (RL)-based energy management with the equivalent consumption minimization strategy (ECMS) to enhance practical applicability, and improves the flawed method of equivalent factor evaluation based on instantaneous driving cycle and powertrain states found in existing research. Finally, comprehensive simulation and hardware-in-the-loop validation are carried out which demonstrates the advantages of the proposed control framework in fuel economy over adaptive-ECMS and rule-based strategies. Compared to conventional RL architectures that directly control powertrain components, the proposed control method not only achieves similar optimality but also significantly enhances the disturbance resistance of the energy management system, providing an effective control framework for RL-based energy management strategies aimed at real-vehicle applications by OEMs.
RaFe: Ranking Feedback Improves Query Rewriting for RAG
May 23, 2024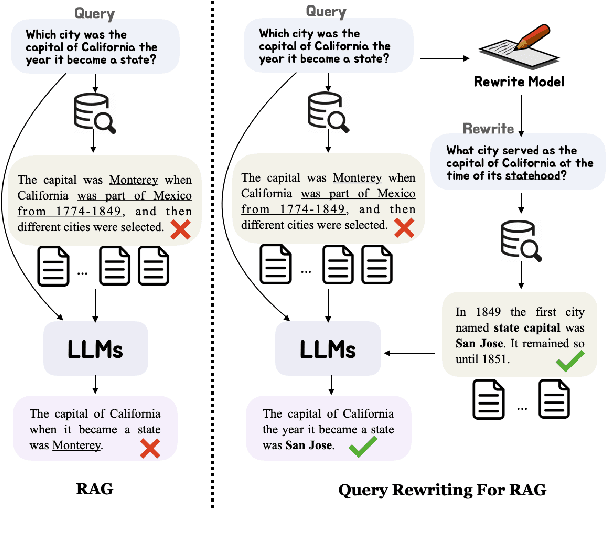
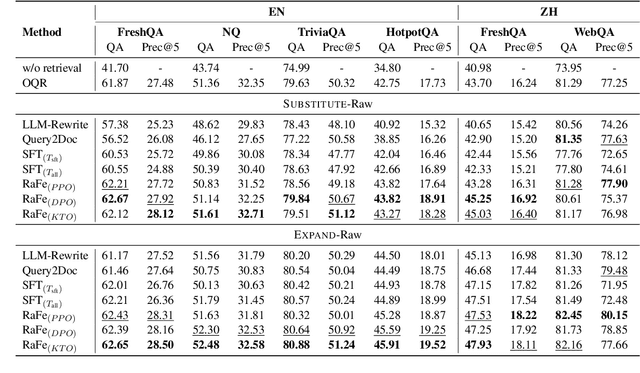
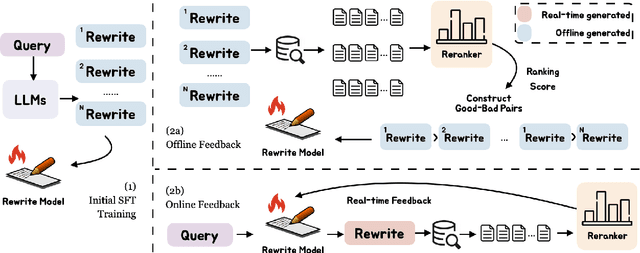
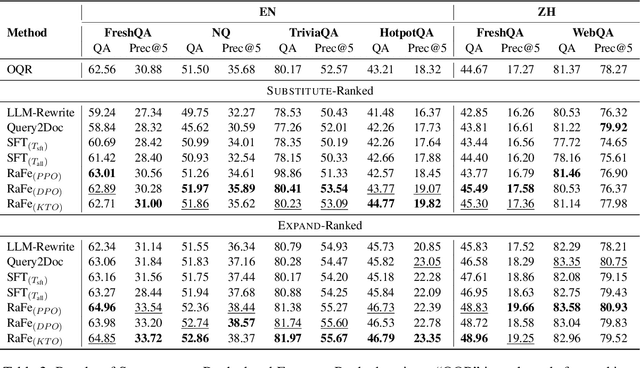
As Large Language Models (LLMs) and Retrieval Augmentation Generation (RAG) techniques have evolved, query rewriting has been widely incorporated into the RAG system for downstream tasks like open-domain QA. Many works have attempted to utilize small models with reinforcement learning rather than costly LLMs to improve query rewriting. However, current methods require annotations (e.g., labeled relevant documents or downstream answers) or predesigned rewards for feedback, which lack generalization, and fail to utilize signals tailored for query rewriting. In this paper, we propose ours, a framework for training query rewriting models free of annotations. By leveraging a publicly available reranker, ours~provides feedback aligned well with the rewriting objectives. Experimental results demonstrate that ours~can obtain better performance than baselines.
Let LLMs Take on the Latest Challenges! A Chinese Dynamic Question Answering Benchmark
Mar 02, 2024

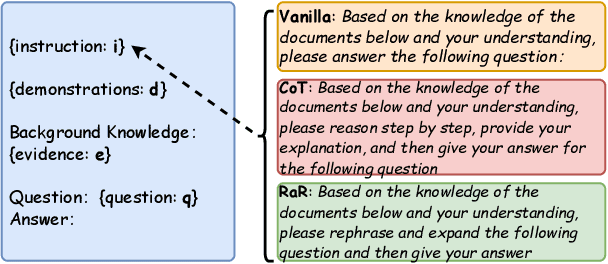
How to better evaluate the capabilities of Large Language Models (LLMs) is the focal point and hot topic in current LLMs research. Previous work has noted that due to the extremely high cost of iterative updates of LLMs, they are often unable to answer the latest dynamic questions well. To promote the improvement of Chinese LLMs' ability to answer dynamic questions, in this paper, we introduce CDQA, a Chinese Dynamic QA benchmark containing question-answer pairs related to the latest news on the Chinese Internet. We obtain high-quality data through a pipeline that combines humans and models, and carefully classify the samples according to the frequency of answer changes to facilitate a more fine-grained observation of LLMs' capabilities. We have also evaluated and analyzed mainstream and advanced Chinese LLMs on CDQA. Extensive experiments and valuable insights suggest that our proposed CDQA is challenging and worthy of more further study. We believe that the benchmark we provide will become one of the key data resources for improving LLMs' Chinese question-answering ability in the future.
Safe Reinforcement Learning in Tensor Reproducing Kernel Hilbert Space
Dec 01, 2023This paper delves into the problem of safe reinforcement learning (RL) in a partially observable environment with the aim of achieving safe-reachability objectives. In traditional partially observable Markov decision processes (POMDP), ensuring safety typically involves estimating the belief in latent states. However, accurately estimating an optimal Bayesian filter in POMDP to infer latent states from observations in a continuous state space poses a significant challenge, largely due to the intractable likelihood. To tackle this issue, we propose a stochastic model-based approach that guarantees RL safety almost surely in the face of unknown system dynamics and partial observation environments. We leveraged the Predictive State Representation (PSR) and Reproducing Kernel Hilbert Space (RKHS) to represent future multi-step observations analytically, and the results in this context are provable. Furthermore, we derived essential operators from the kernel Bayes' rule, enabling the recursive estimation of future observations using various operators. Under the assumption of \textit{undercompleness}, a polynomial sample complexity is established for the RL algorithm for the infinite size of observation and action spaces, ensuring an $\epsilon-$suboptimal safe policy guarantee.
Geo-Encoder: A Chunk-Argument Bi-Encoder Framework for Chinese Geographic Re-Ranking
Sep 04, 2023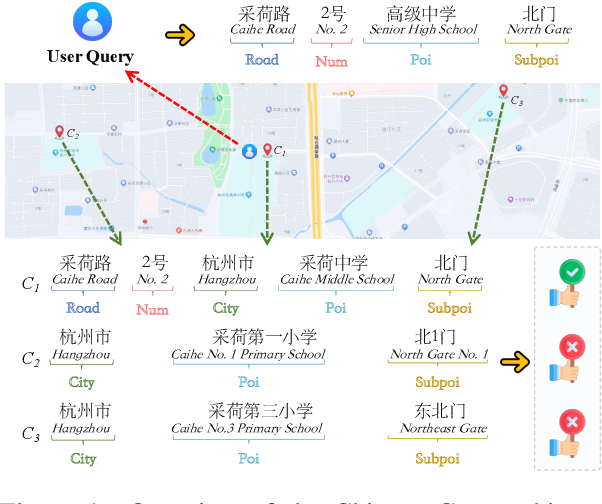
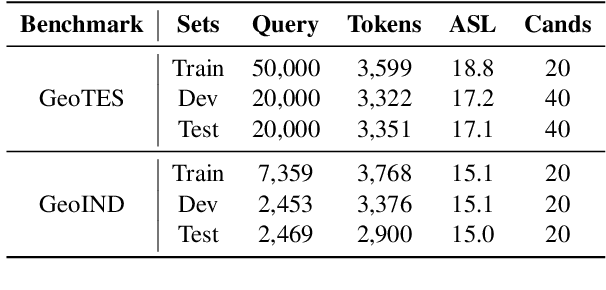
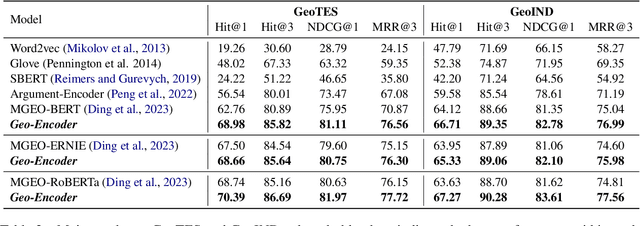
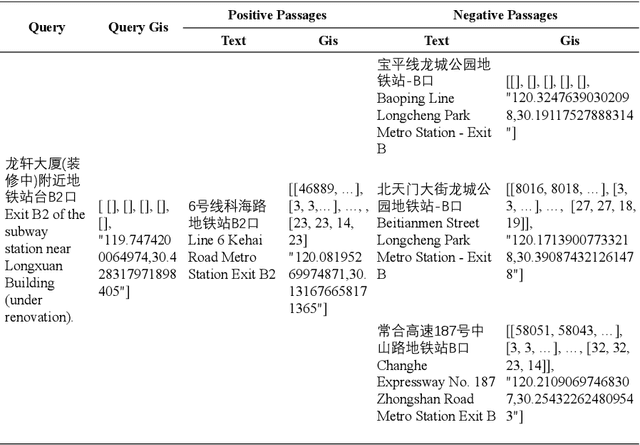
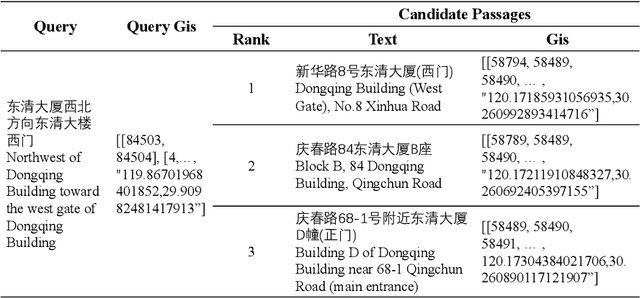
Chinese geographic re-ranking task aims to find the most relevant addresses among retrieved candidates, which is crucial for location-related services such as navigation maps. Unlike the general sentences, geographic contexts are closely intertwined with geographical concepts, from general spans (e.g., province) to specific spans (e.g., road). Given this feature, we propose an innovative framework, namely Geo-Encoder, to more effectively integrate Chinese geographical semantics into re-ranking pipelines. Our methodology begins by employing off-the-shelf tools to associate text with geographical spans, treating them as chunking units. Then, we present a multi-task learning module to simultaneously acquire an effective attention matrix that determines chunk contributions to extra semantic representations. Furthermore, we put forth an asynchronous update mechanism for the proposed addition task, aiming to guide the model capable of effectively focusing on specific chunks. Experiments on two distinct Chinese geographic re-ranking datasets, show that the Geo-Encoder achieves significant improvements when compared to state-of-the-art baselines. Notably, it leads to a substantial improvement in the Hit@1 score of MGEO-BERT, increasing it by 6.22% from 62.76 to 68.98 on the GeoTES dataset.
GeoGLUE: A GeoGraphic Language Understanding Evaluation Benchmark
May 11, 2023
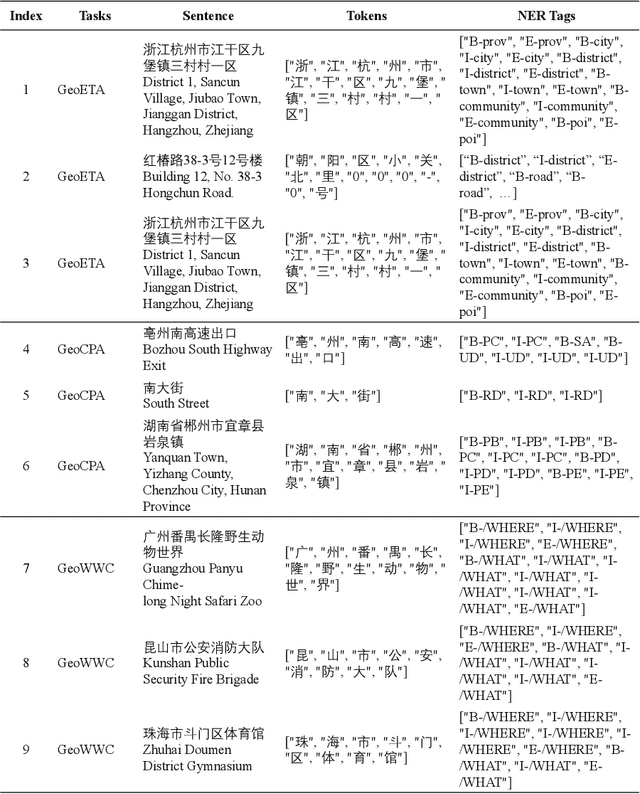
With a fast developing pace of geographic applications, automatable and intelligent models are essential to be designed to handle the large volume of information. However, few researchers focus on geographic natural language processing, and there has never been a benchmark to build a unified standard. In this work, we propose a GeoGraphic Language Understanding Evaluation benchmark, named GeoGLUE. We collect data from open-released geographic resources and introduce six natural language understanding tasks, including geographic textual similarity on recall, geographic textual similarity on rerank, geographic elements tagging, geographic composition analysis, geographic where what cut, and geographic entity alignment. We also pro vide evaluation experiments and analysis of general baselines, indicating the effectiveness and significance of the GeoGLUE benchmark.
A Multi-Modal Geographic Pre-Training Method
Jan 11, 2023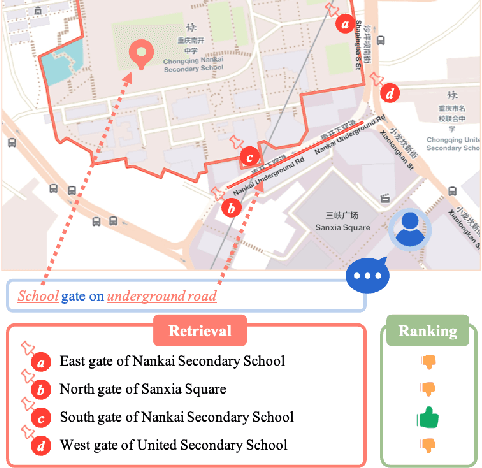


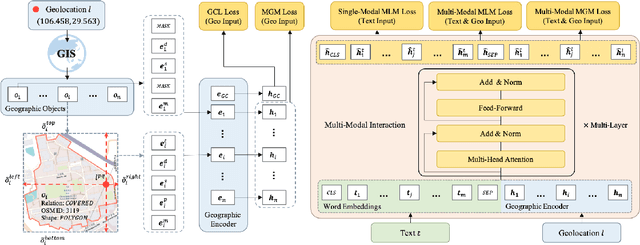
As a core task in location-based services (LBS) (e.g., navigation maps), query and point of interest (POI) matching connects users' intent with real-world geographic information. Recently, pre-trained models (PTMs) have made advancements in many natural language processing (NLP) tasks. Generic text-based PTMs do not have enough geographic knowledge for query-POI matching. To overcome this limitation, related literature attempts to employ domain-adaptive pre-training based on geo-related corpus. However, a query generally contains mentions of multiple geographic objects, such as nearby roads and regions of interest (ROIs). The geographic context (GC), i.e., these diverse geographic objects and their relationships, is therefore pivotal to retrieving the most relevant POI. Single-modal PTMs can barely make use of the important GC and therefore have limited performance. In this work, we propose a novel query-POI matching method Multi-modal Geographic language model (MGeo), which comprises a geographic encoder and a multi-modal interaction module. MGeo represents GC as a new modality and is able to fully extract multi-modal correlations for accurate query-POI matching. Besides, there is no publicly available benchmark for this topic. In order to facilitate further research, we build a new open-source large-scale benchmark Geographic TExtual Similarity (GeoTES). The POIs come from an open-source geographic information system (GIS). The queries are manually generated by annotators to prevent privacy issues. Compared with several strong baselines, the extensive experiment results and detailed ablation analyses on GeoTES demonstrate that our proposed multi-modal pre-training method can significantly improve the query-POI matching capability of generic PTMs, even when the queries' GC is not provided. Our code and dataset are publicly available at https://github.com/PhantomGrapes/MGeo.
Forging Multiple Training Objectives for Pre-trained Language Models via Meta-Learning
Oct 19, 2022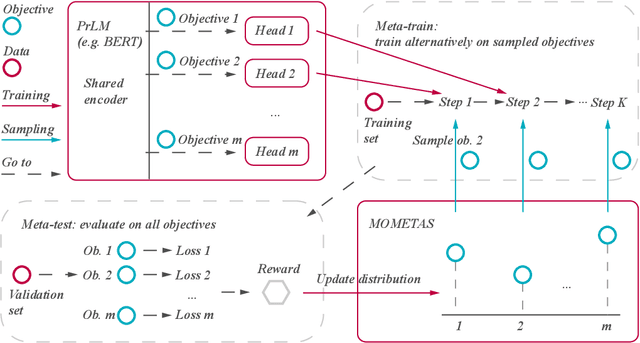
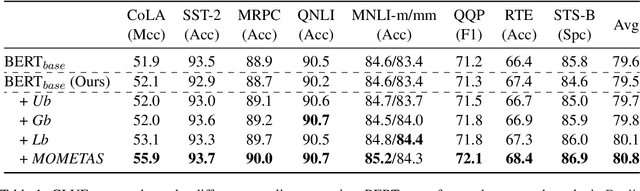
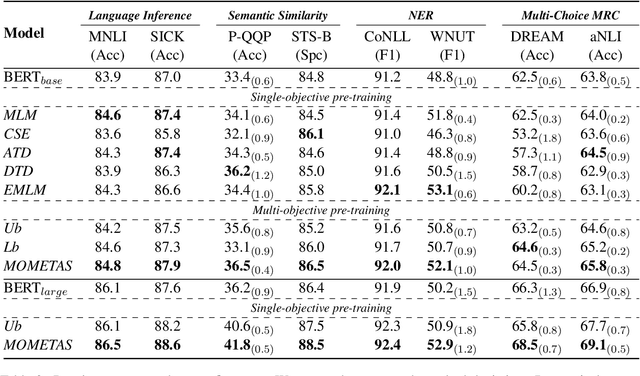
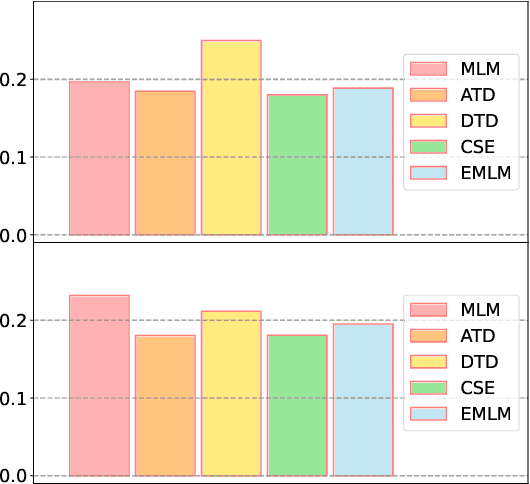
Multiple pre-training objectives fill the vacancy of the understanding capability of single-objective language modeling, which serves the ultimate purpose of pre-trained language models (PrLMs), generalizing well on a mass of scenarios. However, learning multiple training objectives in a single model is challenging due to the unknown relative significance as well as the potential contrariety between them. Empirical studies have shown that the current objective sampling in an ad-hoc manual setting makes the learned language representation barely converge to the desired optimum. Thus, we propose \textit{MOMETAS}, a novel adaptive sampler based on meta-learning, which learns the latent sampling pattern on arbitrary pre-training objectives. Such a design is lightweight with negligible additional training overhead. To validate our approach, we adopt five objectives and conduct continual pre-training with BERT-base and BERT-large models, where MOMETAS demonstrates universal performance gain over other rule-based sampling strategies on 14 natural language processing tasks.
AISHELL-NER: Named Entity Recognition from Chinese Speech
Feb 17, 2022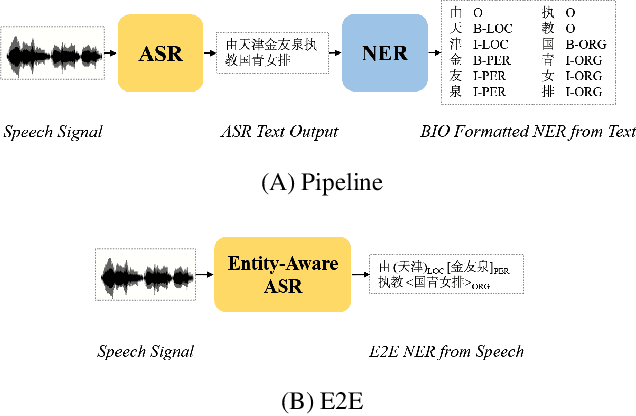
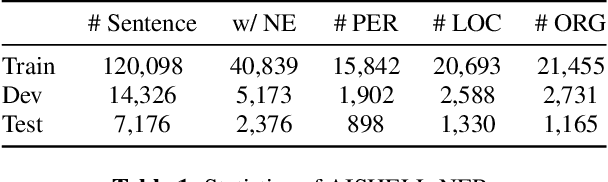
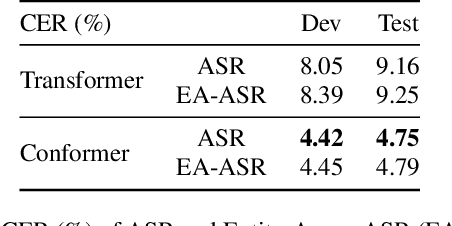
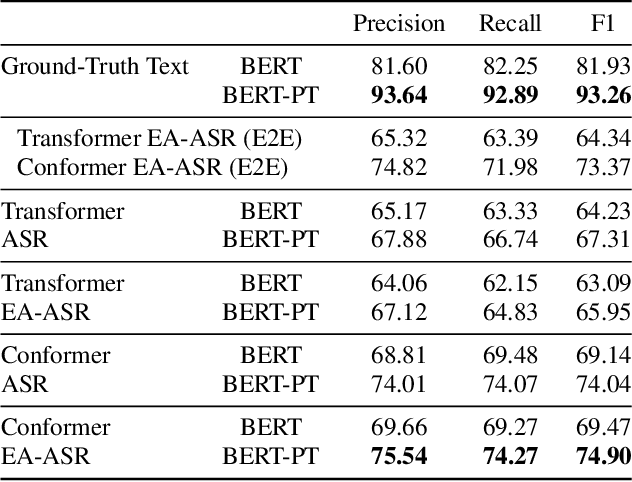
Named Entity Recognition (NER) from speech is among Spoken Language Understanding (SLU) tasks, aiming to extract semantic information from the speech signal. NER from speech is usually made through a two-step pipeline that consists of (1) processing the audio using an Automatic Speech Recognition (ASR) system and (2) applying an NER tagger to the ASR outputs. Recent works have shown the capability of the End-to-End (E2E) approach for NER from English and French speech, which is essentially entity-aware ASR. However, due to the many homophones and polyphones that exist in Chinese, NER from Chinese speech is effectively a more challenging task. In this paper, we introduce a new dataset AISEHLL-NER for NER from Chinese speech. Extensive experiments are conducted to explore the performance of several state-of-the-art methods. The results demonstrate that the performance could be improved by combining entity-aware ASR and pretrained NER tagger, which can be easily applied to the modern SLU pipeline. The dataset is publicly available at github.com/Alibaba-NLP/AISHELL-NER.