 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFURINA: Free from Unmergeable Router via LINear Aggregation of mixed experts
Sep 18, 2025The Mixture of Experts (MoE) paradigm has been successfully integrated into Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning (PEFT), delivering performance gains with minimal parameter overhead. However, a key limitation of existing MoE-LoRA methods is their reliance on a discrete router, which prevents the integration of the MoE components into the backbone model. To overcome this, we propose FURINA, a novel Free from Unmergeable Router framework based on the LINear Aggregation of experts. FURINA eliminates the router by introducing a Self-Routing mechanism. This is achieved through three core innovations: (1) decoupled learning of the direction and magnitude for LoRA adapters, (2) a shared learnable magnitude vector for consistent activation scaling, and (3) expert selection loss that encourages divergent expert activation. The proposed mechanism leverages the angular similarity between the input and each adapter's directional component to activate experts, which are then scaled by the shared magnitude vector. This design allows the output norm to naturally reflect the importance of each expert, thereby enabling dynamic, router-free routing. The expert selection loss further sharpens this behavior by encouraging sparsity and aligning it with standard MoE activation patterns. We also introduce a shared expert within the MoE-LoRA block that provides stable, foundational knowledge. To the best of our knowledge, FURINA is the first router-free, MoE-enhanced LoRA method that can be fully merged into the backbone model, introducing zero additional inference-time cost or complexity. Extensive experiments demonstrate that FURINA not only significantly outperforms standard LoRA but also matches or surpasses the performance of existing MoE-LoRA methods, while eliminating the extra inference-time overhead of MoE.
Rethinking Precision of Pseudo Label: Test-Time Adaptation via Complementary Learning
Jan 15, 2023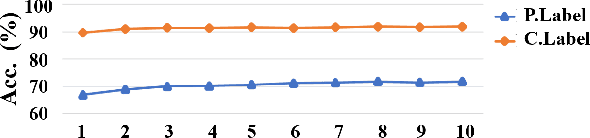

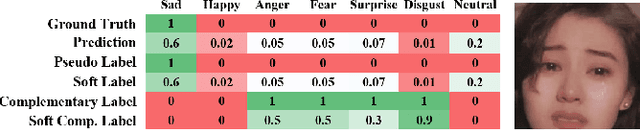
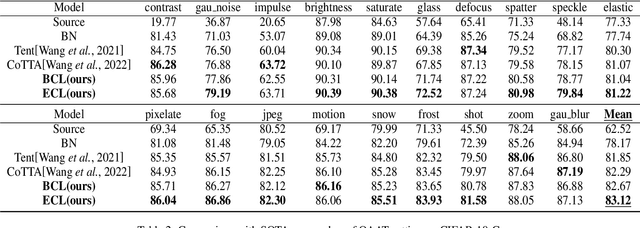
In this work, we propose a novel complementary learning approach to enhance test-time adaptation (TTA), which has been proven to exhibit good performance on testing data with distribution shifts such as corruptions. In test-time adaptation tasks, information from the source domain is typically unavailable and the model has to be optimized without supervision for test-time samples. Hence, usual methods assign labels for unannotated data with the prediction by a well-trained source model in an unsupervised learning framework. Previous studies have employed unsupervised objectives, such as the entropy of model predictions, as optimization targets to effectively learn features for test-time samples. However, the performance of the model is easily compromised by the quality of pseudo-labels, since inaccuracies in pseudo-labels introduce noise to the model. Therefore, we propose to leverage the "less probable categories" to decrease the risk of incorrect pseudo-labeling. The complementary label is introduced to designate these categories. We highlight that the risk function of complementary labels agrees with their Vanilla loss formula under the conventional true label distribution. Experiments show that the proposed learning algorithm achieves state-of-the-art performance on different datasets and experiment settings.