 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAMP: Look-Ahead Mixed-Precision Inference of Large Language Models
Jan 29, 2026Mixed-precision computations are a hallmark of the current stage of AI, driving the progress in large language models towards efficient, locally deployable solutions. This article addresses the floating-point computation of compositionally-rich functions, concentrating on transformer inference. Based on the rounding error analysis of a composition $f(g(\mathrm{x}))$, we provide an adaptive strategy that selects a small subset of components of $g(\mathrm{x})$ to be computed more accurately while all other computations can be carried out with lower accuracy. We then explain how this strategy can be applied to different compositions within a transformer and illustrate its overall effect on transformer inference. We study the effectiveness of this algorithm numerically on GPT-2 models and demonstrate that already very low recomputation rates allow for improvements of up to two orders of magnitude in accuracy.
Numerical Error Analysis of Large Language Models
Mar 13, 2025Large language models based on transformer architectures have become integral to state-of-the-art natural language processing applications. However, their training remains computationally expensive and exhibits instabilities, some of which are expected to be caused by finite-precision computations. We provide a theoretical analysis of the impact of round-off errors within the forward pass of a transformer architecture which yields fundamental bounds for these effects. In addition, we conduct a series of numerical experiments which demonstrate the practical relevance of our bounds. Our results yield concrete guidelines for choosing hyperparameters that mitigate round-off errors, leading to more robust and stable inference.
When big data actually are low-rank, or entrywise approximation of certain function-generated matrices
Jul 03, 2024The article concerns low-rank approximation of matrices generated by sampling a smooth function of two $m$-dimensional variables. We refute an argument made in the literature that, for a specific class of analytic functions, such matrices admit accurate entrywise approximation of rank that is independent of $m$. We provide a theoretical explanation of the numerical results presented in support of this argument, describing three narrower classes of functions for which $n \times n$ function-generated matrices can be approximated within an entrywise error of order $\varepsilon$ with rank $\mathcal{O}(\log(n) \varepsilon^{-2} \mathrm{polylog}(\varepsilon^{-1}))$ that is independent of the dimension $m$: (i) functions of the inner product of the two variables, (ii) functions of the squared Euclidean distance between the variables, and (iii) shift-invariant positive-definite kernels. We extend our argument to low-rank tensor-train approximation of tensors generated with functions of the multi-linear product of their $m$-dimensional variables. We discuss our results in the context of low-rank approximation of attention in transformer neural networks.
Variational Bayesian inference for CP tensor completion with side information
Jun 29, 2022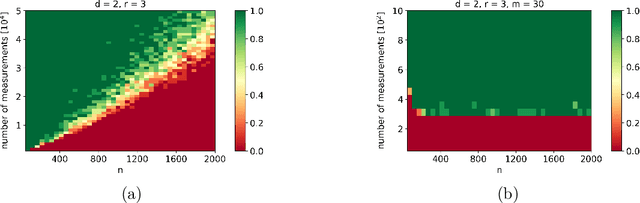

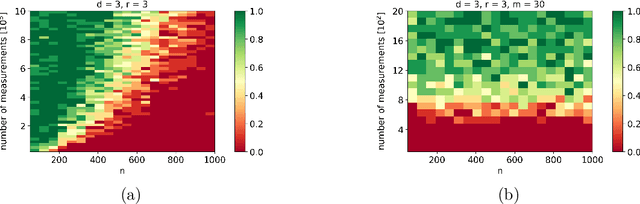
We propose a message passing algorithm, based on variational Bayesian inference, for low-rank tensor completion with automatic rank determination in the canonical polyadic format when additional side information (SI) is given. The SI comes in the form of low-dimensional subspaces the contain the fiber spans of the tensor (columns, rows, tubes, etc.). We validate the regularization properties induced by SI with extensive numerical experiments on synthetic and real-world data and present the results about tensor recovery and rank determination. The results show that the number of samples required for successful completion is significantly reduced in the presence of SI. We also discuss the origin of a bump in the phase transition curves that exists when the dimensionality of SI is comparable with that of the tensor.
Tensor train completion: local recovery guarantees via Riemannian optimization
Oct 08, 2021
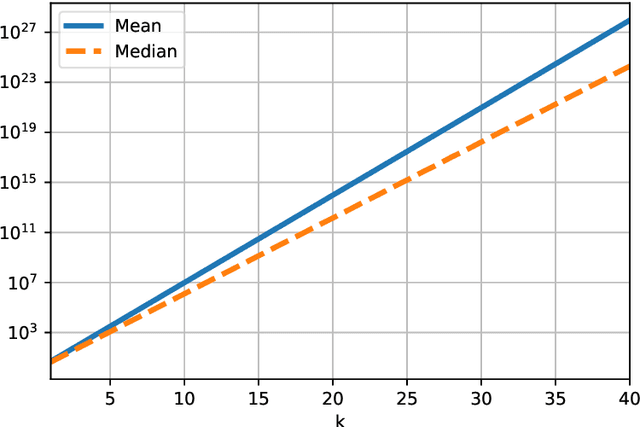
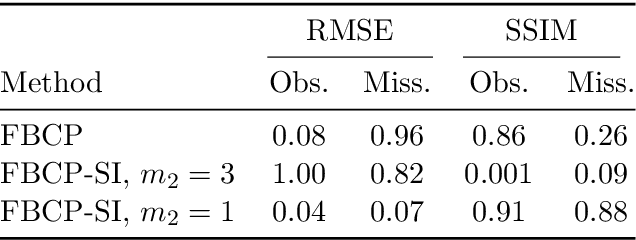
In this work we estimate the number of randomly selected elements of a tensor that with high probability guarantees local convergence of Riemannian gradient descent for tensor train completion. We derive a new bound for the orthogonal projections onto the tangent spaces based on the harmonic mean of the unfoldings' singular values and introduce a notion of core coherence for tensor trains. We also extend the results to tensor train completion with side information and obtain the corresponding local convergence guarantees.