Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathematical theory of deep learning
Paper and Code
Jul 25, 2024
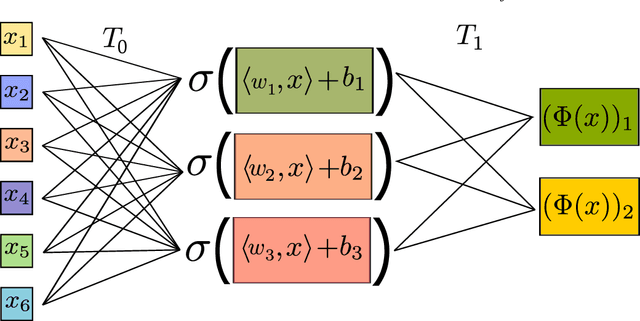
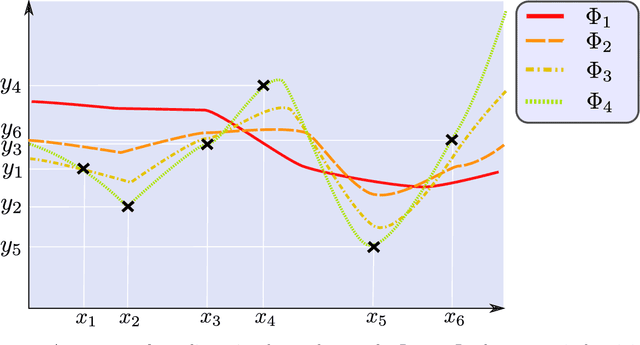
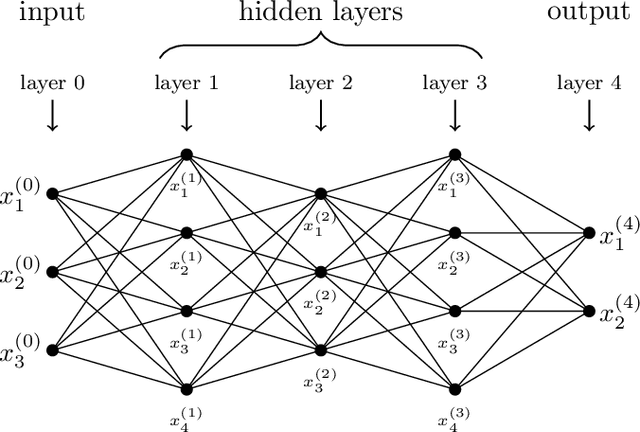
This book provides an introduction to the mathematical analysis of deep learning. It covers fundamental results in approximation theory, optimization theory, and statistical learning theory, which are the three main pillars of deep neural network theory. Serving as a guide for students and researchers in mathematics and related fields, the book aims to equip readers with foundational knowledge on the topic. It prioritizes simplicity over generality, and presents rigorous yet accessible results to help build an understanding of the essential mathematical concepts underpinning deep learning.
View paper on