 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Semi-Supervised Learning to Enhance Data Mining for Image Classification under Limited Labeled Data
Nov 27, 2024



In the 21st-century information age, with the development of big data technology, effectively extracting valuable information from massive data has become a key issue. Traditional data mining methods are inadequate when faced with large-scale, high-dimensional and complex data. Especially when labeled data is scarce, their performance is greatly limited. This study optimizes data mining algorithms by introducing semi-supervised learning methods, aiming to improve the algorithm's ability to utilize unlabeled data, thereby achieving more accurate data analysis and pattern recognition under limited labeled data conditions. Specifically, we adopt a self-training method and combine it with a convolutional neural network (CNN) for image feature extraction and classification, and continuously improve the model prediction performance through an iterative process. The experimental results demonstrate that the proposed method significantly outperforms traditional machine learning techniques such as Support Vector Machine (SVM), XGBoost, and Multi-Layer Perceptron (MLP) on the CIFAR-10 image classification dataset. Notable improvements were observed in key performance metrics, including accuracy, recall, and F1 score. Furthermore, the robustness and noise-resistance capabilities of the semi-supervised CNN model were validated through experiments under varying noise levels, confirming its practical applicability in real-world scenarios.
Enhancing Few-Shot Learning with Integrated Data and GAN Model Approaches
Nov 25, 2024This paper presents an innovative approach to enhancing few-shot learning by integrating data augmentation with model fine-tuning in a framework designed to tackle the challenges posed by small-sample data. Recognizing the critical limitations of traditional machine learning models that require large datasets-especially in fields such as drug discovery, target recognition, and malicious traffic detection-this study proposes a novel strategy that leverages Generative Adversarial Networks (GANs) and advanced optimization techniques to improve model performance with limited data. Specifically, the paper addresses the noise and bias issues introduced by data augmentation methods, contrasting them with model-based approaches, such as fine-tuning and metric learning, which rely heavily on related datasets. By combining Markov Chain Monte Carlo (MCMC) sampling and discriminative model ensemble strategies within a GAN framework, the proposed model adjusts generative and discriminative distributions to simulate a broader range of relevant data. Furthermore, it employs MHLoss and a reparameterized GAN ensemble to enhance stability and accelerate convergence, ultimately leading to improved classification performance on small-sample images and structured datasets. Results confirm that the MhERGAN algorithm developed in this research is highly effective for few-shot learning, offering a practical solution that bridges data scarcity with high-performing model adaptability and generalization.
Robust Real-time Segmentation of Bio-Morphological Features in Human Cherenkov Imaging during Radiotherapy via Deep Learning
Sep 09, 2024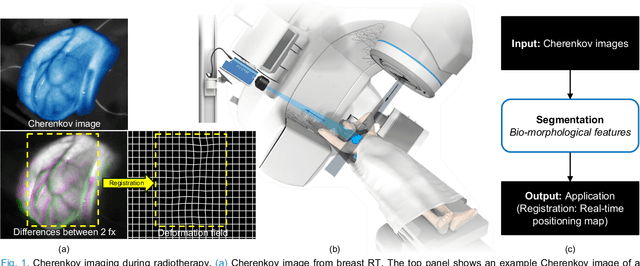
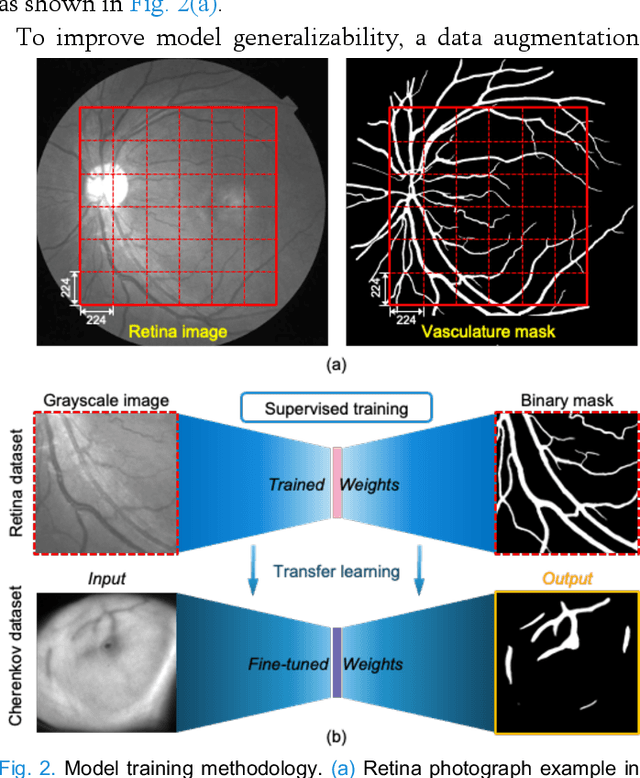

Cherenkov imaging enables real-time visualization of megavoltage X-ray or electron beam delivery to the patient during Radiation Therapy (RT). Bio-morphological features, such as vasculature, seen in these images are patient-specific signatures that can be used for verification of positioning and motion management that are essential to precise RT treatment. However until now, no concerted analysis of this biological feature-based tracking was utilized because of the slow speed and accuracy of conventional image processing for feature segmentation. This study demonstrated the first deep learning framework for such an application, achieving video frame rate processing. To address the challenge of limited annotation of these features in Cherenkov images, a transfer learning strategy was applied. A fundus photography dataset including 20,529 patch retina images with ground-truth vessel annotation was used to pre-train a ResNet segmentation framework. Subsequently, a small Cherenkov dataset (1,483 images from 212 treatment fractions of 19 breast cancer patients) with known annotated vasculature masks was used to fine-tune the model for accurate segmentation prediction. This deep learning framework achieved consistent and rapid segmentation of Cherenkov-imaged bio-morphological features on another 19 patients, including subcutaneous veins, scars, and pigmented skin. Average segmentation by the model achieved Dice score of 0.85 and required less than 0.7 milliseconds processing time per instance. The model demonstrated outstanding consistency against input image variances and speed compared to conventional manual segmentation methods, laying the foundation for online segmentation in real-time monitoring in a prospective setting.
CDSD: Chinese Dysarthria Speech Database
Oct 24, 2023



We present the Chinese Dysarthria Speech Database (CDSD) as a valuable resource for dysarthria research. This database comprises speech data from 24 participants with dysarthria. Among these participants, one recorded an additional 10 hours of speech data, while each recorded one hour, resulting in 34 hours of speech material. To accommodate participants with varying cognitive levels, our text pool primarily consists of content from the AISHELL-1 dataset and speeches by primary and secondary school students. When participants read these texts, they must use a mobile device or the ZOOM F8n multi-track field recorder to record their speeches. In this paper, we elucidate the data collection and annotation processes and present an approach for establishing a baseline for dysarthric speech recognition. Furthermore, we conducted a speaker-dependent dysarthric speech recognition experiment using an additional 10 hours of speech data from one of our participants. Our research findings indicate that, through extensive data-driven model training, fine-tuning limited quantities of specific individual data yields commendable results in speaker-dependent dysarthric speech recognition. However, we observe significant variations in recognition results among different dysarthric speakers. These insights provide valuable reference points for speaker-dependent dysarthric speech recognition.