 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataParasite Enables Scalable and Repurposable Online Data Curation
Jan 05, 2026Many questions in computational social science rely on datasets assembled from heterogeneous online sources, a process that is often labor-intensive, costly, and difficult to reproduce. Recent advances in large language models enable agentic search and structured extraction from the web, but existing systems are frequently opaque, inflexible, or poorly suited to scientific data curation. Here we introduce DataParasite, an open-source, modular pipeline for scalable online data collection. DataParasite decomposes tabular curation tasks into independent, entity-level searches defined through lightweight configuration files and executed through a shared, task-agnostic python script. Crucially, the same pipeline can be repurposed to new tasks, including those without predefined entity lists, using only natural-language instructions. We evaluate the pipeline on multiple canonical tasks in computational social science, including faculty hiring histories, elite death events, and political career trajectories. Across tasks, DataParasite achieves high accuracy while reducing data-collection costs by an order of magnitude relative to manual curation. By lowering the technical and labor barriers to online data assembly, DataParasite provides a practical foundation for scalable, transparent, and reusable data curation in computational social science and beyond.
CDSD: Chinese Dysarthria Speech Database
Oct 24, 2023



We present the Chinese Dysarthria Speech Database (CDSD) as a valuable resource for dysarthria research. This database comprises speech data from 24 participants with dysarthria. Among these participants, one recorded an additional 10 hours of speech data, while each recorded one hour, resulting in 34 hours of speech material. To accommodate participants with varying cognitive levels, our text pool primarily consists of content from the AISHELL-1 dataset and speeches by primary and secondary school students. When participants read these texts, they must use a mobile device or the ZOOM F8n multi-track field recorder to record their speeches. In this paper, we elucidate the data collection and annotation processes and present an approach for establishing a baseline for dysarthric speech recognition. Furthermore, we conducted a speaker-dependent dysarthric speech recognition experiment using an additional 10 hours of speech data from one of our participants. Our research findings indicate that, through extensive data-driven model training, fine-tuning limited quantities of specific individual data yields commendable results in speaker-dependent dysarthric speech recognition. However, we observe significant variations in recognition results among different dysarthric speakers. These insights provide valuable reference points for speaker-dependent dysarthric speech recognition.
Team Power and Hierarchy: Understanding Team Success
Aug 09, 2021
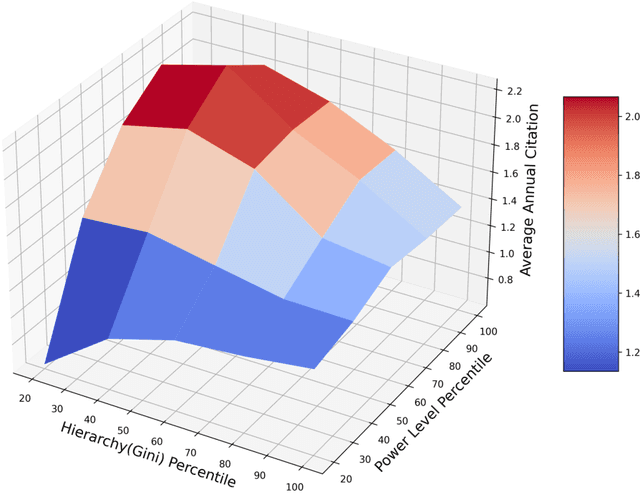

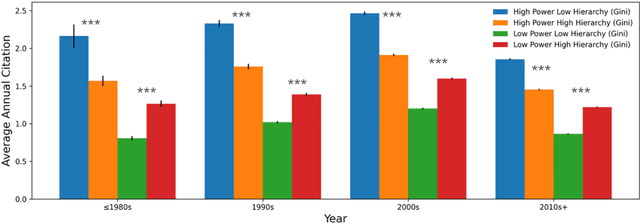
Teamwork is cooperative, participative and power sharing. In science of science, few studies have looked at the impact of team collaboration from the perspective of team power and hierarchy. This research examines in depth the relationships between team power and team success in the field of Computer Science (CS) using the DBLP dataset. Team power and hierarchy are measured using academic age and team success is quantified by citation. By analyzing 4,106,995 CS teams, we find that high power teams with flat structure have the best performance. On the contrary, low-power teams with hierarchical structure is a facilitator of team performance. These results are consistent across different time periods and team sizes.