 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference-Augmented Learning for Precise Tracking Policy of Tendon-Driven Continuum Robots
Apr 28, 2026Tendon-Driven Continuum Robots (TDCRs) pose significant control challenges due to their highly nonlinear, path-dependent dynamics and non-Markovian characteristics. Traditional Jacobian-based controllers often struggle with hysteresis-induced oscillations, while conventional learning-based approaches suffer from poor generalization to out-of-distribution trajectories. This paper proposes a reference-augmented offline learning framework for precise 6-DOF tracking control of TDCRs. By leveraging a differentiable RNN-based dynamics surrogate as a gradient bridge, we optimize a control policy through an augmented reference distribution. This multi-scale augmentation scheme incorporates stochastic bias, harmonic perturbations, and random walks, forcing the policy to internalize diverse tracking error recovery mechanisms without additional hardware interaction. Experimental results on a three-section TDCR platform demonstrate that the proposed policy achieves a 50.9\% reduction in average position error compared to non-augmented baselines and significantly outperforms Jacobian-based methods in both precision and stability across various speeds.
Learning-Based Dynamics Modeling and Robust Control for Tendon-Driven Continuum Robots
Apr 28, 2026Tendon-Driven Continuum Robots (TDCRs) pose significant modeling and control challenges due to complex nonlinearities, such as frictional hysteresis and transmission compliance. This paper proposes a differentiable learning framework that integrates high-fidelity dynamics modeling with robust neural control. We develop a GRU-based dynamics model featuring bidirectional multi-channel connectivity and residual prediction to effectively suppress compounding errors during long-horizon auto-regressive prediction. By treating this model as a gradient bridge, an end-to-end neural control policy is optimized through backpropagation, allowing it to implicitly internalize compensation for intricate nonlinearities. Experimental validation on a physical three-section TDCR demonstrates that our framework achieves accurate tracking and superior robustness against unseen payloads, outperforming Jacobian-based methods by eliminating self-excited oscillations.
Seeing to Act, Prompting to Specify: A Bayesian Factorization of Vision Language Action Policy
Dec 12, 2025The pursuit of out-of-distribution generalization in Vision-Language-Action (VLA) models is often hindered by catastrophic forgetting of the Vision-Language Model (VLM) backbone during fine-tuning. While co-training with external reasoning data helps, it requires experienced tuning and data-related overhead. Beyond such external dependencies, we identify an intrinsic cause within VLA datasets: modality imbalance, where language diversity is much lower than visual and action diversity. This imbalance biases the model toward visual shortcuts and language forgetting. To address this, we introduce BayesVLA, a Bayesian factorization that decomposes the policy into a visual-action prior, supporting seeing-to-act, and a language-conditioned likelihood, enabling prompt-to-specify. This inherently preserves generalization and promotes instruction following. We further incorporate pre- and post-contact phases to better leverage pre-trained foundation models. Information-theoretic analysis formally validates our effectiveness in mitigating shortcut learning. Extensive experiments show superior generalization to unseen instructions, objects, and environments compared to existing methods. Project page is available at: https://xukechun.github.io/papers/BayesVLA.
Compliance while resisting: a shear-thickening fluid controller for physical human-robot interaction
Feb 03, 2025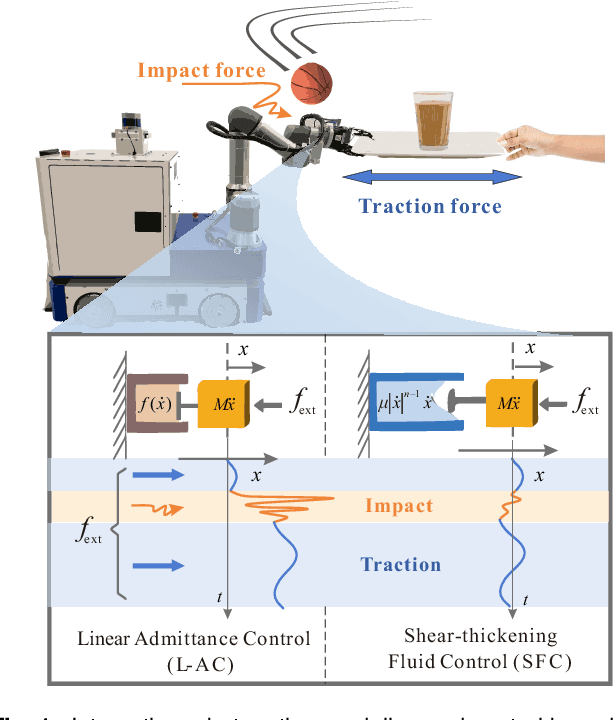


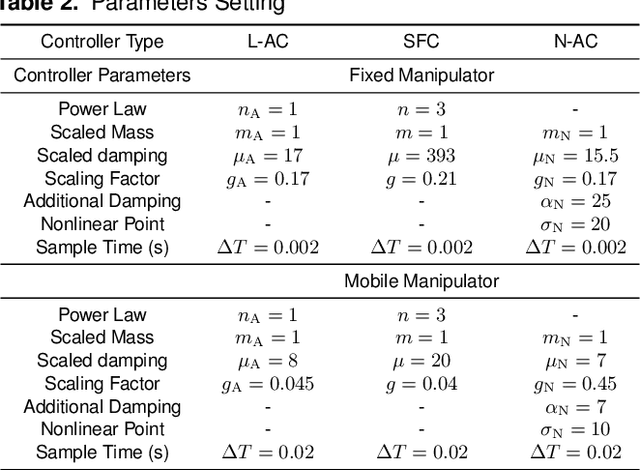
Physical human-robot interaction (pHRI) is widely needed in many fields, such as industrial manipulation, home services, and medical rehabilitation, and puts higher demands on the safety of robots. Due to the uncertainty of the working environment, the pHRI may receive unexpected impact interference, which affects the safety and smoothness of the task execution. The commonly used linear admittance control (L-AC) can cope well with high-frequency small-amplitude noise, but for medium-frequency high-intensity impact, the effect is not as good. Inspired by the solid-liquid phase change nature of shear-thickening fluid, we propose a Shear-thickening Fluid Control (SFC) that can achieve both an easy human-robot collaboration and resistance to impact interference. The SFC's stability, passivity, and phase trajectory are analyzed in detail, the frequency and time domain properties are quantified, and parameter constraints in discrete control and coupled stability conditions are provided. We conducted simulations to compare the frequency and time domain characteristics of L-AC, nonlinear admittance controller (N-AC), and SFC, and validated their dynamic properties. In real-world experiments, we compared the performance of L-AC, N-AC, and SFC in both fixed and mobile manipulators. L-AC exhibits weak resistance to impact. N-AC can resist moderate impacts but not high-intensity ones, and may exhibit self-excited oscillations. In contrast, SFC demonstrated superior impact resistance and maintained stable collaboration, enhancing comfort in cooperative water delivery tasks. Additionally, a case study was conducted in a factory setting, further affirming the SFC's capability in facilitating human-robot collaborative manipulation and underscoring its potential in industrial applications.
Revisit Mixture Models for Multi-Agent Simulation: Experimental Study within a Unified Framework
Jan 28, 2025



Simulation plays a crucial role in assessing autonomous driving systems, where the generation of realistic multi-agent behaviors is a key aspect. In multi-agent simulation, the primary challenges include behavioral multimodality and closed-loop distributional shifts. In this study, we revisit mixture models for generating multimodal agent behaviors, which can cover the mainstream methods including continuous mixture models and GPT-like discrete models. Furthermore, we introduce a closed-loop sample generation approach tailored for mixture models to mitigate distributional shifts. Within the unified mixture model~(UniMM) framework, we recognize critical configurations from both model and data perspectives. We conduct a systematic examination of various model configurations, including positive component matching, continuous regression, prediction horizon, and the number of components. Moreover, our investigation into the data configuration highlights the pivotal role of closed-loop samples in achieving realistic simulations. To extend the benefits of closed-loop samples across a broader range of mixture models, we further address the shortcut learning and off-policy learning issues. Leveraging insights from our exploration, the distinct variants proposed within the UniMM framework, including discrete, anchor-free, and anchor-based models, all achieve state-of-the-art performance on the WOSAC benchmark.
Leverage Cross-Attention for End-to-End Open-Vocabulary Panoptic Reconstruction
Jan 02, 2025



Open-vocabulary panoptic reconstruction offers comprehensive scene understanding, enabling advances in embodied robotics and photorealistic simulation. In this paper, we propose PanopticRecon++, an end-to-end method that formulates panoptic reconstruction through a novel cross-attention perspective. This perspective models the relationship between 3D instances (as queries) and the scene's 3D embedding field (as keys) through their attention map. Unlike existing methods that separate the optimization of queries and keys or overlook spatial proximity, PanopticRecon++ introduces learnable 3D Gaussians as instance queries. This formulation injects 3D spatial priors to preserve proximity while maintaining end-to-end optimizability. Moreover, this query formulation facilitates the alignment of 2D open-vocabulary instance IDs across frames by leveraging optimal linear assignment with instance masks rendered from the queries. Additionally, we ensure semantic-instance segmentation consistency by fusing query-based instance segmentation probabilities with semantic probabilities in a novel panoptic head supervised by a panoptic loss. During training, the number of instance query tokens dynamically adapts to match the number of objects. PanopticRecon++ shows competitive performance in terms of 3D and 2D segmentation and reconstruction performance on both simulation and real-world datasets, and demonstrates a user case as a robot simulator. Our project website is at: https://yuxuan1206.github.io/panopticrecon_pp/
RING#: PR-by-PE Global Localization with Roto-translation Equivariant Gram Learning
Aug 30, 2024



Global localization using onboard perception sensors, such as cameras and LiDARs, is crucial in autonomous driving and robotics applications when GPS signals are unreliable. Most approaches achieve global localization by sequential place recognition and pose estimation. Some of them train separate models for each task, while others employ a single model with dual heads, trained jointly with separate task-specific losses. However, the accuracy of localization heavily depends on the success of place recognition, which often fails in scenarios with significant changes in viewpoint or environmental appearance. Consequently, this renders the final pose estimation of localization ineffective. To address this, we propose a novel paradigm, PR-by-PE localization, which improves global localization accuracy by deriving place recognition directly from pose estimation. Our framework, RING#, is an end-to-end PR-by-PE localization network operating in the bird's-eye view (BEV) space, designed to support both vision and LiDAR sensors. It introduces a theoretical foundation for learning two equivariant representations from BEV features, which enables globally convergent and computationally efficient pose estimation. Comprehensive experiments on the NCLT and Oxford datasets across both vision and LiDAR modalities demonstrate that our method outperforms state-of-the-art approaches. Furthermore, we provide extensive analyses to confirm the effectiveness of our method. The code will be publicly released.
Pretraining-finetuning Framework for Efficient Co-design: A Case Study on Quadruped Robot Parkour
Jul 09, 2024

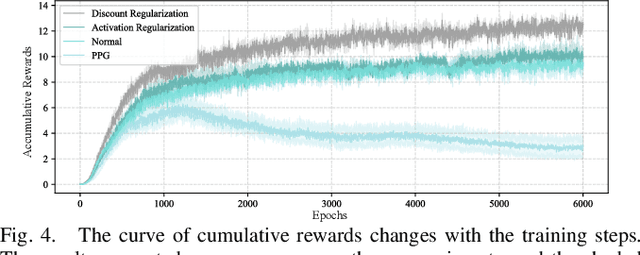
In nature, animals with exceptional locomotion abilities, such as cougars, often possess asymmetric fore and hind legs, with their powerful hind legs acting as reservoirs of energy for leaps. This observation inspired us: could optimize the leg length of quadruped robots endow them with similar locomotive capabilities? In this paper, we propose an approach that co-optimizes the mechanical structure and control policy to boost the locomotive prowess of quadruped robots. Specifically, we introduce a novel pretraining-finetuning framework, which not only guarantees optimal control strategies for each mechanical candidate but also ensures time efficiency. Additionally, we have devised an innovative training method for our pretraining network, integrating spatial domain randomization with regularization methods, markedly improving the network's generalizability. Our experimental results indicate that the proposed pretraining-finetuning framework significantly enhances the overall co-design performance with less time consumption. Moreover, the co-design strategy substantially exceeds the conventional method of independently optimizing control strategies, further improving the robot's locomotive performance and providing an innovative approach to enhancing the extreme parkour capabilities of quadruped robots.
GS-Planner: A Gaussian-Splatting-based Planning Framework for Active High-Fidelity Reconstruction
May 16, 2024Active reconstruction technique enables robots to autonomously collect scene data for full coverage, relieving users from tedious and time-consuming data capturing process. However, designed based on unsuitable scene representations, existing methods show unrealistic reconstruction results or the inability of online quality evaluation. Due to the recent advancements in explicit radiance field technology, online active high-fidelity reconstruction has become achievable. In this paper, we propose GS-Planner, a planning framework for active high-fidelity reconstruction using 3D Gaussian Splatting. With improvement on 3DGS to recognize unobserved regions, we evaluate the reconstruction quality and completeness of 3DGS map online to guide the robot. Then we design a sampling-based active reconstruction strategy to explore the unobserved areas and improve the reconstruction geometric and textural quality. To establish a complete robot active reconstruction system, we choose quadrotor as the robotic platform for its high agility. Then we devise a safety constraint with 3DGS to generate executable trajectories for quadrotor navigation in the 3DGS map. To validate the effectiveness of our method, we conduct extensive experiments and ablation studies in highly realistic simulation scenes.
Grasp, See and Place: Efficient Unknown Object Rearrangement with Policy Structure Prior
Feb 23, 2024



We focus on the task of unknown object rearrangement, where a robot is supposed to re-configure the objects into a desired goal configuration specified by an RGB-D image. Recent works explore unknown object rearrangement systems by incorporating learning-based perception modules. However, they are sensitive to perception error, and pay less attention to task-level performance. In this paper, we aim to develop an effective system for unknown object rearrangement amidst perception noise. We theoretically reveal the noisy perception impacts grasp and place in a decoupled way, and show such a decoupled structure is non-trivial to improve task optimality. We propose GSP, a dual-loop system with the decoupled structure as prior. For the inner loop, we learn an active seeing policy for self-confident object matching to improve the perception of place. For the outer loop, we learn a grasp policy aware of object matching and grasp capability guided by task-level rewards. We leverage the foundation model CLIP for object matching, policy learning and self-termination. A series of experiments indicate that GSP can conduct unknown object rearrangement with higher completion rate and less steps.