 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorkstreamBench: Evaluating LLM Agents on End-to-End Spreadsheet Tasks in Finance
May 21, 2026LLM agents are increasingly expected to carry out end-to-end workflows, producing complete artifacts from high-level user instructions. To meet enterprise needs, frontier AI labs have developed agents that can construct entire spreadsheets from scratch. This is especially relevant in finance, where core workflows such as financial modeling, forecasting, and scenario analysis are commonly conducted through spreadsheets. Yet, existing spreadsheet benchmarks do not measure this advanced capability, focusing instead on question-answering or single-formula edits. To address this gap, we provide one of the first evaluations of agents on end-to-end spreadsheet tasks, focusing on economically critical financial workflows such as modeling and scenario analysis. Since deliverables therein are routinely reviewed and revised by multiple stakeholders, judging their quality necessarily involves high-level criteria such as readability or ease of modification. To reflect the multidimensional nature of solution quality, we develop an evaluation taxonomy comprising three dimensions: Accuracy, Formula, and Format, each comprising fine-grained criteria that reflect professional standards. The Claude family leads the benchmark and produces the most professional-looking outputs in our qualitative review, but even the strongest agents frequently fall short of professional finance standards and degrade sharply as the difficulty increases beyond a few chained calculations. This suggests that current agents are not yet able to reliably produce professional-quality spreadsheets at the level of complexity real-world workflows demand.
Leverage Cross-Attention for End-to-End Open-Vocabulary Panoptic Reconstruction
Jan 02, 2025



Open-vocabulary panoptic reconstruction offers comprehensive scene understanding, enabling advances in embodied robotics and photorealistic simulation. In this paper, we propose PanopticRecon++, an end-to-end method that formulates panoptic reconstruction through a novel cross-attention perspective. This perspective models the relationship between 3D instances (as queries) and the scene's 3D embedding field (as keys) through their attention map. Unlike existing methods that separate the optimization of queries and keys or overlook spatial proximity, PanopticRecon++ introduces learnable 3D Gaussians as instance queries. This formulation injects 3D spatial priors to preserve proximity while maintaining end-to-end optimizability. Moreover, this query formulation facilitates the alignment of 2D open-vocabulary instance IDs across frames by leveraging optimal linear assignment with instance masks rendered from the queries. Additionally, we ensure semantic-instance segmentation consistency by fusing query-based instance segmentation probabilities with semantic probabilities in a novel panoptic head supervised by a panoptic loss. During training, the number of instance query tokens dynamically adapts to match the number of objects. PanopticRecon++ shows competitive performance in terms of 3D and 2D segmentation and reconstruction performance on both simulation and real-world datasets, and demonstrates a user case as a robot simulator. Our project website is at: https://yuxuan1206.github.io/panopticrecon_pp/
Scale Disparity of Instances in Interactive Point Cloud Segmentation
Jul 19, 2024



Interactive point cloud segmentation has become a pivotal task for understanding 3D scenes, enabling users to guide segmentation models with simple interactions such as clicks, therefore significantly reducing the effort required to tailor models to diverse scenarios and new categories. However, in the realm of interactive segmentation, the meaning of instance diverges from that in instance segmentation, because users might desire to segment instances of both thing and stuff categories that vary greatly in scale. Existing methods have focused on thing categories, neglecting the segmentation of stuff categories and the difficulties arising from scale disparity. To bridge this gap, we propose ClickFormer, an innovative interactive point cloud segmentation model that accurately segments instances of both thing and stuff categories. We propose a query augmentation module to augment click queries by a global query sampling strategy, thus maintaining consistent performance across different instance scales. Additionally, we employ global attention in the query-voxel transformer to mitigate the risk of generating false positives, along with several other network structure improvements to further enhance the model's segmentation performance. Experiments demonstrate that ClickFormer outperforms existing interactive point cloud segmentation methods across both indoor and outdoor datasets, providing more accurate segmentation results with fewer user clicks in an open-world setting.
Let Occ Flow: Self-Supervised 3D Occupancy Flow Prediction
Jul 10, 2024



Accurate perception of the dynamic environment is a fundamental task for autonomous driving and robot systems. This paper introduces Let Occ Flow, the first self-supervised work for joint 3D occupancy and occupancy flow prediction using only camera inputs, eliminating the need for 3D annotations. Utilizing TPV for unified scene representation and deformable attention layers for feature aggregation, our approach incorporates a backward-forward temporal attention module to capture dynamic object dependencies, followed by a 3D refine module for fine-gained volumetric representation. Besides, our method extends differentiable rendering to 3D volumetric flow fields, leveraging zero-shot 2D segmentation and optical flow cues for dynamic decomposition and motion optimization. Extensive experiments on nuScenes and KITTI datasets demonstrate the competitive performance of our approach over prior state-of-the-art methods.
PanopticRecon: Leverage Open-vocabulary Instance Segmentation for Zero-shot Panoptic Reconstruction
Jul 01, 2024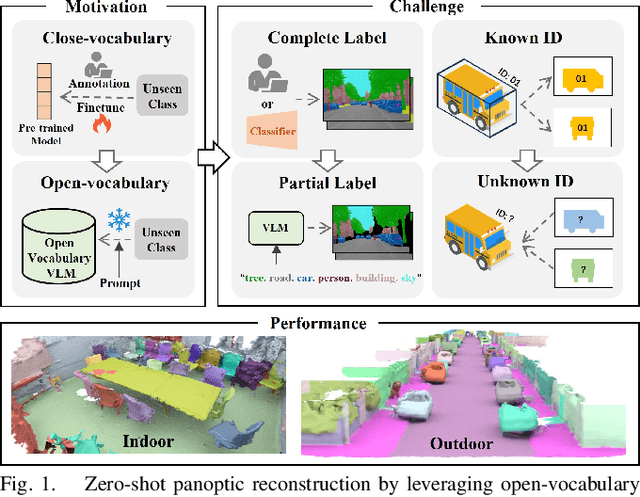
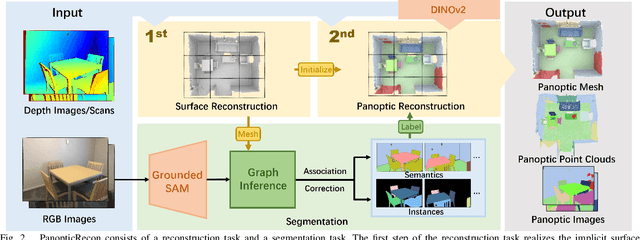
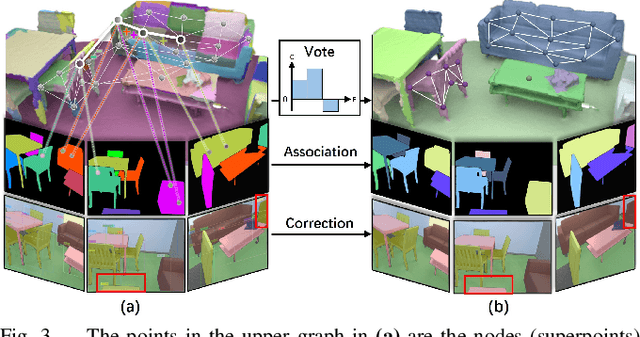
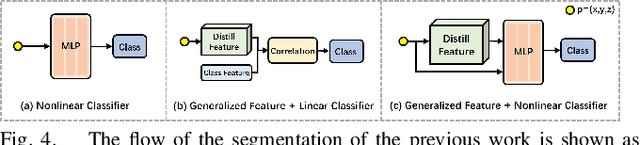
Panoptic reconstruction is a challenging task in 3D scene understanding. However, most existing methods heavily rely on pre-trained semantic segmentation models and known 3D object bounding boxes for 3D panoptic segmentation, which is not available for in-the-wild scenes. In this paper, we propose a novel zero-shot panoptic reconstruction method from RGB-D images of scenes. For zero-shot segmentation, we leverage open-vocabulary instance segmentation, but it has to face partial labeling and instance association challenges. We tackle both challenges by propagating partial labels with the aid of dense generalized features and building a 3D instance graph for associating 2D instance IDs. Specifically, we exploit partial labels to learn a classifier for generalized semantic features to provide complete labels for scenes with dense distilled features. Moreover, we formulate instance association as a 3D instance graph segmentation problem, allowing us to fully utilize the scene geometry prior and all 2D instance masks to infer global unique pseudo 3D instance ID. Our method outperforms state-of-the-art methods on the indoor dataset ScanNet V2 and the outdoor dataset KITTI-360, demonstrating the effectiveness of our graph segmentation method and reconstruction network.
NF-Atlas: Multi-Volume Neural Feature Fields for Large Scale LiDAR Mapping
Apr 10, 2023LiDAR Mapping has been a long-standing problem in robotics. Recent progress in neural implicit representation has brought new opportunities to robotic mapping. In this paper, we propose the multi-volume neural feature fields, called NF-Atlas, which bridge the neural feature volumes with pose graph optimization. By regarding the neural feature volume as pose graph nodes and the relative pose between volumes as pose graph edges, the entire neural feature field becomes both locally rigid and globally elastic. Locally, the neural feature volume employs a sparse feature Octree and a small MLP to encode the submap SDF with an option of semantics. Learning the map using this structure allows for end-to-end solving of maximum a posteriori (MAP) based probabilistic mapping. Globally, the map is built volume by volume independently, avoiding catastrophic forgetting when mapping incrementally. Furthermore, when a loop closure occurs, with the elastic pose graph based representation, only updating the origin of neural volumes is required without remapping. Finally, these functionalities of NF-Atlas are validated. Thanks to the sparsity and the optimization based formulation, NF-Atlas shows competitive performance in terms of accuracy, efficiency and memory usage on both simulation and real-world datasets.