 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale Disparity of Instances in Interactive Point Cloud Segmentation
Jul 19, 2024



Interactive point cloud segmentation has become a pivotal task for understanding 3D scenes, enabling users to guide segmentation models with simple interactions such as clicks, therefore significantly reducing the effort required to tailor models to diverse scenarios and new categories. However, in the realm of interactive segmentation, the meaning of instance diverges from that in instance segmentation, because users might desire to segment instances of both thing and stuff categories that vary greatly in scale. Existing methods have focused on thing categories, neglecting the segmentation of stuff categories and the difficulties arising from scale disparity. To bridge this gap, we propose ClickFormer, an innovative interactive point cloud segmentation model that accurately segments instances of both thing and stuff categories. We propose a query augmentation module to augment click queries by a global query sampling strategy, thus maintaining consistent performance across different instance scales. Additionally, we employ global attention in the query-voxel transformer to mitigate the risk of generating false positives, along with several other network structure improvements to further enhance the model's segmentation performance. Experiments demonstrate that ClickFormer outperforms existing interactive point cloud segmentation methods across both indoor and outdoor datasets, providing more accurate segmentation results with fewer user clicks in an open-world setting.
Let Occ Flow: Self-Supervised 3D Occupancy Flow Prediction
Jul 10, 2024



Accurate perception of the dynamic environment is a fundamental task for autonomous driving and robot systems. This paper introduces Let Occ Flow, the first self-supervised work for joint 3D occupancy and occupancy flow prediction using only camera inputs, eliminating the need for 3D annotations. Utilizing TPV for unified scene representation and deformable attention layers for feature aggregation, our approach incorporates a backward-forward temporal attention module to capture dynamic object dependencies, followed by a 3D refine module for fine-gained volumetric representation. Besides, our method extends differentiable rendering to 3D volumetric flow fields, leveraging zero-shot 2D segmentation and optical flow cues for dynamic decomposition and motion optimization. Extensive experiments on nuScenes and KITTI datasets demonstrate the competitive performance of our approach over prior state-of-the-art methods.
PanopticRecon: Leverage Open-vocabulary Instance Segmentation for Zero-shot Panoptic Reconstruction
Jul 01, 2024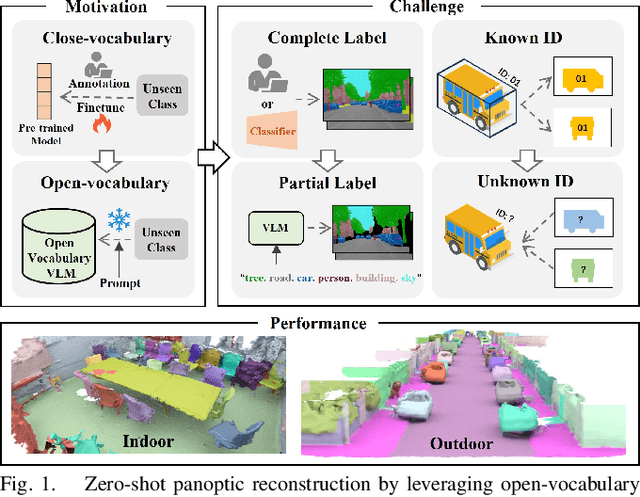
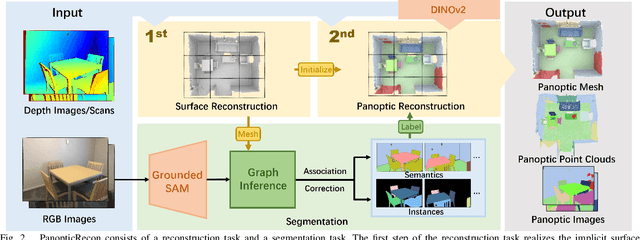
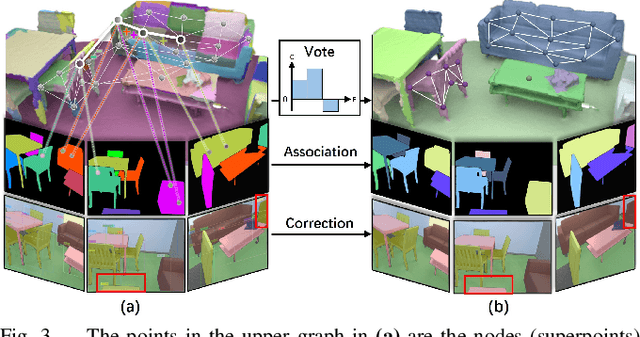
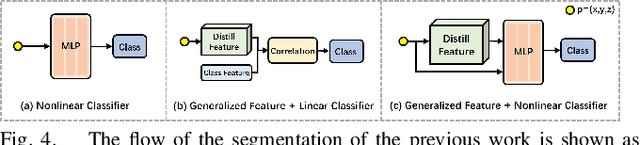
Panoptic reconstruction is a challenging task in 3D scene understanding. However, most existing methods heavily rely on pre-trained semantic segmentation models and known 3D object bounding boxes for 3D panoptic segmentation, which is not available for in-the-wild scenes. In this paper, we propose a novel zero-shot panoptic reconstruction method from RGB-D images of scenes. For zero-shot segmentation, we leverage open-vocabulary instance segmentation, but it has to face partial labeling and instance association challenges. We tackle both challenges by propagating partial labels with the aid of dense generalized features and building a 3D instance graph for associating 2D instance IDs. Specifically, we exploit partial labels to learn a classifier for generalized semantic features to provide complete labels for scenes with dense distilled features. Moreover, we formulate instance association as a 3D instance graph segmentation problem, allowing us to fully utilize the scene geometry prior and all 2D instance masks to infer global unique pseudo 3D instance ID. Our method outperforms state-of-the-art methods on the indoor dataset ScanNet V2 and the outdoor dataset KITTI-360, demonstrating the effectiveness of our graph segmentation method and reconstruction network.