 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysiFlow: Physics-Aware Humanoid Whole-Body VLA via Multi-Brain Latent Flow Matching and Robust Tracking
Mar 05, 2026In the domain of humanoid robot control, the fusion of Vision-Language-Action (VLA) with whole-body control is essential for semantically guided execution of real-world tasks. However, existing methods encounter challenges in terms of low VLA inference efficiency or an absence of effective semantic guidance for whole-body control, resulting in instability in dynamic limb-coordinated tasks. To bridge this gap, we present a semantic-motion intent guided, physics-aware multi-brain VLA framework for humanoid whole-body control. A series of experiments was conducted to evaluate the performance of the proposed framework. The experimental results demonstrated that the framework enabled reliable vision-language-guided full-body coordination for humanoid robots.
Pretraining-finetuning Framework for Efficient Co-design: A Case Study on Quadruped Robot Parkour
Jul 09, 2024
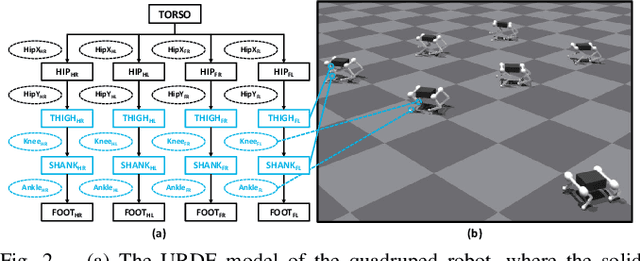

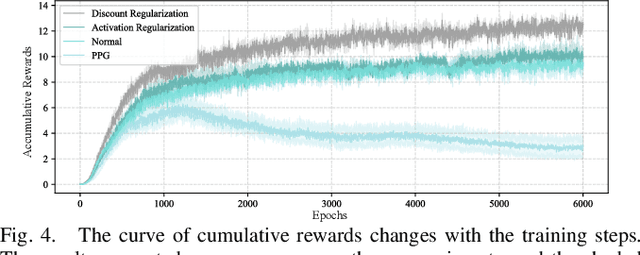
In nature, animals with exceptional locomotion abilities, such as cougars, often possess asymmetric fore and hind legs, with their powerful hind legs acting as reservoirs of energy for leaps. This observation inspired us: could optimize the leg length of quadruped robots endow them with similar locomotive capabilities? In this paper, we propose an approach that co-optimizes the mechanical structure and control policy to boost the locomotive prowess of quadruped robots. Specifically, we introduce a novel pretraining-finetuning framework, which not only guarantees optimal control strategies for each mechanical candidate but also ensures time efficiency. Additionally, we have devised an innovative training method for our pretraining network, integrating spatial domain randomization with regularization methods, markedly improving the network's generalizability. Our experimental results indicate that the proposed pretraining-finetuning framework significantly enhances the overall co-design performance with less time consumption. Moreover, the co-design strategy substantially exceeds the conventional method of independently optimizing control strategies, further improving the robot's locomotive performance and providing an innovative approach to enhancing the extreme parkour capabilities of quadruped robots.
Failure-aware Policy Learning for Self-assessable Robotics Tasks
Feb 25, 2023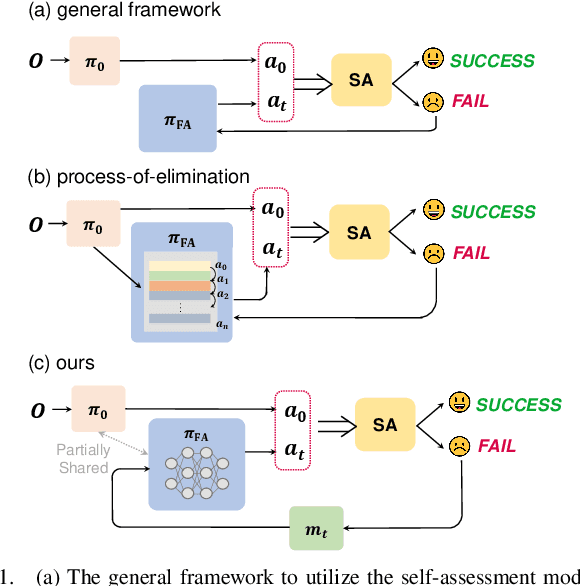
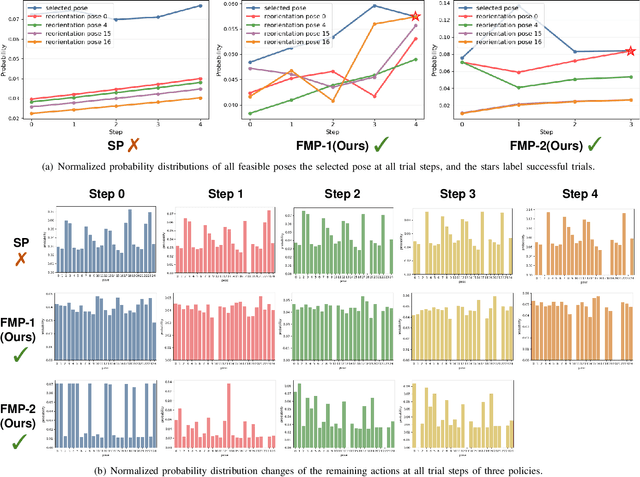
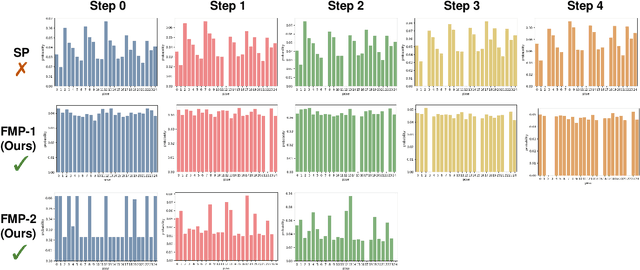
Self-assessment rules play an essential role in safe and effective real-world robotic applications, which verify the feasibility of the selected action before actual execution. But how to utilize the self-assessment results to re-choose actions remains a challenge. Previous methods eliminate the selected action evaluated as failed by the self-assessment rules, and re-choose one with the next-highest affordance~(i.e. process-of-elimination strategy [1]), which ignores the dependency between the self-assessment results and the remaining untried actions. However, this dependency is important since the previous failures might help trim the remaining over-estimated actions. In this paper, we set to investigate this dependency by learning a failure-aware policy. We propose two architectures for the failure-aware policy by representing the self-assessment results of previous failures as the variable state, and leveraging recurrent neural networks to implicitly memorize the previous failures. Experiments conducted on three tasks demonstrate that our method can achieve better performances with higher task success rates by less trials. Moreover, when the actions are correlated, learning a failure-aware policy can achieve better performance than the process-of-elimination strategy.
C^2:Co-design of Robots via Concurrent Networks Coupling Online and Offline Reinforcement Learning
Sep 14, 2022



With the rise of computing power, using data-driven approaches for co-designing robots' morphology and controller has become a feasible way. Nevertheless, evaluating the fitness of the controller under each morphology is time-consuming. As a pioneering data-driven method, Co-adaptation utilizes a double-network mechanism with the aim of learning a Q function conditioned on morphology parameters to replace the traditional evaluation of a diverse set of candidates, thereby speeding up optimization. In this paper, we find that Co-adaptation ignores the existence of exploration error during training and state-action distribution shift during parameter transmitting, which hurt the performance. We propose the framework of the concurrent network that couples online and offline RL methods. By leveraging the behavior cloning term flexibly, we mitigate the impact of the above issues on the results. Simulation and physical experiments are performed to demonstrate that our proposed method outperforms baseline algorithms, which illustrates that the proposed method is an effective way of discovering the optimal combination of morphology and controller.
Motion Planning for Heterogeneous Unmanned Systems under Partial Observation from UAV
Jul 28, 2020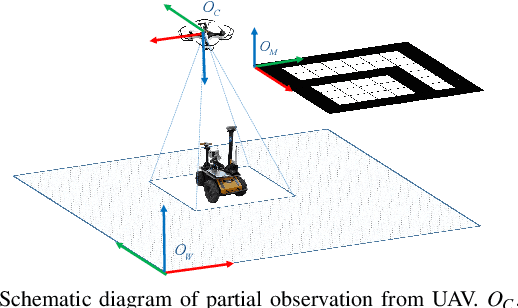
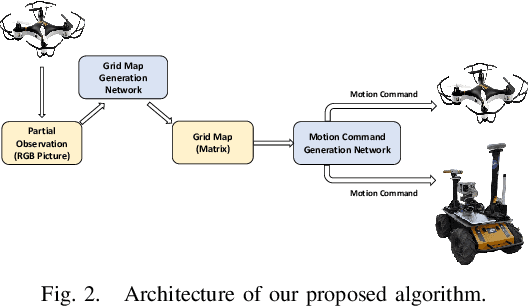
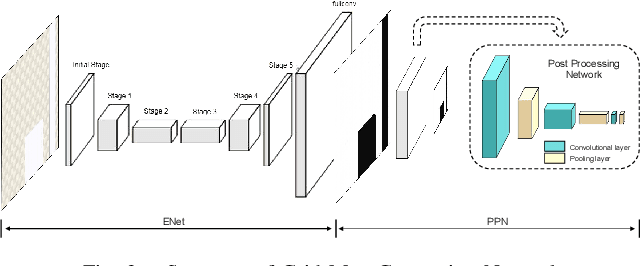
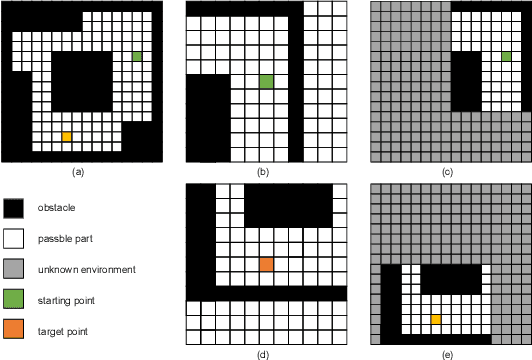
For heterogeneous unmanned systems composed of unmanned aerial vehicles (UAVs) and unmanned ground vehicles (UGVs), using UAVs serve as eyes to assist UGVs in motion planning is a promising research direction due to the UAVs' vast view scope. However, due to UAVs flight altitude limitations, it may be impossible to observe the global map, and motion planning in the local map is a POMDP (Partially Observable Markov Decision Process) problem. This paper proposes a motion planning algorithm for heterogeneous unmanned system under partial observation from UAV without reconstruction of global maps, which consists of two parts designed for perception and decision-making, respectively. For the perception part, we propose the Grid Map Generation Network (GMGN), which is used to perceive scenes from UAV's perspective and classify the pathways and obstacles. For the decision-making part, we propose the Motion Command Generation Network (MCGN). Due to the addition of memory mechanism, MCGN has planning and reasoning abilities under partial observation from UAVs. We evaluate our proposed algorithm by comparing with baseline algorithms. The results show that our method effectively plans the motion of heterogeneous unmanned systems and achieves a relatively high success rate.