 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerpetualWonder: Long-Horizon Action-Conditioned 4D Scene Generation
Feb 04, 2026We introduce PerpetualWonder, a hybrid generative simulator that enables long-horizon, action-conditioned 4D scene generation from a single image. Current works fail at this task because their physical state is decoupled from their visual representation, which prevents generative refinements to update the underlying physics for subsequent interactions. PerpetualWonder solves this by introducing the first true closed-loop system. It features a novel unified representation that creates a bidirectional link between the physical state and visual primitives, allowing generative refinements to correct both the dynamics and appearance. It also introduces a robust update mechanism that gathers supervision from multiple viewpoints to resolve optimization ambiguity. Experiments demonstrate that from a single image, PerpetualWonder can successfully simulate complex, multi-step interactions from long-horizon actions, maintaining physical plausibility and visual consistency.
ART: Articulated Reconstruction Transformer
Dec 16, 2025We introduce ART, Articulated Reconstruction Transformer -- a category-agnostic, feed-forward model that reconstructs complete 3D articulated objects from only sparse, multi-state RGB images. Previous methods for articulated object reconstruction either rely on slow optimization with fragile cross-state correspondences or use feed-forward models limited to specific object categories. In contrast, ART treats articulated objects as assemblies of rigid parts, formulating reconstruction as part-based prediction. Our newly designed transformer architecture maps sparse image inputs to a set of learnable part slots, from which ART jointly decodes unified representations for individual parts, including their 3D geometry, texture, and explicit articulation parameters. The resulting reconstructions are physically interpretable and readily exportable for simulation. Trained on a large-scale, diverse dataset with per-part supervision, and evaluated across diverse benchmarks, ART achieves significant improvements over existing baselines and establishes a new state of the art for articulated object reconstruction from image inputs.
Product of Experts for Visual Generation
Jun 10, 2025Modern neural models capture rich priors and have complementary knowledge over shared data domains, e.g., images and videos. Integrating diverse knowledge from multiple sources -- including visual generative models, visual language models, and sources with human-crafted knowledge such as graphics engines and physics simulators -- remains under-explored. We propose a Product of Experts (PoE) framework that performs inference-time knowledge composition from heterogeneous models. This training-free approach samples from the product distribution across experts via Annealed Importance Sampling (AIS). Our framework shows practical benefits in image and video synthesis tasks, yielding better controllability than monolithic methods and additionally providing flexible user interfaces for specifying visual generation goals.
WonderPlay: Dynamic 3D Scene Generation from a Single Image and Actions
May 23, 2025WonderPlay is a novel framework integrating physics simulation with video generation for generating action-conditioned dynamic 3D scenes from a single image. While prior works are restricted to rigid body or simple elastic dynamics, WonderPlay features a hybrid generative simulator to synthesize a wide range of 3D dynamics. The hybrid generative simulator first uses a physics solver to simulate coarse 3D dynamics, which subsequently conditions a video generator to produce a video with finer, more realistic motion. The generated video is then used to update the simulated dynamic 3D scene, closing the loop between the physics solver and the video generator. This approach enables intuitive user control to be combined with the accurate dynamics of physics-based simulators and the expressivity of diffusion-based video generators. Experimental results demonstrate that WonderPlay enables users to interact with various scenes of diverse content, including cloth, sand, snow, liquid, smoke, elastic, and rigid bodies -- all using a single image input. Code will be made public. Project website: https://kyleleey.github.io/WonderPlay/
The Scene Language: Representing Scenes with Programs, Words, and Embeddings
Oct 22, 2024We introduce the Scene Language, a visual scene representation that concisely and precisely describes the structure, semantics, and identity of visual scenes. It represents a scene with three key components: a program that specifies the hierarchical and relational structure of entities in the scene, words in natural language that summarize the semantic class of each entity, and embeddings that capture the visual identity of each entity. This representation can be inferred from pre-trained language models via a training-free inference technique, given text or image inputs. The resulting scene can be rendered into images using traditional, neural, or hybrid graphics renderers. Together, this forms a robust, automated system for high-quality 3D and 4D scene generation. Compared with existing representations like scene graphs, our proposed Scene Language generates complex scenes with higher fidelity, while explicitly modeling the scene structures to enable precise control and editing.
3D Congealing: 3D-Aware Image Alignment in the Wild
Apr 02, 2024



We propose 3D Congealing, a novel problem of 3D-aware alignment for 2D images capturing semantically similar objects. Given a collection of unlabeled Internet images, our goal is to associate the shared semantic parts from the inputs and aggregate the knowledge from 2D images to a shared 3D canonical space. We introduce a general framework that tackles the task without assuming shape templates, poses, or any camera parameters. At its core is a canonical 3D representation that encapsulates geometric and semantic information. The framework optimizes for the canonical representation together with the pose for each input image, and a per-image coordinate map that warps 2D pixel coordinates to the 3D canonical frame to account for the shape matching. The optimization procedure fuses prior knowledge from a pre-trained image generative model and semantic information from input images. The former provides strong knowledge guidance for this under-constraint task, while the latter provides the necessary information to mitigate the training data bias from the pre-trained model. Our framework can be used for various tasks such as correspondence matching, pose estimation, and image editing, achieving strong results on real-world image datasets under challenging illumination conditions and on in-the-wild online image collections.
Learning the 3D Fauna of the Web
Jan 04, 2024Learning 3D models of all animals on the Earth requires massively scaling up existing solutions. With this ultimate goal in mind, we develop 3D-Fauna, an approach that learns a pan-category deformable 3D animal model for more than 100 animal species jointly. One crucial bottleneck of modeling animals is the limited availability of training data, which we overcome by simply learning from 2D Internet images. We show that prior category-specific attempts fail to generalize to rare species with limited training images. We address this challenge by introducing the Semantic Bank of Skinned Models (SBSM), which automatically discovers a small set of base animal shapes by combining geometric inductive priors with semantic knowledge implicitly captured by an off-the-shelf self-supervised feature extractor. To train such a model, we also contribute a new large-scale dataset of diverse animal species. At inference time, given a single image of any quadruped animal, our model reconstructs an articulated 3D mesh in a feed-forward fashion within seconds.
ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Real Image
Oct 27, 2023

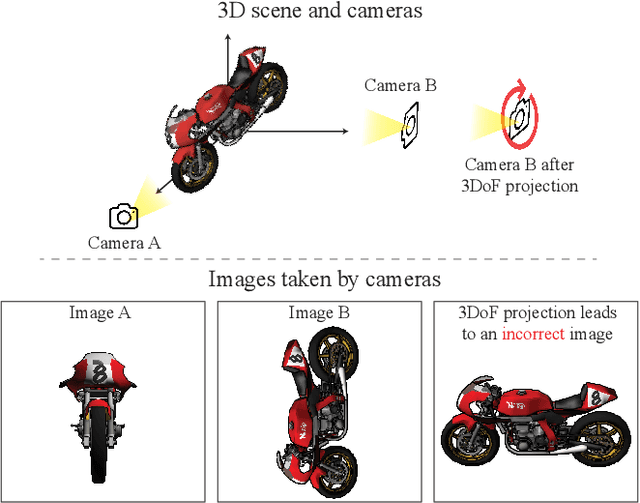

We introduce a 3D-aware diffusion model, ZeroNVS, for single-image novel view synthesis for in-the-wild scenes. While existing methods are designed for single objects with masked backgrounds, we propose new techniques to address challenges introduced by in-the-wild multi-object scenes with complex backgrounds. Specifically, we train a generative prior on a mixture of data sources that capture object-centric, indoor, and outdoor scenes. To address issues from data mixture such as depth-scale ambiguity, we propose a novel camera conditioning parameterization and normalization scheme. Further, we observe that Score Distillation Sampling (SDS) tends to truncate the distribution of complex backgrounds during distillation of 360-degree scenes, and propose "SDS anchoring" to improve the diversity of synthesized novel views. Our model sets a new state-of-the-art result in LPIPS on the DTU dataset in the zero-shot setting, even outperforming methods specifically trained on DTU. We further adapt the challenging Mip-NeRF 360 dataset as a new benchmark for single-image novel view synthesis, and demonstrate strong performance in this setting. Our code and data are at http://kylesargent.github.io/zeronvs/
Learning a Room with the Occ-SDF Hybrid: Signed Distance Function Mingled with Occupancy Aids Scene Representation
Mar 16, 2023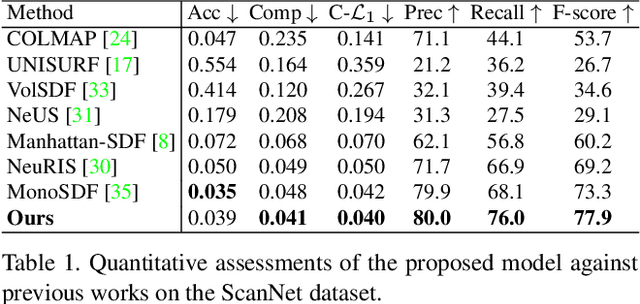
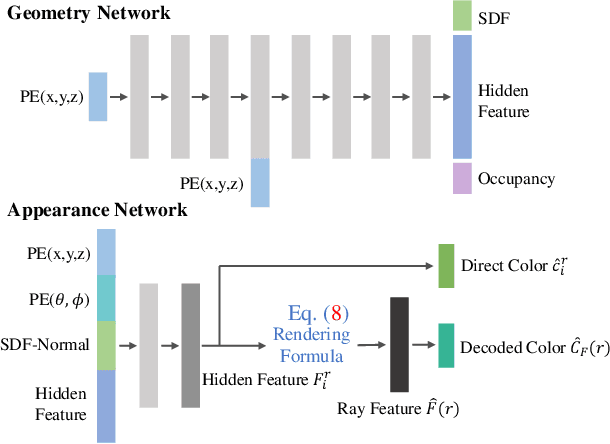
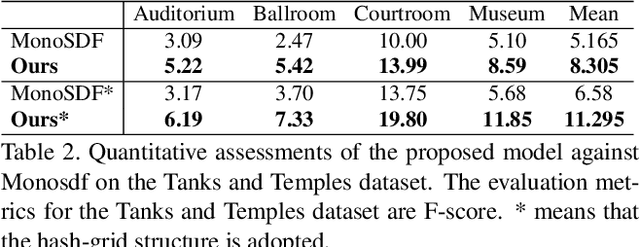

Implicit neural rendering, which uses signed distance function (SDF) representation with geometric priors (such as depth or surface normal), has led to impressive progress in the surface reconstruction of large-scale scenes. However, applying this method to reconstruct a room-level scene from images may miss structures in low-intensity areas or small and thin objects. We conducted experiments on three datasets to identify limitations of the original color rendering loss and priors-embedded SDF scene representation. We found that the color rendering loss results in optimization bias against low-intensity areas, causing gradient vanishing and leaving these areas unoptimized. To address this issue, we propose a feature-based color rendering loss that utilizes non-zero feature values to bring back optimization signals. Additionally, the SDF representation can be influenced by objects along a ray path, disrupting the monotonic change of SDF values when a single object is present. To counteract this, we explore using the occupancy representation, which encodes each point separately and is unaffected by objects along a querying ray. Our experimental results demonstrate that the joint forces of the feature-based rendering loss and Occ-SDF hybrid representation scheme can provide high-quality reconstruction results, especially in challenging room-level scenarios. The code would be released.
RICO: Regularizing the Unobservable for Indoor Compositional Reconstruction
Mar 15, 2023



Recently, neural implicit surfaces have become popular for multi-view reconstruction. To facilitate practical applications like scene editing and manipulation, some works extend the framework with semantic masks input for the object-compositional reconstruction rather than the holistic perspective. Though achieving plausible disentanglement, the performance drops significantly when processing the indoor scenes where objects are usually partially observed. We propose RICO to address this by regularizing the unobservable regions for indoor compositional reconstruction. Our key idea is to first regularize the smoothness of the occluded background, which then in turn guides the foreground object reconstruction in unobservable regions based on the object-background relationship. Particularly, we regularize the geometry smoothness of occluded background patches. With the improved background surface, the signed distance function and the reversedly rendered depth of objects can be optimized to bound them within the background range. Extensive experiments show our method outperforms other methods on synthetic and real-world indoor scenes and prove the effectiveness of proposed regularizations.