 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Differentiable and Interpretable Model for VIO with 4 Trainable Parameters
Paper and Code
Sep 25, 2021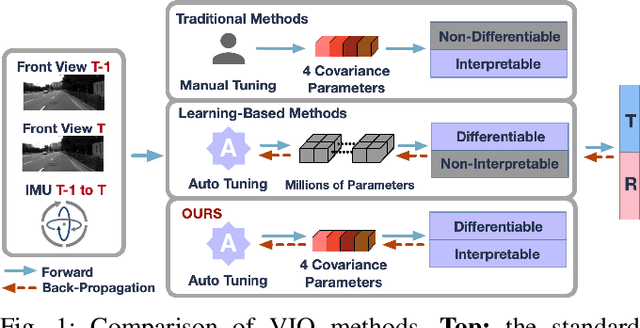
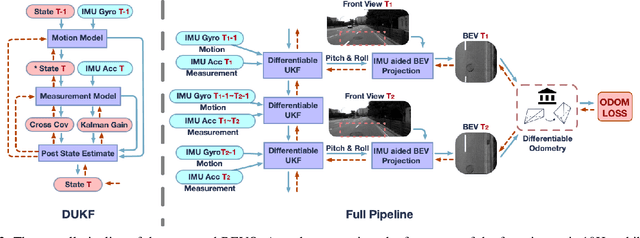
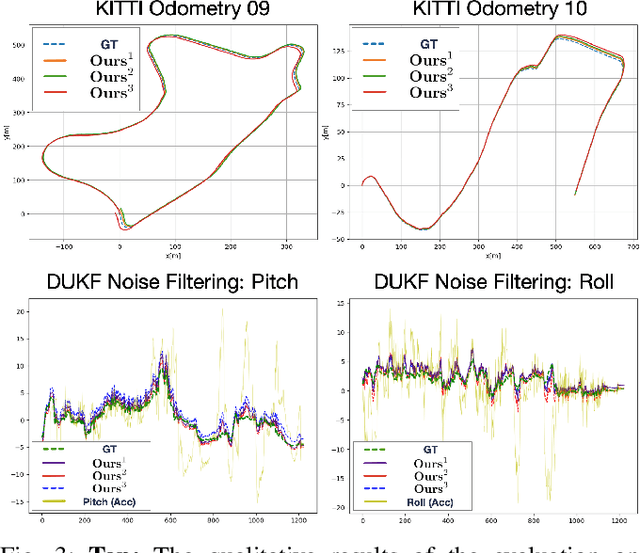
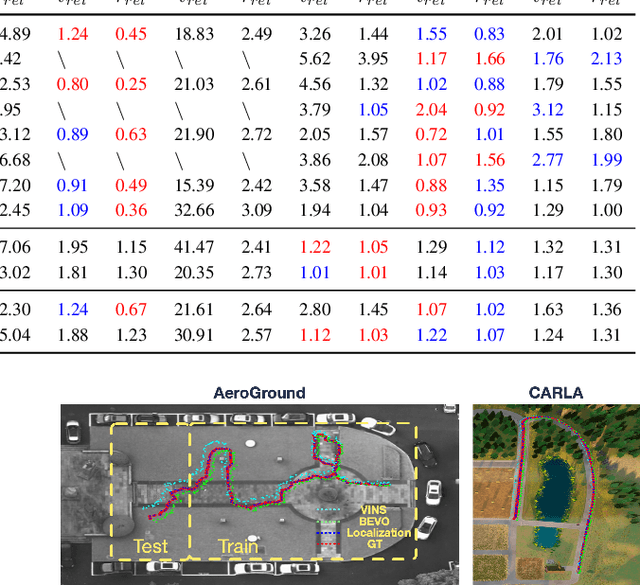
Monocular visual-inertial odometry (VIO) is a critical problem in robotics and autonomous driving. Traditional methods solve this problem based on filtering or optimization. While being fully interpretable, they rely on manual interference and empirical parameter tuning. On the other hand, learning-based approaches allow for end-to-end training but require a large number of training data to learn millions of parameters. However, the non-interpretable and heavy models hinder the generalization ability. In this paper, we propose a fully differentiable, interpretable, and lightweight monocular VIO model that contains only 4 trainable parameters. Specifically, we first adopt Unscented Kalman Filter as a differentiable layer to predict the pitch and roll, where the covariance matrices of noise are learned to filter out the noise of the IMU raw data. Second, the refined pitch and roll are adopted to retrieve a gravity-aligned BEV image of each frame using differentiable camera projection. Finally, a differentiable pose estimator is utilized to estimate the remaining 4 DoF poses between the BEV frames. Our method allows for learning the covariance matrices end-to-end supervised by the pose estimation loss, demonstrating superior performance to empirical baselines. Experimental results on synthetic and real-world datasets demonstrate that our simple approach is competitive with state-of-the-art methods and generalizes well on unseen scenes.