 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveAgent-R1: Advancing VLM-based Autonomous Driving with Hybrid Thinking and Active Perception
Jul 28, 2025Vision-Language Models (VLMs) are advancing autonomous driving, yet their potential is constrained by myopic decision-making and passive perception, limiting reliability in complex environments. We introduce DriveAgent-R1 to tackle these challenges in long-horizon, high-level behavioral decision-making. DriveAgent-R1 features two core innovations: a Hybrid-Thinking framework that adaptively switches between efficient text-based and in-depth tool-based reasoning, and an Active Perception mechanism with a vision toolkit to proactively resolve uncertainties, thereby balancing decision-making efficiency and reliability. The agent is trained using a novel, three-stage progressive reinforcement learning strategy designed to master these hybrid capabilities. Extensive experiments demonstrate that DriveAgent-R1 achieves state-of-the-art performance, outperforming even leading proprietary large multimodal models, such as Claude Sonnet 4. Ablation studies validate our approach and confirm that the agent's decisions are robustly grounded in actively perceived visual evidence, paving a path toward safer and more intelligent autonomous systems.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024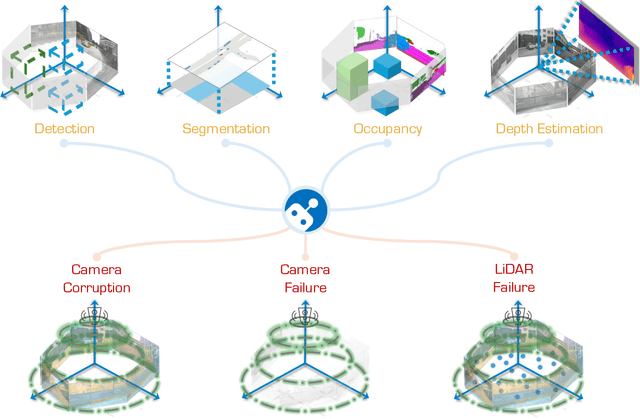


In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
ModaLink: Unifying Modalities for Efficient Image-to-PointCloud Place Recognition
Mar 27, 2024



Place recognition is an important task for robots and autonomous cars to localize themselves and close loops in pre-built maps. While single-modal sensor-based methods have shown satisfactory performance, cross-modal place recognition that retrieving images from a point-cloud database remains a challenging problem. Current cross-modal methods transform images into 3D points using depth estimation for modality conversion, which are usually computationally intensive and need expensive labeled data for depth supervision. In this work, we introduce a fast and lightweight framework to encode images and point clouds into place-distinctive descriptors. We propose an effective Field of View (FoV) transformation module to convert point clouds into an analogous modality as images. This module eliminates the necessity for depth estimation and helps subsequent modules achieve real-time performance. We further design a non-negative factorization-based encoder to extract mutually consistent semantic features between point clouds and images. This encoder yields more distinctive global descriptors for retrieval. Experimental results on the KITTI dataset show that our proposed methods achieve state-of-the-art performance while running in real time. Additional evaluation on the HAOMO dataset covering a 17 km trajectory further shows the practical generalization capabilities. We have released the implementation of our methods as open source at: https://github.com/haomo-ai/ModaLink.git.